Jedes profitable Unternehmen benötigt eine hohe Verfügbarkeit. Bei Websites und Blogs ist das nicht anders, da selbst kleinere Unternehmen und Einzelpersonen verlangen, dass ihre Websites online bleiben, um ihren Ruf zu wahren.
WordPress ist bei weitem das beliebteste CMS der Welt, das Millionen von Websites von klein bis groß unterstützt. Aber wie können Sie sicherstellen, dass Ihre Website live bleibt? Genauer gesagt, wie kann ich sicherstellen, dass die Nichtverfügbarkeit meiner Datenbank keine Auswirkungen auf meine Website hat?
In diesem Blogbeitrag zeigen wir, wie Sie mit ClusterControl ein Failover für Ihre WordPress-Website erreichen.
Das Setup, das wir für diesen Blog verwenden werden, verwendet Percona Server 5.7. Wir werden einen weiteren Host haben, der die Apache- und Wordpress-Anwendung enthält. Wir werden den Teil der Hochverfügbarkeit der Anwendung nicht anfassen, aber das sollten Sie auch unbedingt haben. Wir werden ClusterControl verwenden, um Datenbanken zu verwalten, um die Verfügbarkeit sicherzustellen, und wir werden einen dritten Host verwenden, um ClusterControl selbst zu installieren und einzurichten.
Angenommen, das ClusterControl läuft und läuft, müssen wir unsere bestehende Datenbank hinein importieren.
Importieren eines Datenbank-Clusters mit ClusterControl
Gehen Sie im Bereitstellungsassistenten zur Option „Vorhandenen Server/Datenbank importieren“.
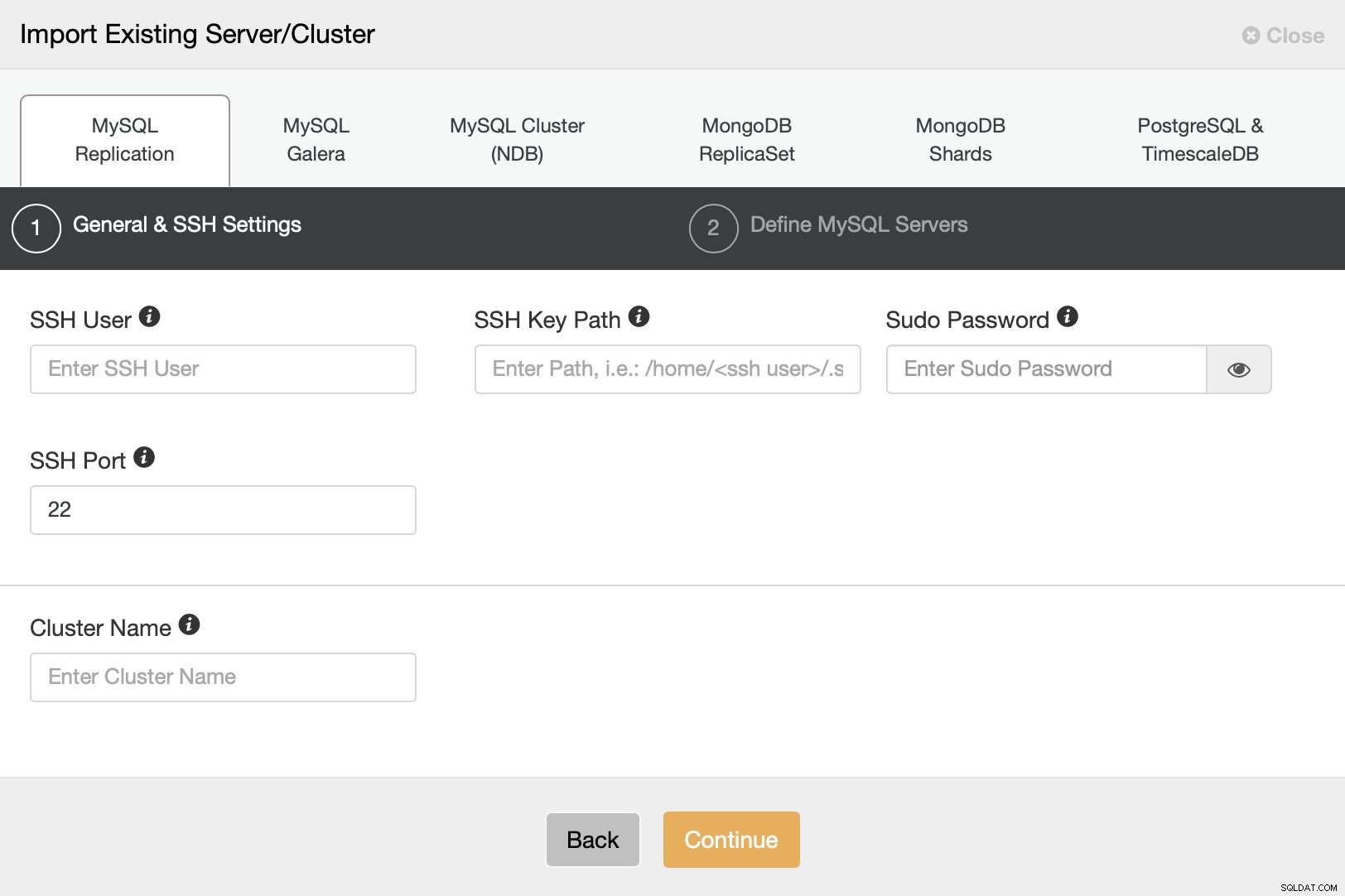
Wir müssen die SSH-Konnektivität konfigurieren, da dies eine Voraussetzung für ClusterControl ist in der Lage sein, die Knoten zu verwalten.
