Sie alle haben schon von Skalierung gehört - Ihre Architektur sollte skalierbar sein, Sie sollten in der Lage sein, die Anforderungen zu erfüllen, und so weiter und so weiter. Was bedeutet es, wenn wir von Datenbanken sprechen? Wie sieht die Skalierung hinter den Kulissen aus? Dieses Thema ist umfangreich und es gibt keine Möglichkeit, alle Aspekte abzudecken. Diese aus zwei Blogposts bestehende Serie ist ein Versuch, Ihnen einen Einblick in das Thema Datenbankskalierbarkeit zu geben.
Warum skalieren wir?
Lassen Sie uns zuerst einen Blick darauf werfen, worum es bei der Skalierbarkeit geht. Kurz gesagt sprechen wir über die Fähigkeit, eine höhere Last Ihrer Datenbanksysteme zu bewältigen. Es kann eine Frage des Umgangs mit kurzlebigen Aktivitätsspitzen sein, es kann eine Frage der Bewältigung einer allmählich zunehmenden Arbeitslast in Ihrer Datenbankumgebung sein. Es kann zahlreiche Gründe geben, eine Skalierung in Erwägung zu ziehen. Die meisten von ihnen bringen ihre eigenen Herausforderungen mit sich. Wir können einige Zeit damit verbringen, Beispiele für Situationen durchzugehen, in denen wir möglicherweise aufskalieren möchten.
Ressourcenverbrauch erhöhen
Dies ist die allgemeinste - Ihre Last ist so weit angestiegen, dass Ihre vorhandenen Ressourcen nicht mehr in der Lage sind, damit umzugehen. Es kann alles sein. Die CPU-Auslastung hat zugenommen und Ihr Datenbank-Cluster ist nicht mehr in der Lage, Daten mit angemessener und stabiler Abfrageausführungszeit zu liefern. Die Speicherauslastung ist so stark angestiegen, dass die Datenbank nicht mehr CPU-gebunden ist, sondern I/O-gebunden ist und somit die Leistung der Datenbankknoten erheblich reduziert wurde. Netzwerk kann auch ein Bootle-Neck sein. Sie werden überrascht sein zu sehen, welche Limits in Bezug auf das Netzwerk Ihren Cloud-Instanzen zugewiesen sind. Tatsächlich kann dies die häufigste Grenze werden, mit der Sie umgehen müssen, da das Netzwerk alles in der Cloud ist – nicht nur die Daten, die zwischen der Anwendung und der Datenbank gesendet werden, sondern auch der Speicher, der über das Netzwerk verbunden ist. Es kann auch die Festplattennutzung sein – Ihnen geht einfach der Speicherplatz aus oder, was wahrscheinlicher ist, da wir heutzutage ziemlich große Festplatten haben können, ist die Datenbankgröße über die „verwaltbare“ Größe hinausgewachsen. Wartungsarbeiten wie Schemaänderungen werden zu einer Herausforderung, die Leistung wird aufgrund der Datengröße reduziert, Sicherungen dauern ewig. Alle diese Fälle können ein gültiger Fall für die Notwendigkeit einer Skalierung sein.
Plötzlicher Anstieg der Arbeitsbelastung
Ein weiterer Beispielfall, in dem eine Skalierung erforderlich ist, ist ein plötzlicher Anstieg der Arbeitslast. Aus irgendeinem Grund (seien es Marketingbemühungen, Inhalte, die viral werden, ein Notfall oder eine ähnliche Situation) erfährt Ihre Infrastruktur einen erheblichen Anstieg der Last auf dem Datenbankcluster. Die CPU-Last geht in die Höhe, Festplatten-I/O verlangsamt die Abfragen usw. So ziemlich jede Ressource, die wir im vorherigen Abschnitt erwähnt haben, kann überlastet werden und anfangen, Probleme zu verursachen.
Geplanter Betrieb
Der dritte Grund, den wir hervorheben möchten, ist der allgemeinere - eine Art geplante Operation. Es kann eine geplante Marketingaktivität sein, von der Sie erwarten, dass sie mehr Traffic bringt, Black Friday, Lasttests oder so ziemlich alles, was Sie im Voraus wissen.
Jeder dieser Gründe hat seine eigenen Eigenschaften. Wenn Sie im Voraus planen können, können Sie den Prozess detailliert vorbereiten, testen und ausführen, wann immer Sie Lust dazu haben. Sie werden es höchstwahrscheinlich gerne in einer Zeit mit „niedrigem Datenverkehr“ tun, solange so etwas in Ihren Workloads vorhanden ist (es muss nicht vorhanden sein). Auf der anderen Seite erzwingen plötzliche Lastspitzen, insbesondere wenn sie erheblich genug sind, um die Produktion zu beeinträchtigen, eine sofortige Reaktion, unabhängig davon, wie vorbereitet Sie sind und wie sicher es ist. Wenn Ihre Dienste bereits beeinträchtigt sind, können Sie dies auch tun mach es statt zu warten.
