Es gibt heutzutage zahlreiche Cloud-Anbieter. Sie können klein oder groß sein, lokal oder mit über die ganze Welt verteilten Rechenzentren. Viele dieser Cloud-Anbieter bieten eine Art verwaltete relationale Datenbanklösung an. Die unterstützten Datenbanken sind in der Regel MySQL oder PostgreSQL oder eine andere Variante relationaler Datenbanken.
Beim Entwerfen jeglicher Art von Datenbankinfrastruktur ist es wichtig, Ihre geschäftlichen Anforderungen zu verstehen und zu entscheiden, welche Art von Verfügbarkeit Sie erreichen müssen.
In diesem Blogpost werden wir Hochverfügbarkeitsoptionen für MySQL-basierte Lösungen von einem der größten Cloud-Anbieter – Google Cloud Platform – untersuchen.
Bereitstellen einer hochverfügbaren Umgebung mithilfe einer GCP-SQL-Instanz
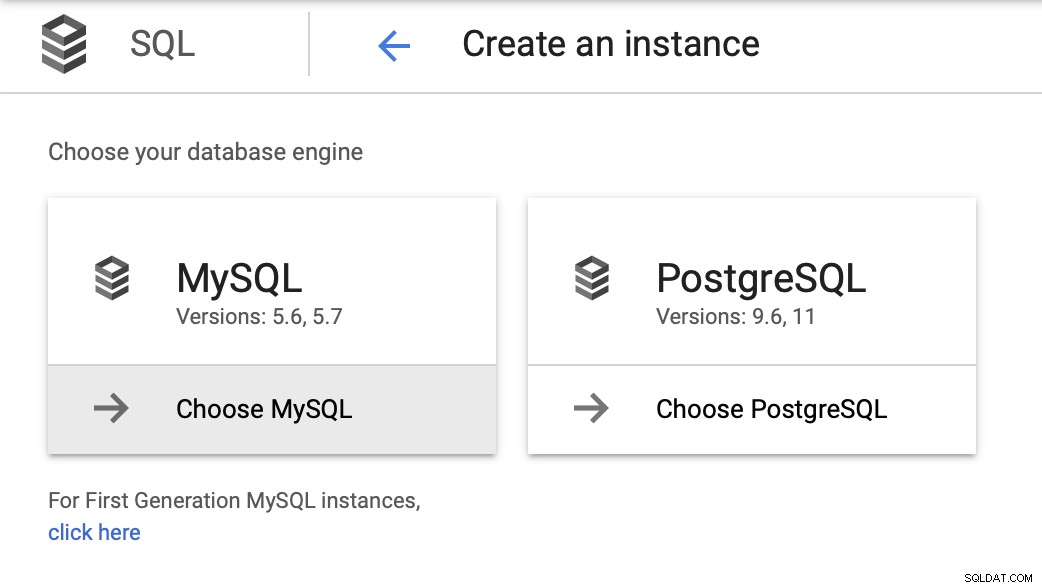
Für diesen Blog wollen wir eine sehr einfache Umgebung - eine Datenbank mit vielleicht ein oder zwei Kopien. Wir möchten in der Lage