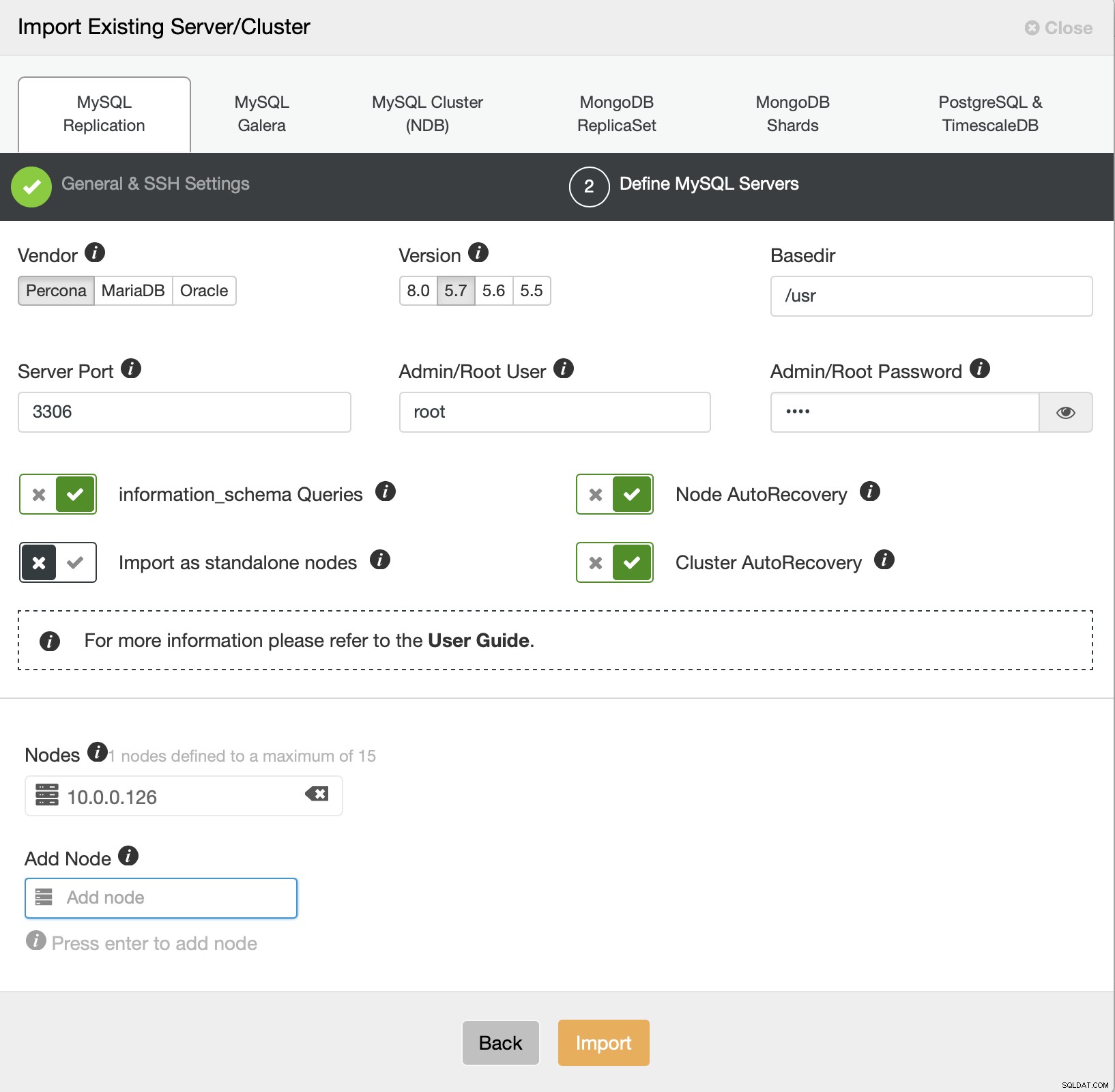
Wir müssen jetzt einige Details über Hersteller, Version und Root-Benutzer definieren Zugriff, den Knoten selbst und ob wir möchten, dass ClusterControl die automatische Wiederherstellung für uns verwaltet oder nicht. Das ist alles, sobald der Auftrag erfolgreich war, wird Ihnen ein Cluster auf der Liste angezeigt.
Um die hochverfügbare Umgebung einzurichten, müssen wir ein paar ausführen von Aktionen. Unsere Umgebung besteht aus...
- Master-Slave-Paar
- Zwei ProxySQL-Instanzen für Lese-/Schreibaufteilung und Topologieerkennung
- Zwei Keepalived-Instanzen für die virtuelle IP-Verwaltung
Die Idee ist einfach – wir werden den Slave unserem Master bereitstellen, damit wir eine zweite Instanz haben, auf die wir umschalten können, falls der Master ausfällt. ClusterControl ist für die Fehlererkennung verantwortlich und befördert den Slave, wenn der Master nicht verfügbar ist. ProxySQL verfolgt die Replikationstopologie und leitet den Datenverkehr an den richtigen Knoten um - Schreibvorgänge werden an den Master gesendet, egal in welchem Knoten sie sich befinden, Lesevorgänge können entweder nur an den Master gesendet oder auf Master und Slaves verteilt werden . Schließlich wird Keepalived mit ProxySQL verbunden und stellt VIP bereit, mit dem sich die Anwendung verbinden kann. Diese VIP wird immer einer der ProxySQL-Instanzen zugewiesen und Keepalived verschiebt sie auf die zweite, sollte der „Haupt“-ProxySQL-Knoten ausfallen.
Nachdem das alles gesagt ist, konfigurieren wir dies mit ClusterControl. All dies kann mit nur wenigen Klicks erledigt werden. Wir beginnen mit dem Hinzufügen des Slaves.