Arten der Datenbankskalierung
Es gibt zwei Hauptarten der Skalierung:vertikal und horizontal. Beide haben Vor- und Nachteile, beide sind in verschiedenen Situationen nützlich. Werfen wir einen Blick darauf und diskutieren Anwendungsfälle für beide Szenarien.
Vertikale Skalierung
Diese Skalierungsmethode ist wahrscheinlich die älteste:Wenn Ihre Hardware nicht stark genug ist, um mit der Arbeitslast fertig zu werden, verstärken Sie sie. Wir sprechen hier einfach über das Hinzufügen von Ressourcen zu bestehenden Knoten mit der Absicht, sie in die Lage zu versetzen, die gestellten Aufgaben zu bewältigen. Dies hat einige Auswirkungen, auf die wir näher eingehen möchten.
Vorteile der vertikalen Skalierung
Das Wichtigste ist, dass alles beim Alten bleibt. Sie hatten drei Knoten in einem Datenbank-Cluster, Sie haben immer noch drei Knoten, nur leistungsfähiger. Sie müssen Ihre Umgebung nicht neu gestalten oder ändern, wie die Anwendung auf die Datenbank zugreifen soll – alles bleibt genau gleich, da sich konfigurationstechnisch nichts wirklich geändert hat.
Ein weiterer wesentlicher Vorteil der vertikalen Skalierung ist, dass sie sehr schnell sein kann, insbesondere in Cloud-Umgebungen. Der gesamte Prozess besteht im Wesentlichen darin, den vorhandenen Knoten zu stoppen, die Änderung an der Hardware vorzunehmen und den Knoten erneut zu starten. Für klassische On-Prem-Setups ohne jegliche Virtualisierung kann dies schwierig sein - Sie haben möglicherweise keine schnelleren CPUs zum Austauschen verfügbar, das Aufrüsten von Festplatten auf größere oder schnellere Festplatten kann ebenfalls zeitaufwändig sein, aber für Cloud-Umgebungen, sei es öffentlich oder privat, Dies kann so einfach sein wie das Ausführen von drei Befehlen:Instanz stoppen, Instanz auf eine größere Größe aktualisieren, Instanz starten. Virtuelle IPs und wiederverknüpfbare Volumes erleichtern das Verschieben von Daten zwischen Instanzen.
Nachteile der vertikalen Skalierung
Der Hauptnachteil der vertikalen Skalierung ist, dass sie einfach ihre Grenzen hat. Wenn Sie die größte verfügbare Instanzgröße mit den schnellsten Festplattenvolumes verwenden, können Sie nicht viel mehr tun. Es ist auch nicht so einfach, die Leistung Ihres Datenbank-Clusters signifikant zu steigern. Dies hängt hauptsächlich von der anfänglichen Instanzgröße ab, aber wenn Sie bereits sehr leistungsfähige Knoten ausführen, können Sie möglicherweise keine 10-fache Skalierung mit vertikaler Skalierung erreichen. Knoten, die 10x schneller wären, könnten einfach nicht existieren.
Horizontale Skalierung
Horizontale Skalierung ist ein anderes Biest. Anstatt mit der Instanzgröße nach oben zu gehen, bleiben wir auf dem gleichen Niveau, aber wir erweitern uns horizontal, indem wir weitere Knoten hinzufügen. Auch hier gibt es Vor- und Nachteile dieser Methode.
Vorteile der horizontalen Skalierung
Der Hauptvorteil der horizontalen Skalierung besteht darin, dass theoretisch keine Grenzen gesetzt sind. Es gibt keine künstliche feste Grenze für die horizontale Skalierung, obwohl Grenzen bestehen, hauptsächlich weil die Kommunikation innerhalb des Clusters mit jedem neuen Knoten, der dem Cluster hinzugefügt wird, immer größer wird.
Ein weiterer bedeutender Vorteil wäre, dass Sie den Cluster ohne Ausfallzeiten skalieren können. Wenn Sie Hardware aktualisieren möchten, müssen Sie die Instanz stoppen, aktualisieren und dann erneut starten. Wenn Sie dem Cluster weitere Knoten hinzufügen möchten, müssen Sie lediglich diese Knoten bereitstellen, die benötigte Software installieren, einschließlich der Datenbank, und sie dem Cluster beitreten lassen. Optional (je nachdem, ob der Cluster über interne Methoden zum Bereitstellen neuer Knoten mit den Daten verfügt) müssen Sie ihn möglicherweise selbst mit Daten bereitstellen. In der Regel handelt es sich jedoch um einen automatisierten Prozess.