sein, ein einfaches Failover durchzuführen und den Betrieb so schnell wie möglich wiederherzustellen, wenn der Master ausfällt. Wir verwenden MySQL 5.7 als bevorzugte Version und beginnen mit dem Instanzbereitstellungsassistenten:
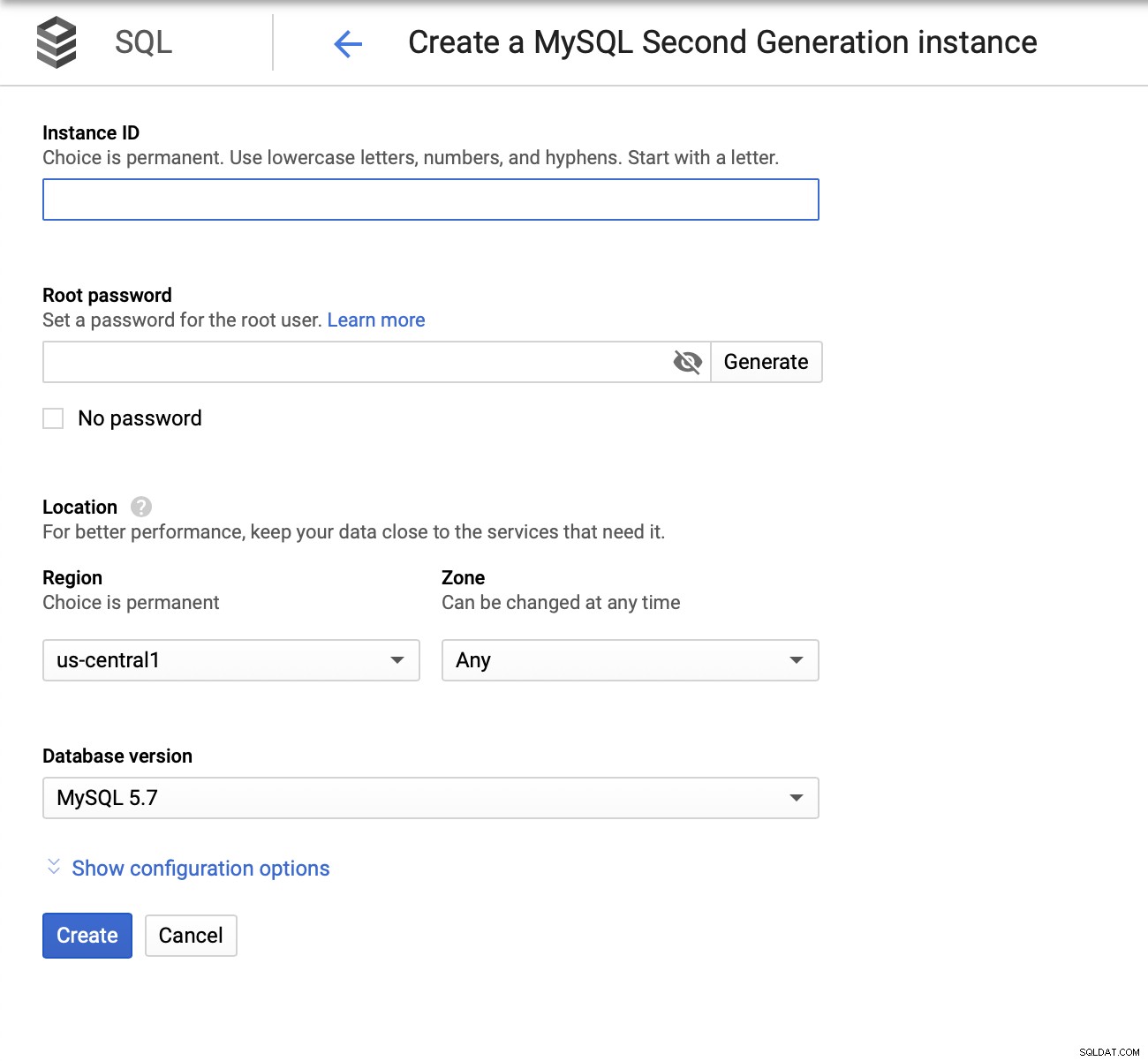
Wir müssen dann das Root-Passwort erstellen, den Instanznamen setzen und Bestimmen Sie, wo es sich befinden soll:
Als Nächstes sehen wir uns die Konfigurationsoptionen an:
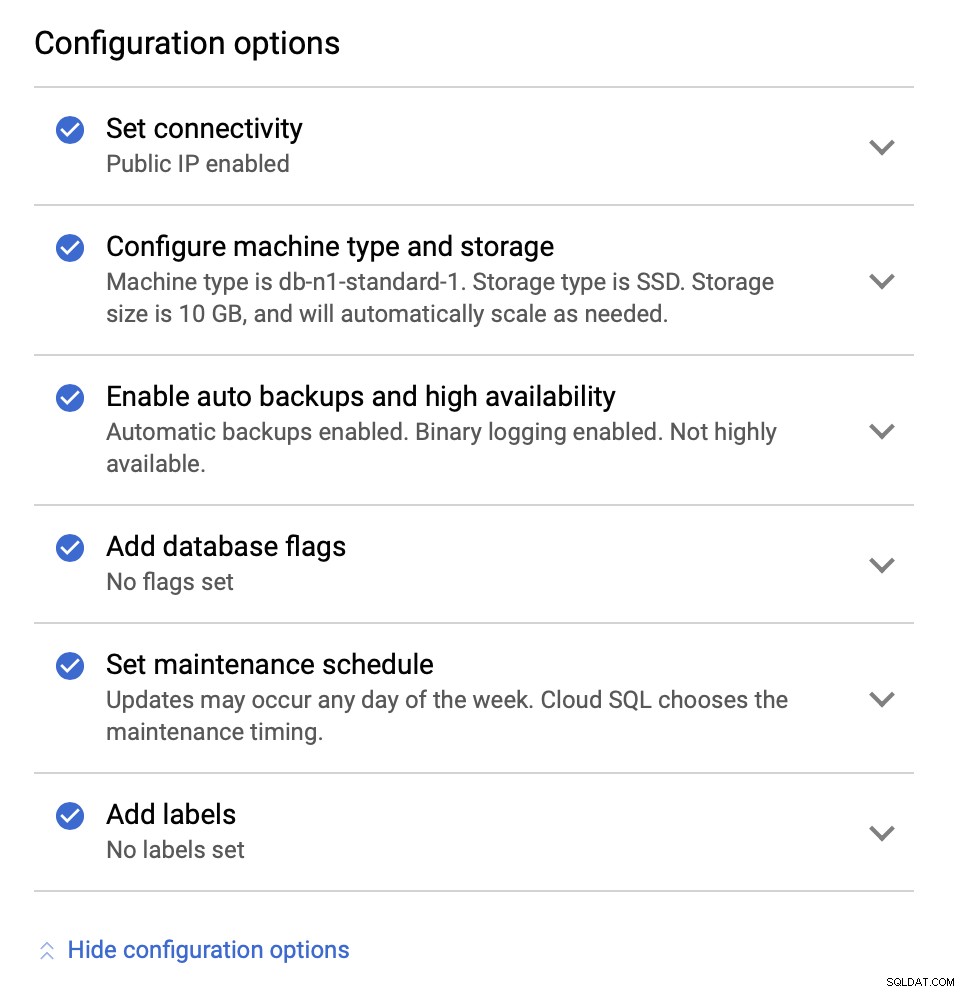