Hinzufügen eines Datenbank-Slaves mit ClusterControl

Wir beginnen mit der Auswahl des Jobs „Add Replication Slave“. Dann werden wir gebeten, ein Formular auszufüllen:
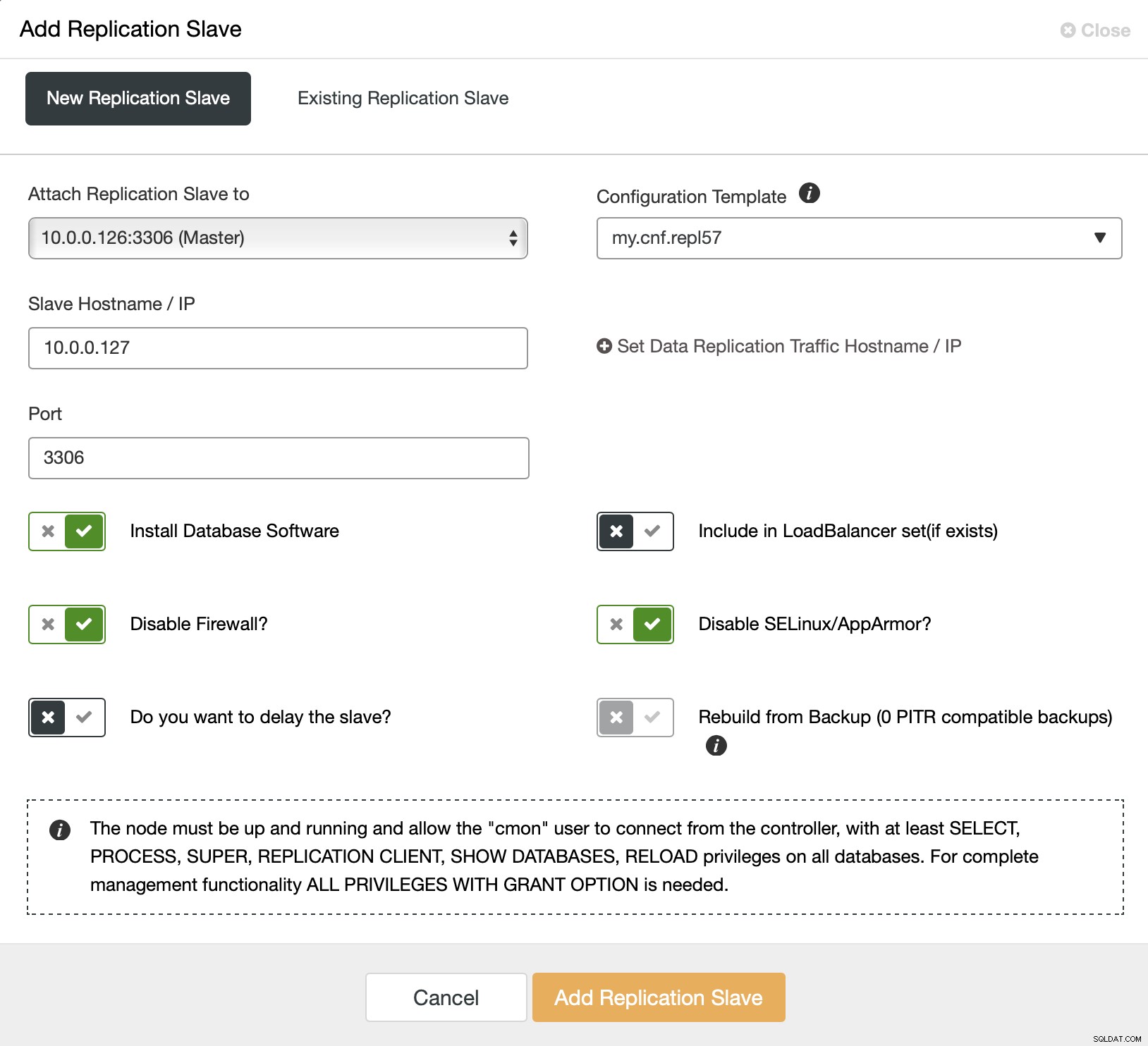
Wir müssen den Master auswählen (in unserem Fall nicht wirklich viele Optionen haben), müssen wir die IP oder den Hostnamen für den neuen Slave übergeben. Wenn wir zuvor Backups erstellt hätten, könnten wir eines davon verwenden, um den Slave bereitzustellen. In unserem Fall ist diese nicht verfügbar und ClusterControl stellt den Slave direkt vom Master bereit. Das ist alles, der Job wird gestartet und ClusterControl führt die erforderlichen Aktionen aus. Sie können den Fortschritt auf der Registerkarte "Aktivität" überwachen.

Schließlich sollte der Slave auf dem sichtbar sein, sobald der Job erfolgreich abgeschlossen wurde Clusterliste.

Nun fahren wir mit der Konfiguration der ProxySQL-Instanzen fort. In unserem Fall ist die Umgebung minimal, sodass wir der Einfachheit halber ProxySQL auf einem der Datenbankknoten platzieren. Dies ist jedoch nicht die beste Option in einer realen Produktionsumgebung. Idealerweise befindet sich ProxySQL entweder auf einem separaten Knoten oder zusammen mit den anderen Anwendungshosts.
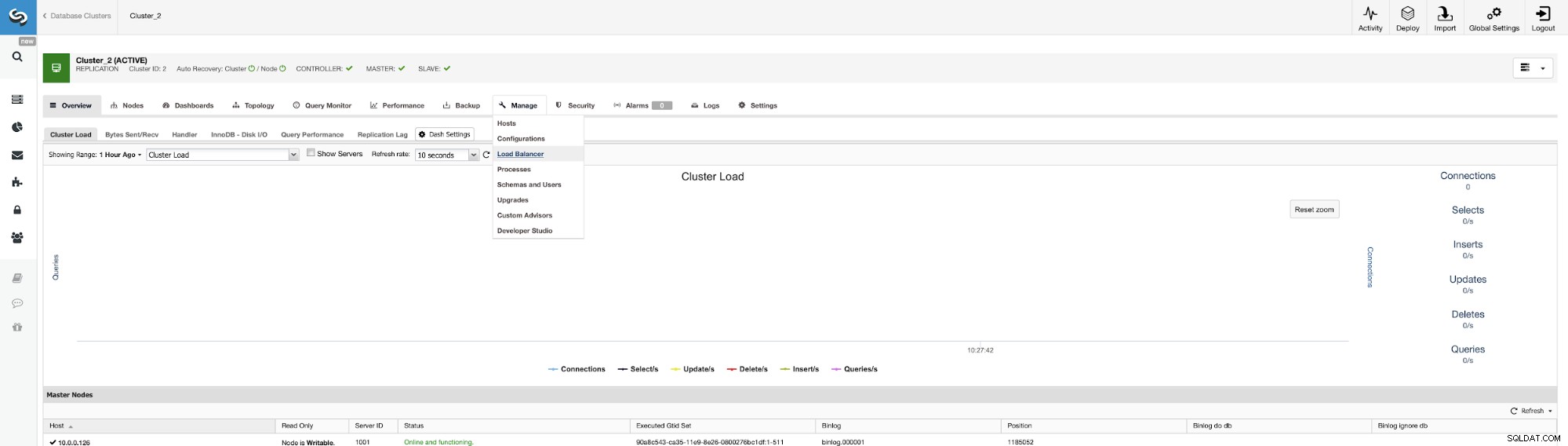
Der Ort, an dem Sie den Job starten können, ist Manage -> Loadbalancers.