Nachteile der horizontalen Skalierung
Das Hauptproblem, mit dem Sie sich auseinandersetzen müssen, ist, dass das Hinzufügen von immer mehr Knoten die Verwaltung der gesamten Umgebung erschwert. Sie müssen erkennen können, welche Knoten verfügbar sind, eine solche Liste muss gepflegt und mit jedem neu erstellten Knoten aktualisiert werden. Möglicherweise benötigen Sie externe Lösungen wie Verzeichnisdienste (Consul oder Etcd), um die Knoten und ihren Status zu verfolgen. Dies erhöht natürlich die Komplexität der gesamten Umgebung.
Ein weiteres potenzielles Problem ist, dass der Scale-out-Prozess Zeit braucht. Neue Knoten hinzuzufügen und sie mit Software und insbesondere Daten zu versorgen, erfordert Zeit. Wie viel, hängt von der Hardware (hauptsächlich I/O- und Netzwerkdurchsatz) und der Größe der Daten ab. Bei großen Setups kann dies ein erheblicher Zeitaufwand sein, und dies kann ein Hindernis für Situationen sein, in denen die Skalierung sofort erfolgen muss. Stundenlanges Warten auf das Hinzufügen neuer Knoten ist möglicherweise nicht akzeptabel, wenn der Datenbankcluster so stark beeinträchtigt wird, dass Vorgänge nicht ordnungsgemäß ausgeführt werden.
Voraussetzungen für die Skalierung
Datenreplikation
Bevor ein Skalierungsversuch unternommen werden kann, muss Ihre Umgebung einige Anforderungen erfüllen. Zunächst einmal muss Ihre Anwendung in der Lage sein, mehr als einen Knoten zu nutzen. Wenn nur ein Knoten verwendet werden kann, sind Ihre Optionen auf die vertikale Skalierung beschränkt. Sie können die Größe eines solchen Knotens erhöhen oder dem Bare-Metal-Server einige Hardware-Ressourcen hinzufügen und ihn leistungsfähiger machen, aber das ist das Beste, was Sie tun können:Sie werden immer durch die Verfügbarkeit leistungsfähigerer Hardware eingeschränkt sein, und irgendwann werden Sie feststellen ohne die Möglichkeit zur weiteren Skalierung.
Wenn Sie andererseits die Möglichkeit haben, mehrere Datenbankknoten von Ihrer Anwendung zu nutzen, können Sie von der horizontalen Skalierung profitieren. Lassen Sie uns hier aufhören und besprechen, was Sie benötigen, um das volle Potenzial mehrerer Knoten tatsächlich auszuschöpfen.
Zunächst einmal die Möglichkeit, Lesevorgänge von Schreibvorgängen zu trennen. Traditionell verbindet sich die Anwendung mit nur einem Knoten. Dieser Knoten wird verwendet, um alle Schreib- und Lesevorgänge zu verarbeiten, die von der Anwendung ausgeführt werden.

Das Hinzufügen eines zweiten Knotens zum Cluster ändert aus Sicht der Skalierung nichts . Sie müssen bedenken, dass bei Ausfall eines Knotens der andere den Datenverkehr bewältigen muss, sodass die Summe der Last über beide Knoten zu keinem Zeitpunkt zu hoch sein sollte, um von einem einzelnen Knoten bewältigt zu werden.

Mit drei verfügbaren Knoten können Sie zwei Knoten vollständig nutzen. Dadurch können wir einen Teil des Leseverkehrs skalieren:Wenn ein Knoten 100 % Kapazität hat (und wir würden lieber höchstens 70 %) ausführen, dann repräsentieren zwei Knoten 200 %. Drei Knoten:300 %. Wenn ein Knoten ausfällt und wir die verbleibenden Knoten fast bis an die Grenze auslasten, können wir sagen, dass wir mit 170–180 % der Kapazität eines einzelnen Knotens arbeiten können, wenn der Cluster herabgesetzt ist. Das gibt uns eine schöne Auslastung von 60 % auf jedem Knoten, wenn alle drei Knoten verfügbar sind.