Wir können Änderungen in Bezug auf die Instanzgröße vornehmen (wir werden mit db-n1-standard-4), Speicher- und Wartungsplan. Was uns bei diesem Setup am wichtigsten ist, sind die Hochverfügbarkeitsoptionen:
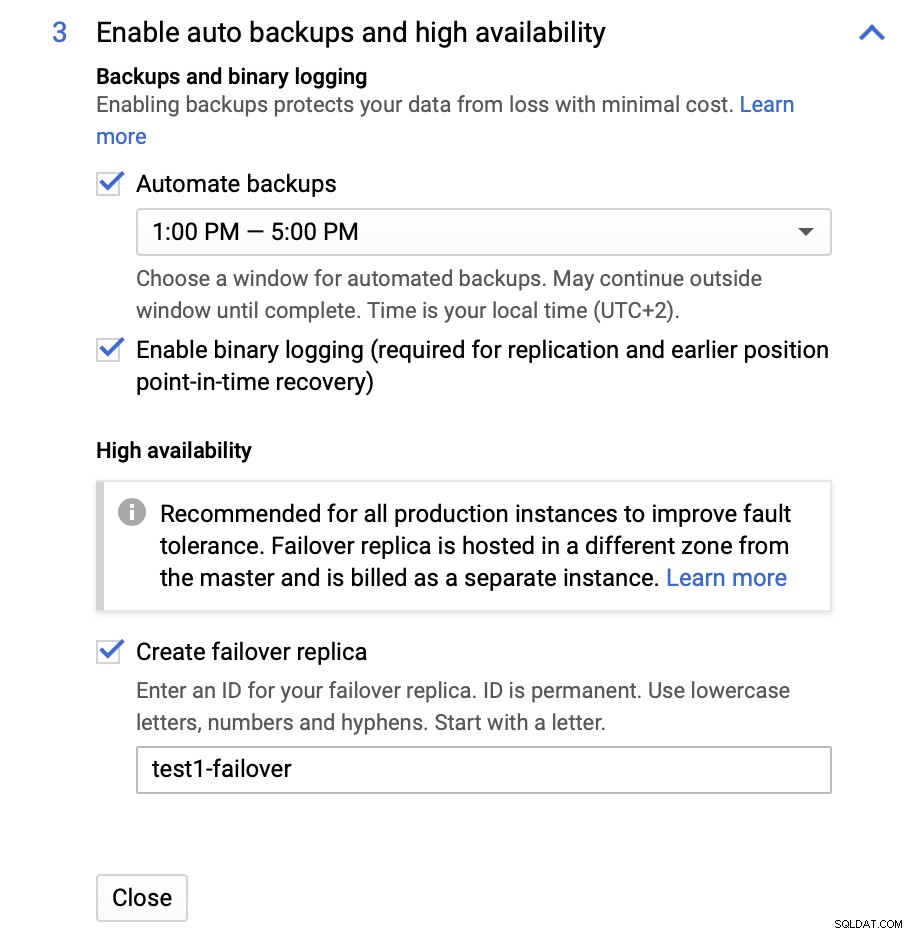
Hier können wir wählen, ob ein Failover-Replikat erstellt werden soll. Dieses Replikat wird zu einem Master hochgestuft, falls der ursprüngliche Master ausfällt.

Nachdem wir das Setup bereitgestellt haben, fügen wir einen Replikations-Slave hinzu:
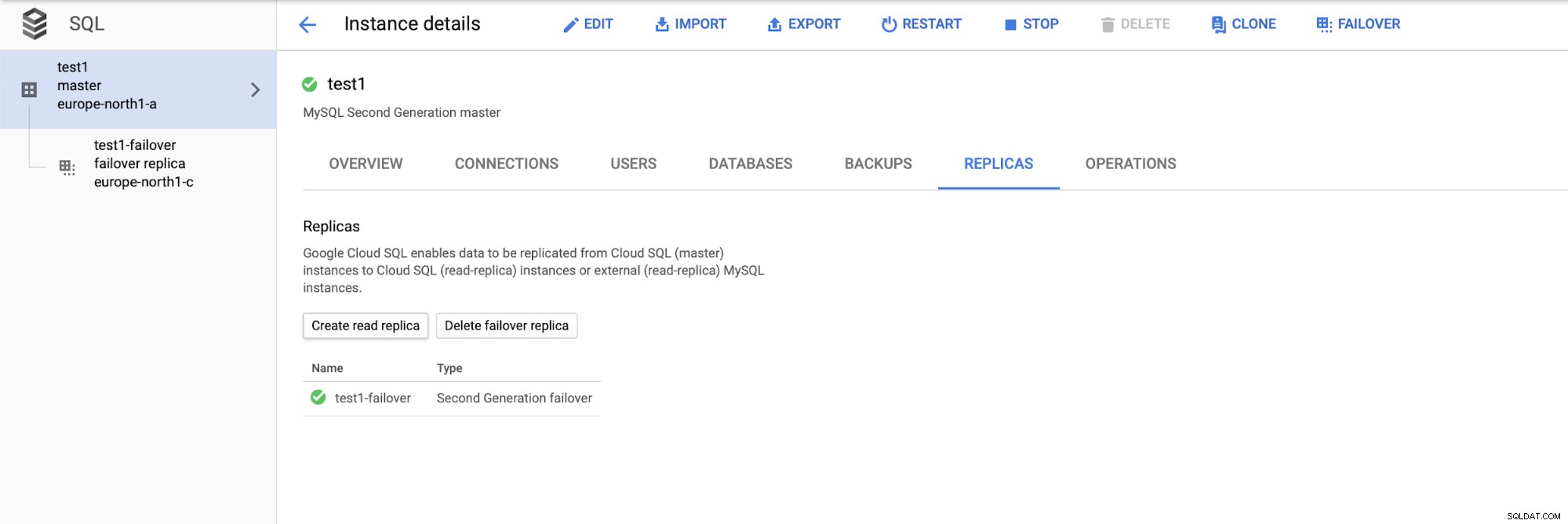
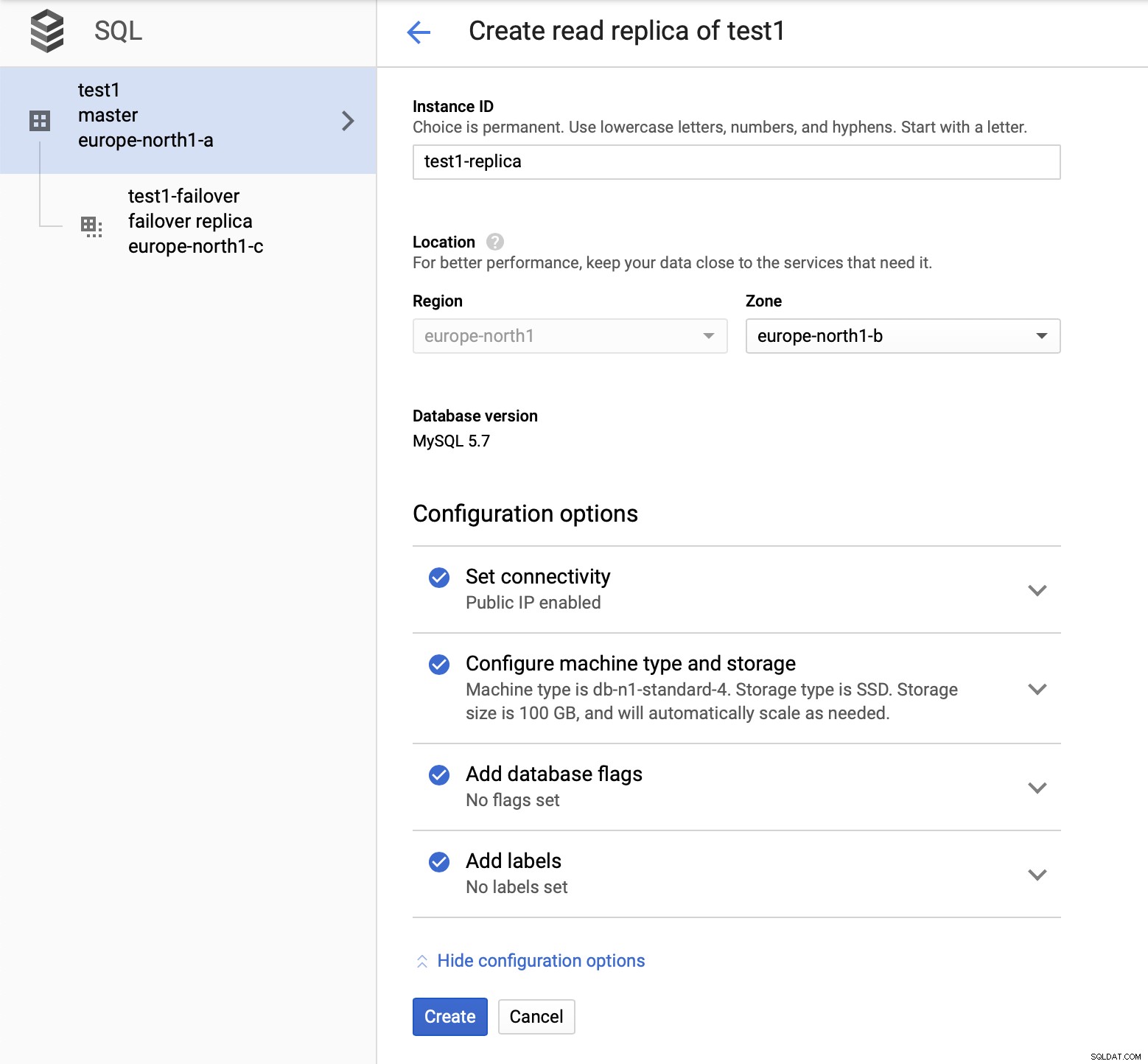
Sobald das Hinzufügen des Replikats abgeschlossen ist, sind wir bereit für einige Prüfungen. Wir werden Test-Workloads mit Sysbench auf unserem Master, Failover-Replikat und Lese-Replikat ausführen, um zu sehen, wie dies funktionieren wird. Wir werden drei Instanzen von Sysbench ausführen und dabei die Endpunkte für alle drei Arten von Knoten verwenden.