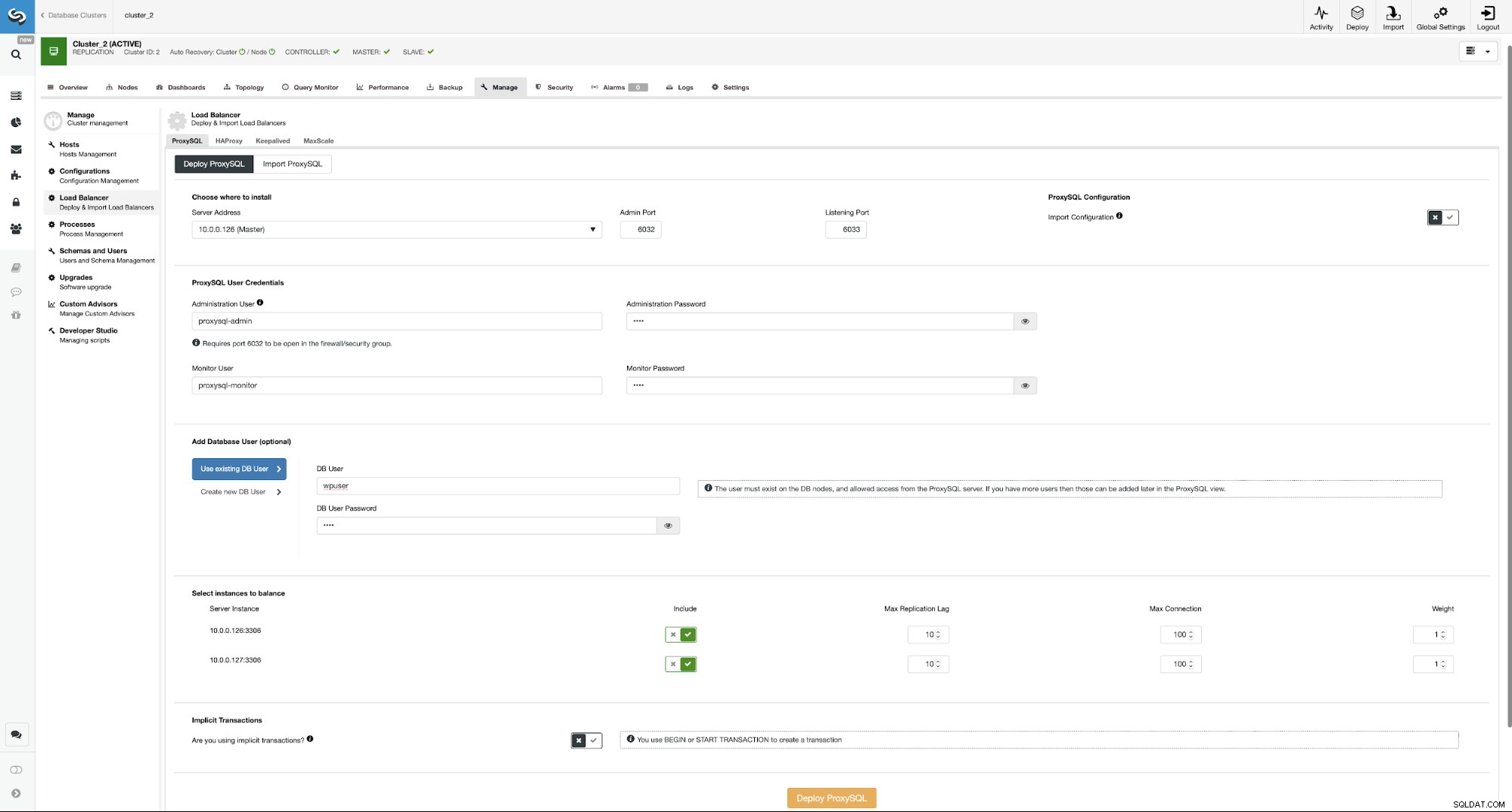
Hier müssen Sie auswählen, wo ProxySQL installiert werden soll, und administrative Anmeldeinformationen übergeben , und fügen Sie einen Datenbankbenutzer hinzu. In unserem Fall verwenden wir unseren vorhandenen Benutzer, da unsere WordPress-Anwendung ihn bereits für die Verbindung zur Datenbank verwendet. Wir müssen dann auswählen, welche Knoten in ProxySQL verwendet werden sollen (wir wollen hier sowohl Master als auch Slave) und ClusterControl mitteilen, ob wir explizite Transaktionen verwenden oder nicht. Dies ist in unserem Fall nicht wirklich relevant, da wir ProxySQL neu konfigurieren werden, sobald es bereitgestellt wird. Wenn Sie diese Option aktiviert haben, wird die Lese-/Schreibaufteilung nicht aktiviert. Andernfalls konfiguriert ClusterControl ProxySQL für die Lese-/Schreibaufteilung. In unserem minimalen Setup sollten wir ernsthaft darüber nachdenken, ob wir wollen, dass die Lese-/Schreib-Aufteilung stattfindet. Lassen Sie uns das analysieren.
Die Vor- und Nachteile von Read/Write Spit in ProxySQL
Der Hauptvorteil der Verwendung der Lese-/Schreibaufteilung besteht darin, dass der gesamte SELECT-Verkehr zwischen dem Master und dem Slave verteilt wird. Dies bedeutet, dass die Last auf den Knoten geringer sein wird und die Antwortzeit sollte ebenfalls geringer sein. Das hört sich gut an, aber denken Sie daran, dass bei Ausfall eines Knotens der andere Knoten in der Lage sein muss, den gesamten Datenverkehr aufzunehmen. Ein automatisiertes Failover macht wenig Sinn, wenn der Ausfall eines Knotens dazu führt, dass der zweite Knoten überlastet und de facto auch nicht verfügbar ist.