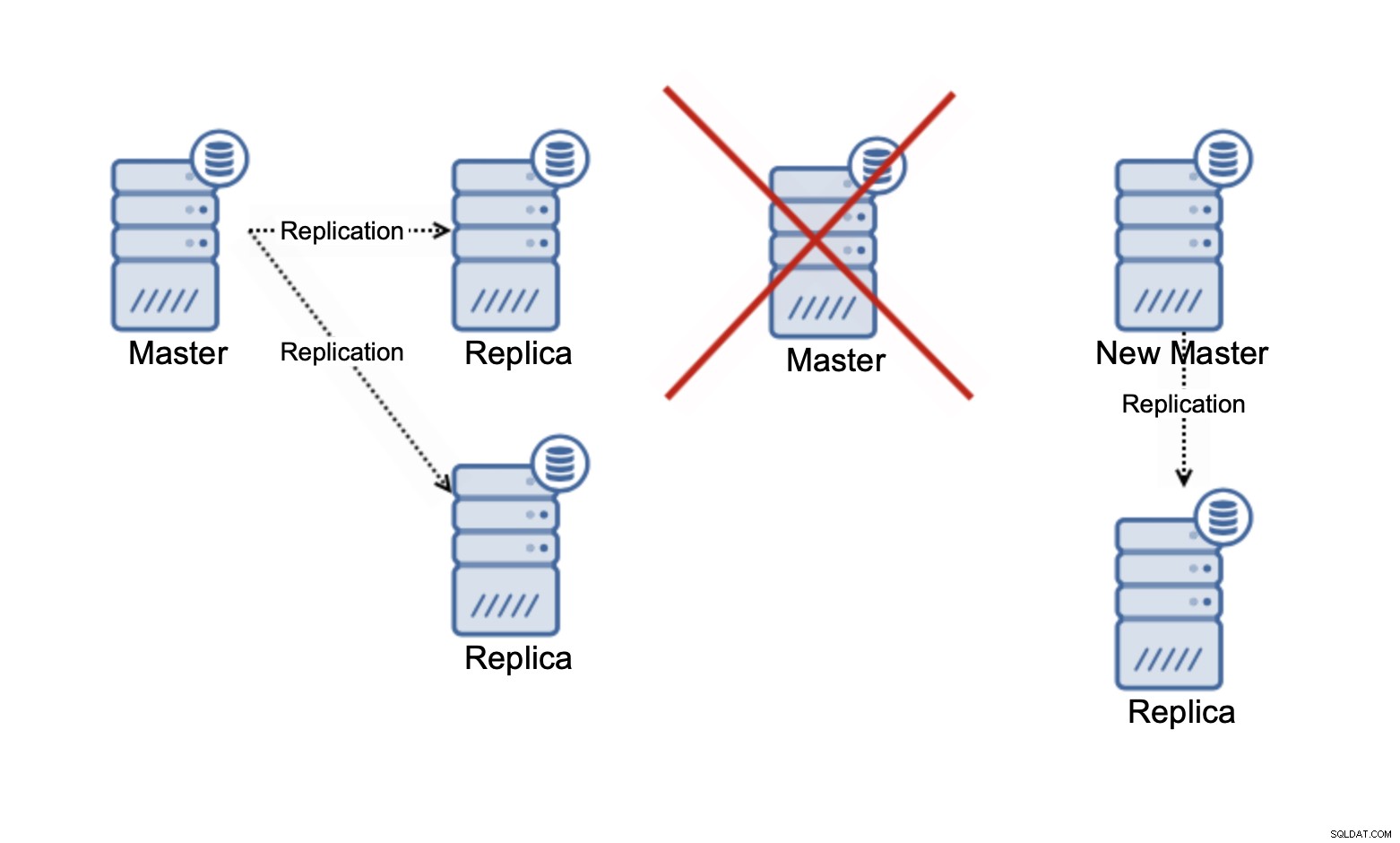
Bitte denken Sie daran, dass wir in diesem Moment nur über das Skalieren von Lesevorgängen sprechen . Zu keinem Zeitpunkt kann die Replikation Ihre Schreibkapazität verbessern. Bei der asynchronen Replikation haben Sie nur einen Writer (Master), und bei der synchronen Replikation wie Galera, bei der das Dataset von allen Knoten gemeinsam genutzt wird, muss jeder Schreibvorgang, der auf einem Knoten stattfindet, auf den verbleibenden Knoten des ausgeführt werden Cluster.
Wenn Sie in einem Galera-Cluster mit drei Knoten eine Zeile schreiben, schreiben Sie tatsächlich drei Zeilen, eine für jeden Knoten. Das Hinzufügen weiterer Knoten oder Replikate macht keinen Unterschied. Anstatt dieselbe Zeile auf drei Knoten zu schreiben, schreiben Sie sie auf fünf. Aus diesem Grund sollten Sie Ihre Schreibvorgänge in einem Multi-Master-Cluster aufteilen, in dem der Datensatz von allen Knoten gemeinsam genutzt wird (es gibt Multi-Master-Cluster, in denen Daten aufgeteilt werden, z. macht nicht allzu viel Sinn. Es erhöht den Overhead für den Umgang mit potenziellen Schreibkonflikten auf allen Knoten, während es nicht wirklich etwas an der gesamten Schreibkapazität ändert.