Dann lösen wir das manuelle Failover über die Benutzeroberfläche aus:
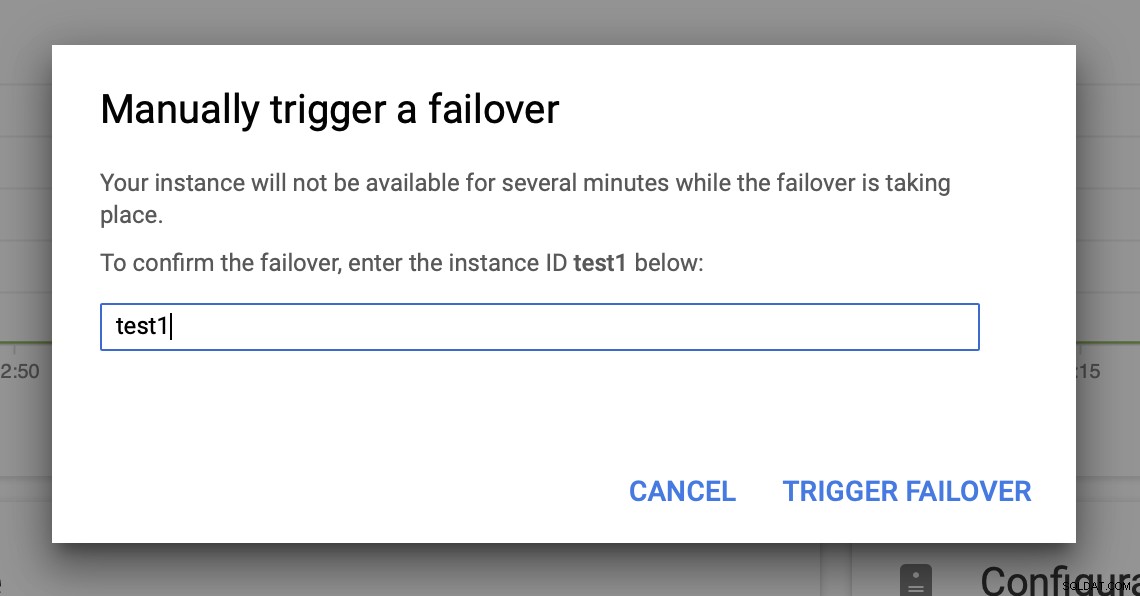
Testen Sie MySQL-Failover auf der Google Cloud Platform?
Ich bin bis zu diesem Punkt gekommen, ohne detaillierte Kenntnisse darüber zu haben, wie die SQL-Knoten in der GCP funktionieren. Ich hatte jedoch einige Erwartungen, basierend auf früheren MySQL-Erfahrungen und dem, was ich bei anderen Cloud-Anbietern gesehen habe. Für den Anfang sollte das Failover zum Failover-Knoten sehr schnell sein. Was wir möchten, ist, die Replikations-Slaves verfügbar zu halten, ohne dass ein Rebuild erforderlich ist. Wir würden auch gerne sehen, wie schnell wir das Failover ein zweites Mal ausführen können (da es nicht ungewöhnlich ist, dass sich das Problem von einer Datenbank zur anderen ausbreitet).
Was wir bei unseren Tests festgestellt haben...
- Während des Failovers war der Master nach 75–80 Sekunden wieder verfügbar.
- Failover-Replikat war 5–6 Minuten lang nicht verfügbar.
- Lesereplikat war während des Failover-Vorgangs verfügbar, aber es war 55–60 Sekunden lang nicht verfügbar, nachdem das Failover-Replikat verfügbar wurde
Worüber wir uns nicht sicher sind...