Es kann sinnvoll sein, die Last zu verteilen, wenn Sie mehrere Slaves haben - der Verlust eines Knotens von fünf hat weniger Auswirkungen als der Verlust von einem von zwei. Ganz gleich, wofür Sie sich entscheiden, Sie können das Verhalten einfach ändern, indem Sie zum ProxySQL-Knoten gehen und auf die Registerkarte Regeln klicken.
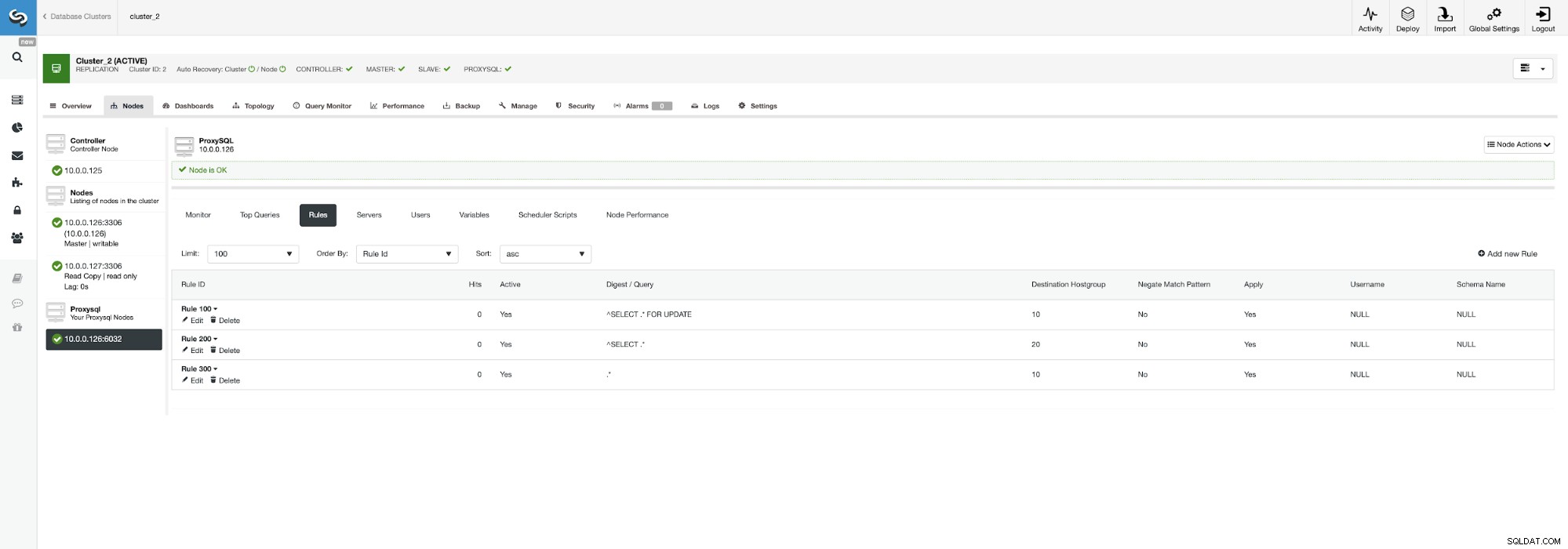
Sehen Sie sich Regel 200 an (diejenige, die alle SELECT-Anweisungen abfängt ). Auf dem Screenshot unten sehen Sie, dass die Zielhostgruppe 20 ist, was bedeutet, dass alle Knoten im Cluster – Lese-/Schreibaufteilung und Scale-out aktiviert sind. Wir können dies einfach deaktivieren, indem wir diese Regel bearbeiten und die Ziel-Hostgruppe auf 10 ändern (diejenige, die Master enthält).