Load-Balancing und Lese-/Schreib-Aufteilung
Die Möglichkeit, Lesevorgänge von Schreibvorgängen zu trennen, ist ein Muss, wenn Sie Ihre Lesevorgänge in asynchronen Replikationskonfigurationen skalieren möchten. Sie müssen in der Lage sein, Schreibdatenverkehr an einen Knoten und dann die Lesevorgänge an alle Knoten in der Replikationstopologie zu senden. Wie bereits erwähnt, ist diese Funktionalität auch in Multi-Master-Clustern sehr nützlich, da sie es uns ermöglicht, die Schreibkonflikte zu beseitigen, die auftreten können, wenn Sie versuchen, die Schreibvorgänge auf mehrere Knoten im Cluster zu verteilen. Wie können wir die Lese-/Schreibaufteilung durchführen? Es gibt mehrere Methoden, die Sie dafür verwenden können. Lassen Sie uns ein wenig in dieses Thema eintauchen.
R/W-Aufteilung auf Anwendungsebene
Das einfachste Szenario, das am wenigsten häufig vorkommt:Ihre Anwendung kann konfiguriert werden, welche Knoten Schreibvorgänge und welche Knoten Lesevorgänge erhalten sollen. Diese Funktionalität kann auf verschiedene Arten konfiguriert werden, am einfachsten ist die fest codierte Liste der Knoten, aber es könnte auch etwas in der Art eines dynamischen Knoteninventars sein, das durch Hintergrundthreads aktualisiert wird. Das Hauptproblem bei diesem Ansatz besteht darin, dass die gesamte Logik als Teil der Anwendung geschrieben werden muss. Mit einer hartcodierten Liste von Knoten würde das einfachste Szenario Änderungen am Anwendungscode für jede Änderung in der Replikationstopologie erfordern. Auf der anderen Seite wären fortschrittlichere Lösungen wie die Implementierung einer Diensterkennung auf lange Sicht komplexer in der Wartung.
R/W-Split im Stecker
Eine andere Option wäre die Verwendung eines Connectors, um eine Lese-/Schreibaufteilung durchzuführen. Nicht alle haben diese Option, aber einige schon. Ein Beispiel wäre php-mysqlnd oder Connector/J. Wie es in die Anwendung integriert wird, kann je nach Konnektor selbst unterschiedlich sein. In einigen Fällen muss die Konfiguration in der Anwendung vorgenommen werden, in einigen Fällen muss sie in einer separaten Konfigurationsdatei für den Connector erfolgen. Der Vorteil dieses Ansatzes besteht darin, dass selbst wenn Sie Ihre Anwendung erweitern müssen, der Großteil des neuen Codes einsatzbereit ist und von externen Quellen gepflegt wird. Es macht es einfacher, mit einem solchen Setup umzugehen, und Sie müssen weniger Code schreiben (falls vorhanden).
R/W-Aufteilung im Loadbalancer
Zu guter Letzt eine der besten Lösungen:Loadbalancer. Die Idee ist einfach:Leiten Sie Ihre Daten durch einen Loadbalancer, der zwischen Lese- und Schreibvorgängen unterscheiden kann, und senden Sie sie an einen geeigneten Speicherort. Dies ist aus Sicht der Benutzerfreundlichkeit eine große Verbesserung, da wir die Datenbankerkennung und das Abfragerouting von der Anwendung trennen können. Die Anwendung muss lediglich den Datenverkehr der Datenbank an einen einzelnen Endpunkt senden, der aus einem Hostnamen und einem Port besteht. Der Rest passiert im Hintergrund. Loadbalancer arbeiten daran, die Abfragen an Back-End-Datenbankknoten weiterzuleiten. Loadbalancer können auch die Erkennung der Replikationstopologie durchführen, oder Sie können mit etcd oder consul ein ordnungsgemäßes Dienstinventar implementieren und es über Ihre Infrastruktur-Orchestrierungstools wie Ansible aktualisieren.
Damit endet der erste Teil dieses Blogs. Im zweiten diskutieren wir die Herausforderungen, denen wir bei der Skalierung der Datenbankschicht gegenüberstehen. Wir werden auch einige Möglichkeiten erörtern, wie wir unsere Datenbank-Cluster skalieren können.