Was passiert, wenn das Failover-Replikat nicht verfügbar ist? Basierend auf der Zeit sieht es so aus, als würde das Failover-Replikat neu erstellt. Das ist sinnvoll, aber dann hängt die Wiederherstellungszeit stark von der Größe der Instanz (insbesondere der E/A-Leistung) und der Größe der Datendatei ab.
Was passiert mit der Read Replica, nachdem die Failover-Replik neu erstellt wurde? Ursprünglich war das Lesereplikat mit dem Master verbunden. Wenn der Master fehlschlug, würden wir erwarten, dass das Lesereplikat eine veraltete Ansicht des Datensatzes bereitstellt. Sobald der neue Master angezeigt wird, sollte er sich per Replikation wieder mit der Instanz verbinden (die früher ein Failover-Replikat war und zum Master hochgestuft wurde). Es ist keine Minute Ausfallzeit erforderlich, wenn CHANGE MASTER ausgeführt wird.
Noch wichtiger ist, dass es während des Failover-Prozesses keine Möglichkeit gibt, ein weiteres Failover auszuführen (was irgendwie Sinn macht):
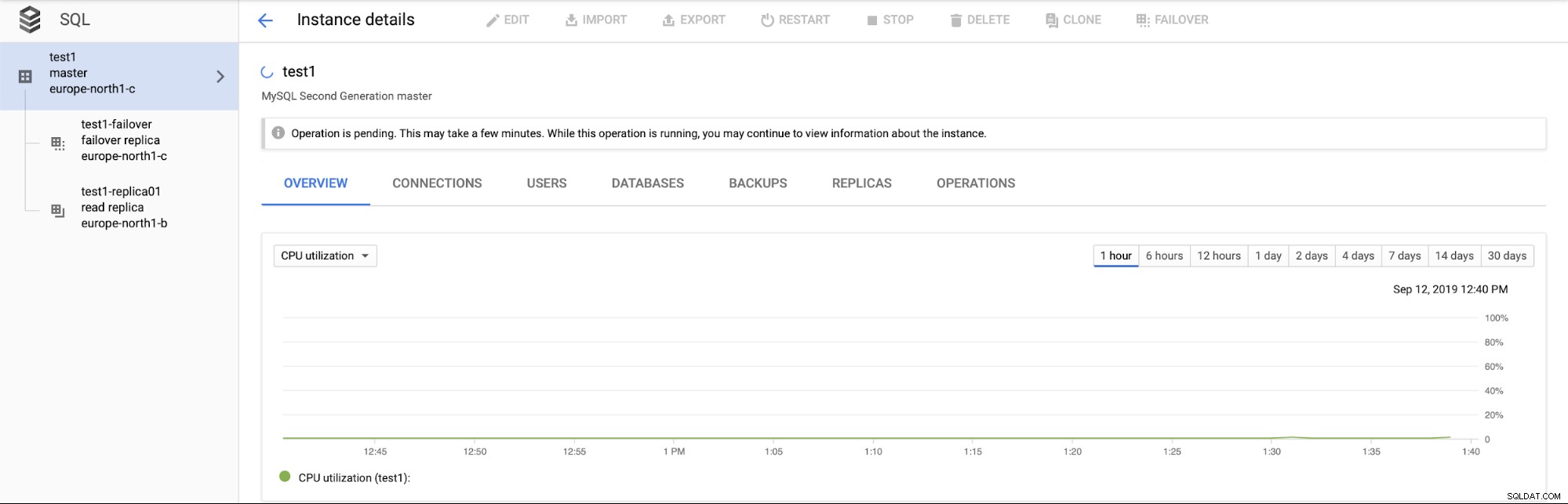
Es ist auch nicht möglich, Lesereplikate zu fördern (was nicht unbedingt sinnvoll ist - Wir gehen davon aus, dass wir Read Replicas jederzeit bewerben können).

Es ist wichtig zu beachten, dass Sie sich auf die Read Replicas verlassen müssen, um eine hohe Verfügbarkeit bereitzustellen (ohne ein Failover-Replikat zu erstellen) ist keine praktikable Lösung. Sie können ein Lesereplikat zu einem Master hochstufen, es würde jedoch ein neuer Cluster erstellt; vom Rest der Knoten getrennt.