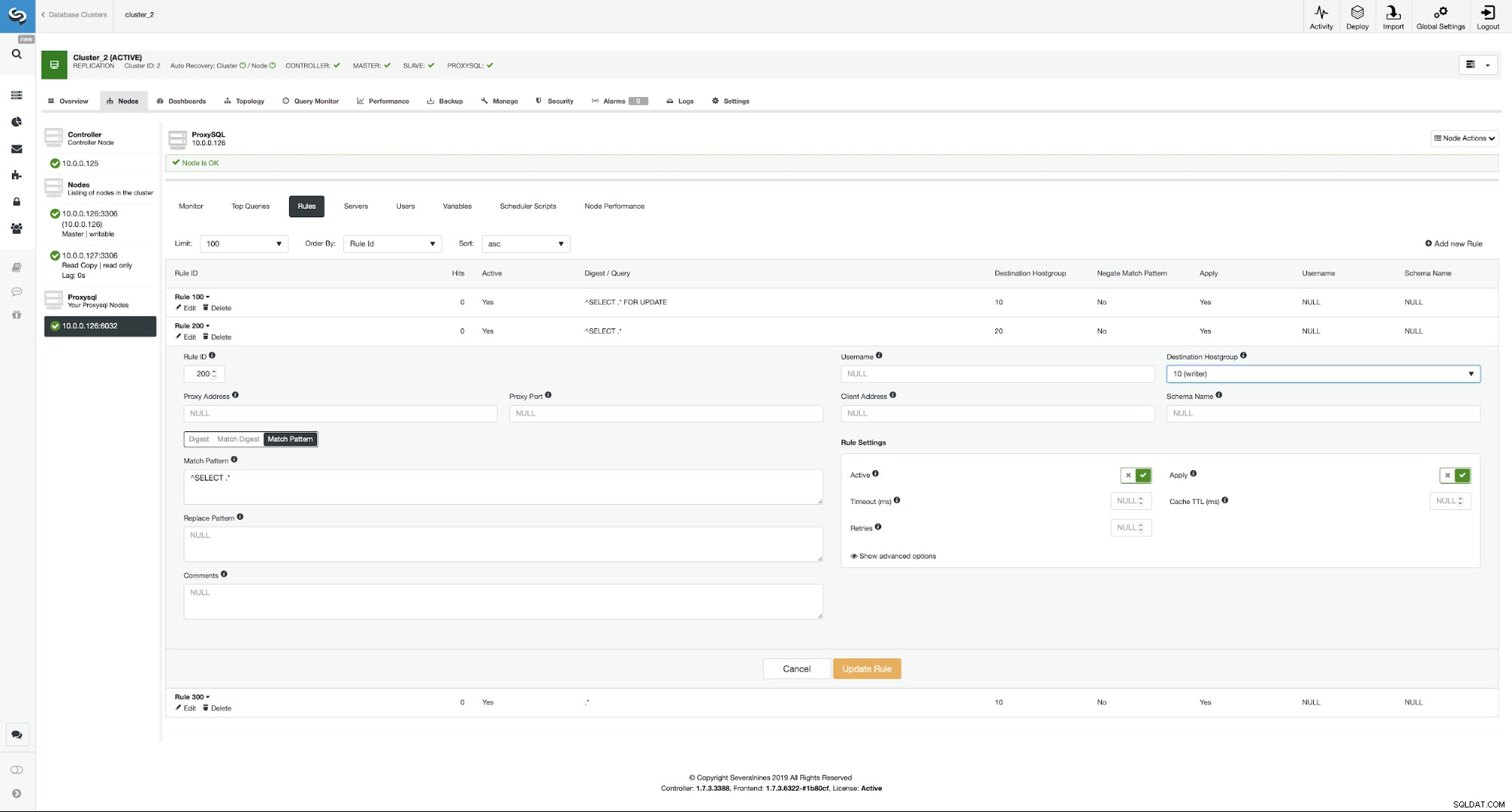
Wenn Sie die Lese-/Schreibaufteilung aktivieren möchten, können Sie das ganz einfach tun Tun Sie dies, indem Sie diese Abfrageregel erneut bearbeiten und die Ziel-Hostgruppe auf 20 zurücksetzen.
Lassen Sie uns jetzt den zweiten ProxySQL bereitstellen.
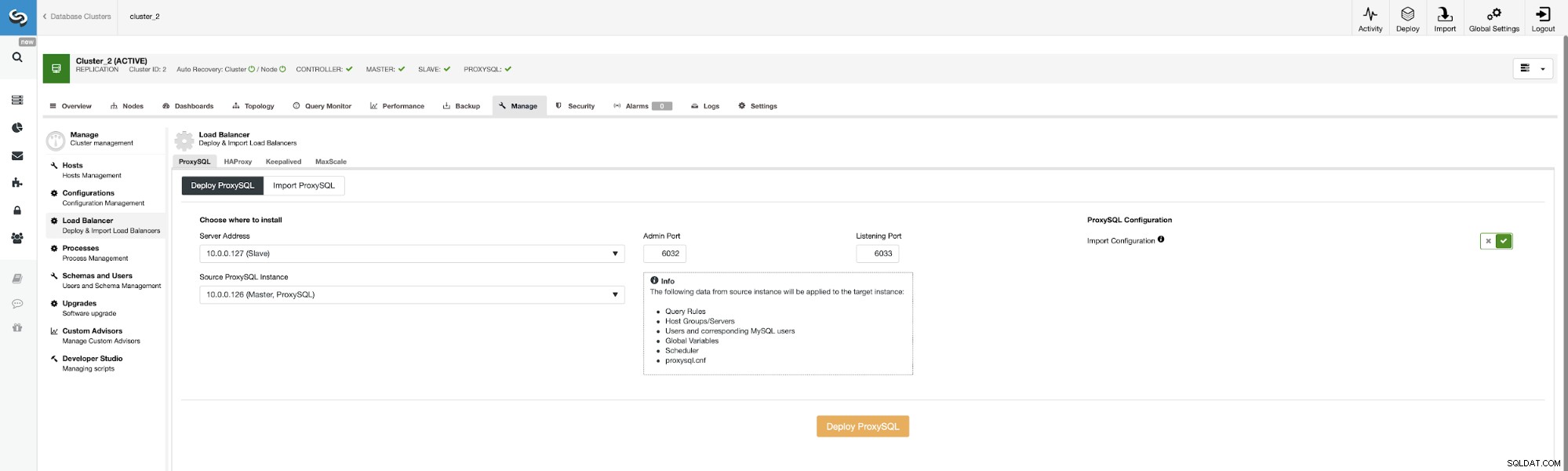
Um zu vermeiden, dass alle Konfigurationsoptionen erneut übergeben werden, können wir die Datei „Import Configuration ” Option und wählen Sie unser vorhandenes ProxySQL als Quelle aus.
Wenn dieser Job abgeschlossen ist, müssen wir noch den letzten Schritt zur Einrichtung unserer Umgebung durchführen. Wir müssen Keepalived zusätzlich zu den ProxySQL-Instanzen bereitstellen.
Bereitstellen von Keepalived auf ProxySQL-Instanzen
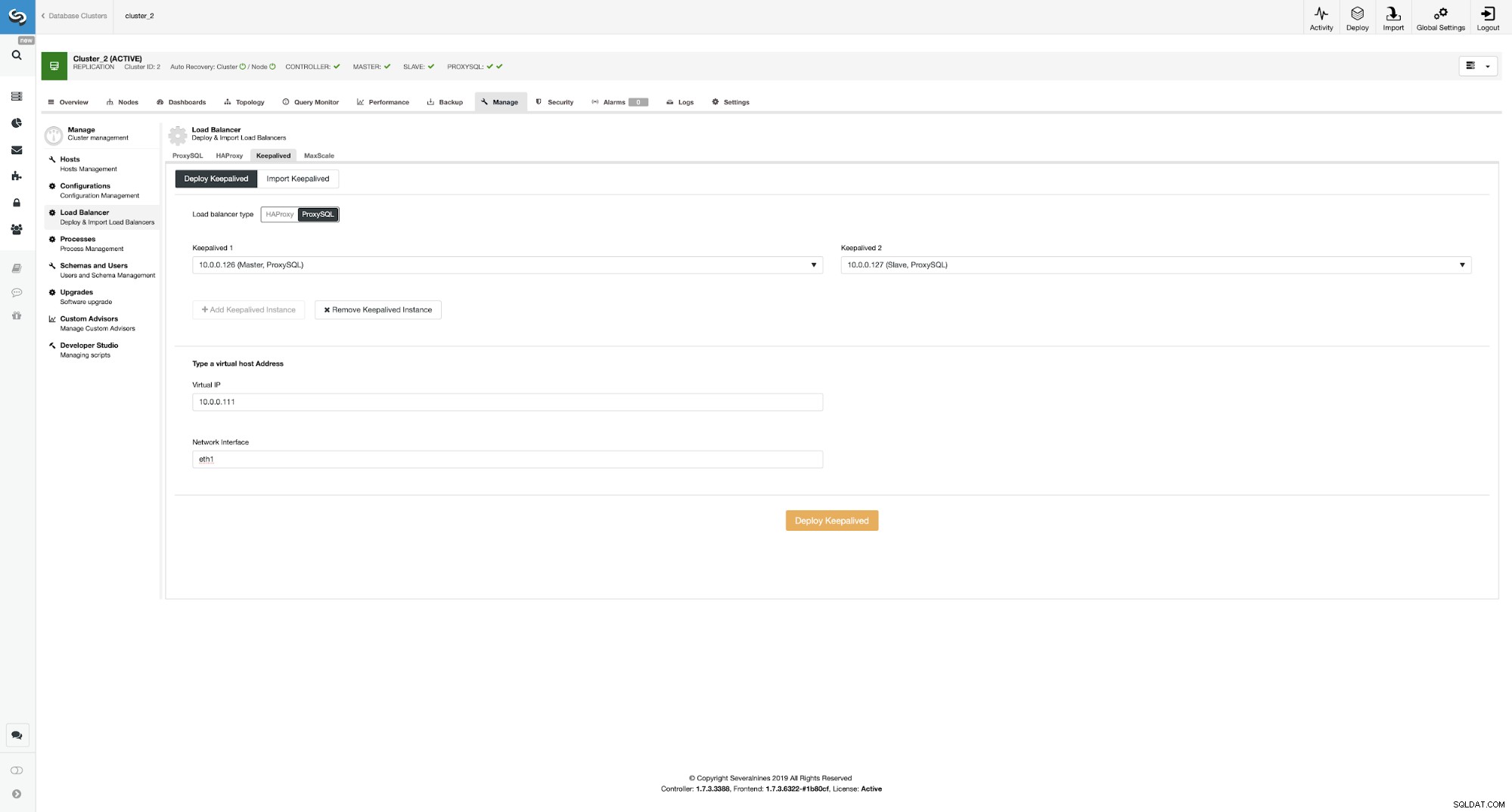
Hier haben wir ProxySQL als Load Balancer-Typ ausgewählt und beide ProxySQL-Instanzen übergeben Keepalived wird auf installiert und wir haben unsere VIP- und Netzwerkschnittstelle eingegeben.
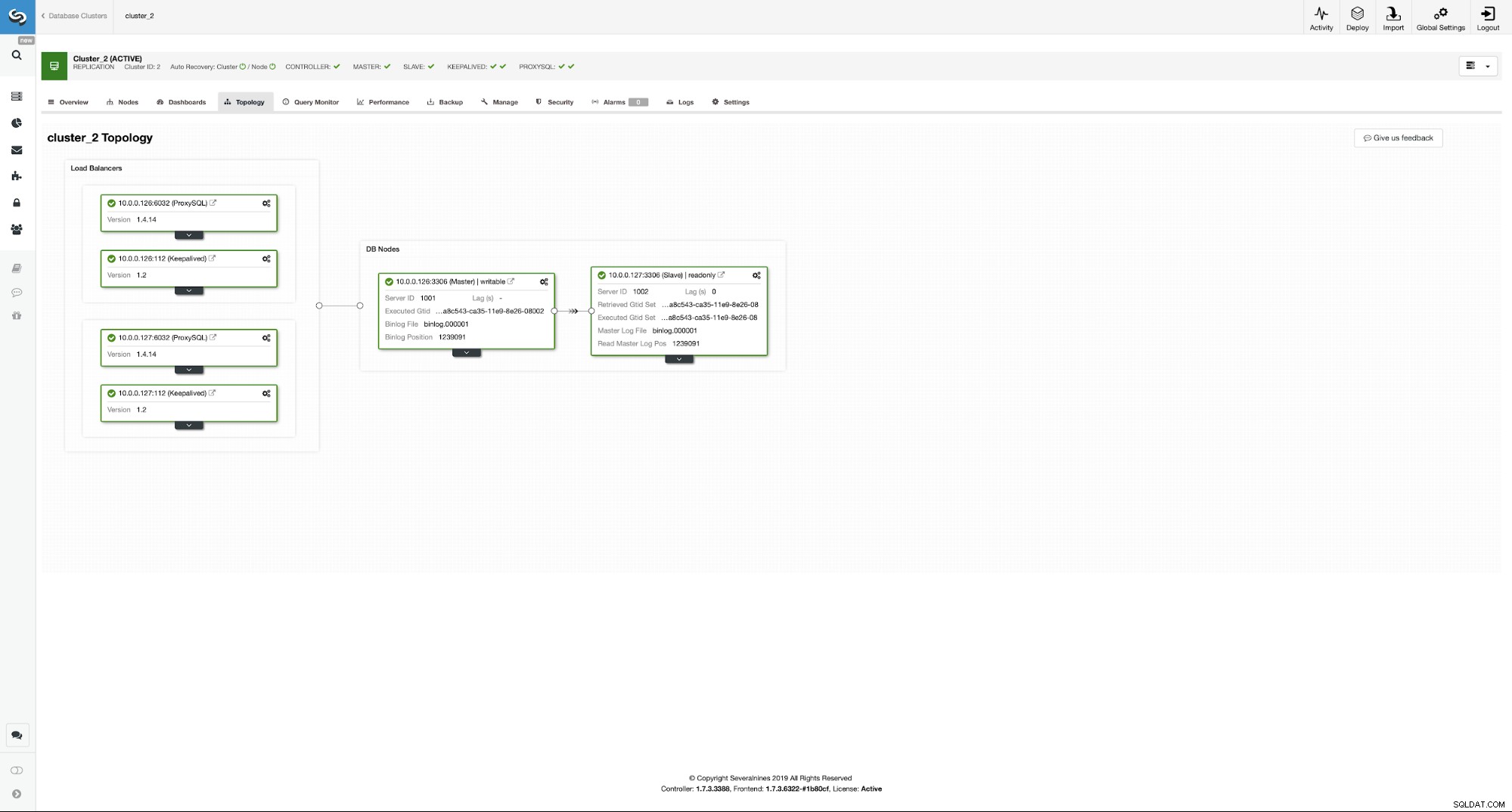
Wie Sie sehen können, haben wir jetzt das gesamte Setup eingerichtet und sind bereit. Wir haben eine VIP von 10.0.0.111, die einer der ProxySQL-Instanzen zugewiesen ist. ProxySQL-Instanzen leiten unseren Datenverkehr an die richtigen Backend-MySQL-Knoten weiter, und ClusterControl behält die Umgebung im Auge und führt bei Bedarf ein Failover durch. Als letzte Aktion müssen wir Wordpress neu konfigurieren, um die virtuelle IP für die Verbindung zur Datenbank zu verwenden.