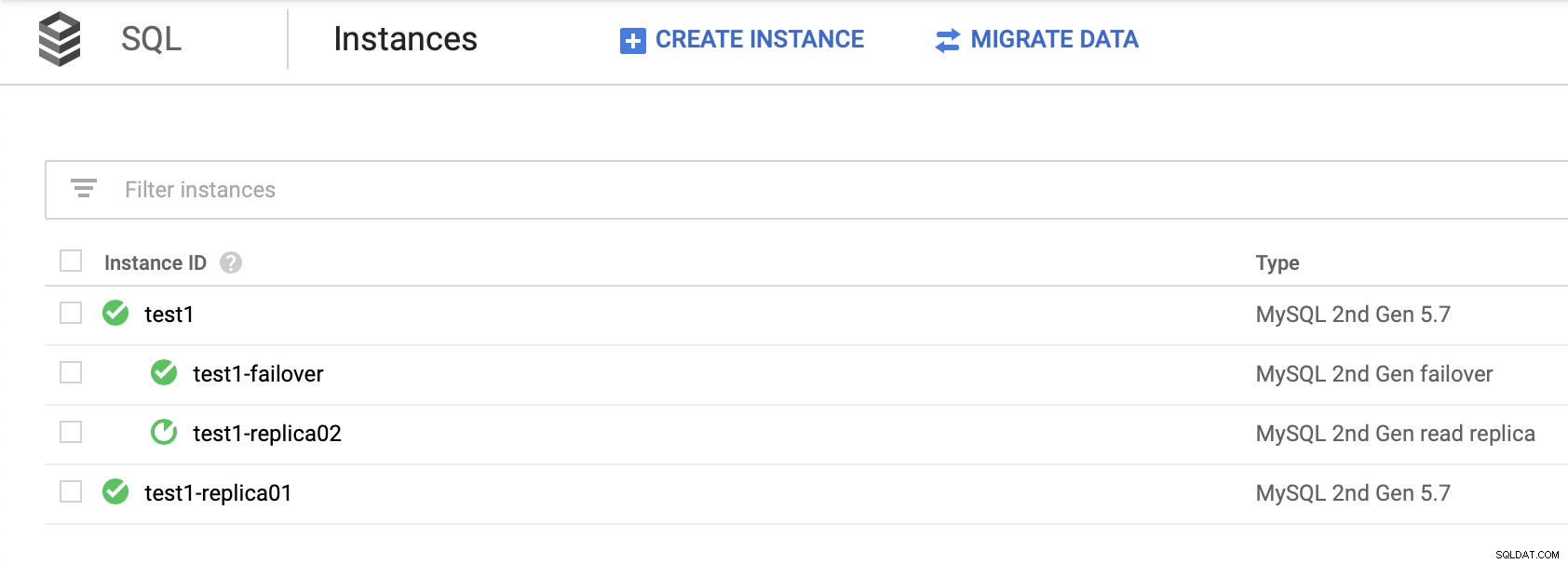
Es gibt keine Möglichkeit, Ihre anderen Replikate aus dem neuen Cluster herauszulösen. Die einzige Möglichkeit, dies zu tun, wäre, neue Replikate zu erstellen, aber dies ist ein zeitaufwändiger Prozess. Es ist auch praktisch nicht verwendbar, wodurch das Failover-Replikat die einzige wirkliche Option für Hochverfügbarkeit für SQL-Knoten in der Google Cloud Platform ist.
Fazit
Während es möglich ist, eine hochverfügbare Umgebung für SQL-Knoten in der GCP zu erstellen, wird der Master für etwa anderthalb Minuten nicht verfügbar sein. Der gesamte Vorgang (einschließlich der Neuerstellung des Failover-Replikats und einiger Aktionen an den Lesereplikaten) dauerte mehrere Minuten. Während dieser Zeit konnten wir weder ein zusätzliches Failover auslösen, noch konnten wir eine Read Replica fördern.
Gibt es GCP-Nutzer da draußen? Wie erreichen Sie Hochverfügbarkeit?