Dazu müssen wir die wp-config.php bearbeiten und die Variable DB_HOST auf unsere virtuelle IP ändern:
/** MySQL hostname */
define( 'DB_HOST', '10.0.0.111' );Fazit
Von nun an verbindet sich Wordpress über VIP und ProxySQL mit der Datenbank. Falls der Master-Knoten ausfällt, führt ClusterControl das Failover durch.
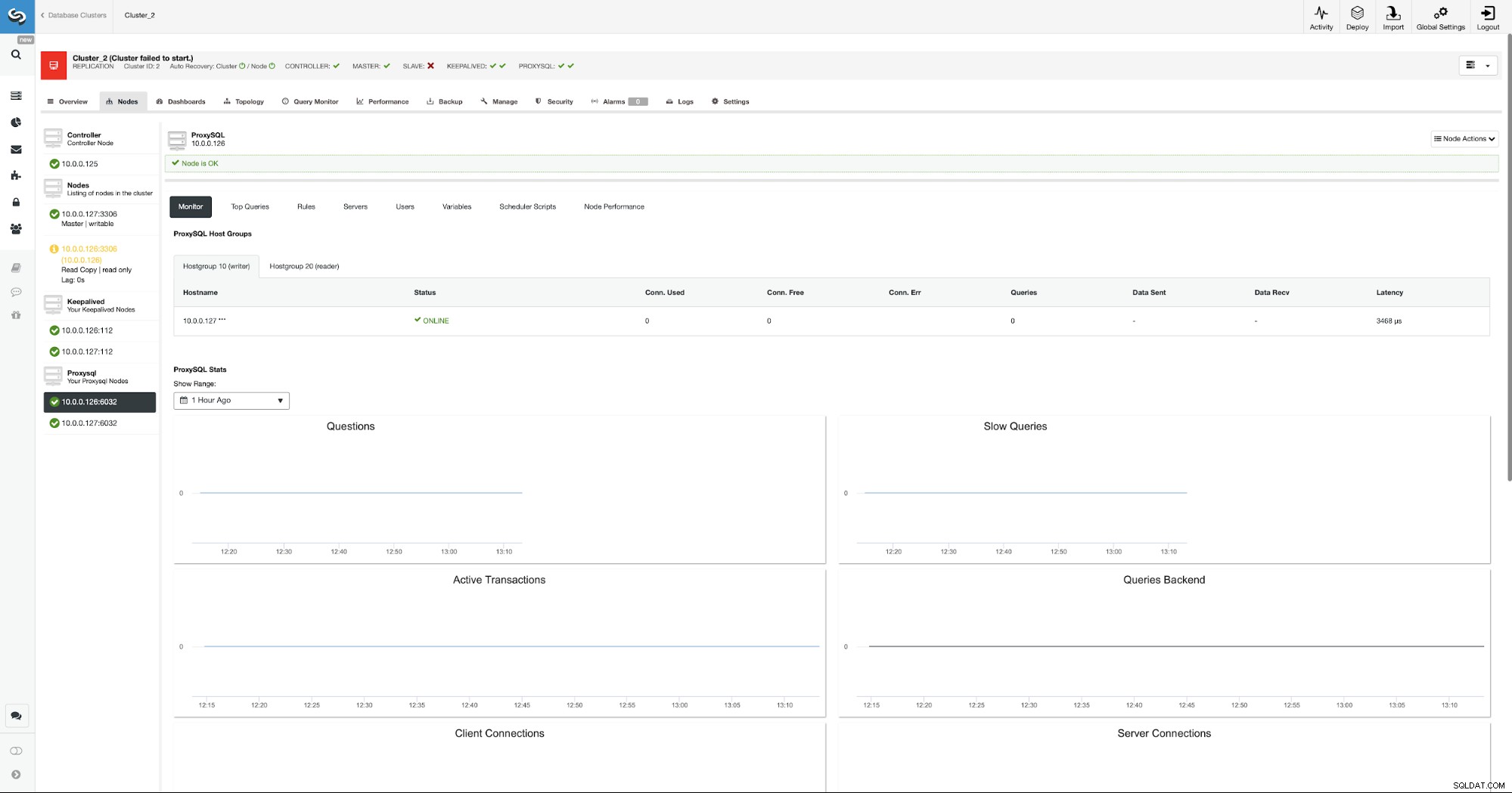
Wie Sie sehen können, wurde ein neuer Master gewählt und ProxySQL weist ebenfalls darauf hin neuer Meister in der Hostgruppe 10.
Wir hoffen, dass dieser Blogbeitrag Ihnen eine Vorstellung davon gibt, wie Sie eine hochverfügbare Datenbankumgebung für eine Wordpress-Website entwerfen und wie ClusterControl verwendet werden kann, um alle ihre Elemente bereitzustellen.