SQLAlchemy hilft Ihnen bei der Arbeit mit Datenbanken in Python. In diesem Beitrag sagen wir Ihnen alles, was Sie wissen müssen, um mit diesem Modul zu beginnen.
Im vorherigen Artikel haben wir darüber gesprochen, wie man Python im ETL-Prozess verwendet. Wir haben uns darauf konzentriert, die Arbeit zu erledigen, indem wir gespeicherte Prozeduren und SQL-Abfragen ausführen. In diesem und dem nächsten Artikel verwenden wir einen anderen Ansatz. Anstatt SQL-Code zu schreiben, verwenden wir das SQLAlchemy-Toolkit. Sie können diesen Artikel auch separat als kurze Einführung in die Installation und Verwendung von SQLAlchemy verwenden.
Bereit? Fangen wir an.
Was ist SQLAlchemy?
Python ist bekannt für seine Anzahl und Vielfalt an Modulen. Diese Module verkürzen unsere Programmierzeit erheblich, da sie Routinen implementieren, die zum Erreichen einer bestimmten Aufgabe erforderlich sind. Eine Reihe von Modulen, die mit Daten arbeiten, sind verfügbar, einschließlich SQLAlchemy.
Um SQLAlchemy zu beschreiben, verwende ich ein Zitat von SQLAlchemy.org:
SQLAlchemy ist das Python SQL-Toolkit und der objektrelationale Mapper, der Anwendungsentwicklern die volle Leistung und Flexibilität von SQL bietet.
Es bietet eine vollständige Suite bekannter Persistenz auf Unternehmensebene Muster, entworfen für einen effizienten und leistungsstarken Datenbankzugriff, angepasst an eine einfache und pythonische Domänensprache.
Der wichtigste Teil hier ist der Abschnitt über den ORM (Object-Relational Mapper), der uns hilft, Datenbankobjekte als Python-Objekte und nicht als Listen zu behandeln.
Bevor wir mit SQLAlchemy weitermachen, lassen Sie uns innehalten und über ORMs sprechen.
Die Vor- und Nachteile der Verwendung von ORMs
Im Vergleich zu reinem SQL haben ORMs ihre Vor- und Nachteile – und die meisten davon gelten auch für SQLAlchemy.
Das Gute:
- Code-Übertragbarkeit. Das ORM kümmert sich um syntaktische Unterschiede zwischen Datenbanken.
- Nur eine Sprache wird benötigt, um Ihre Datenbank zu verwalten. Obwohl dies ehrlich gesagt nicht die Hauptmotivation für die Verwendung eines ORM sein sollte.
- ORMs vereinfachen Ihren Code , z.B. Sie kümmern sich um Beziehungen und behandeln sie wie Objekte, was großartig ist, wenn Sie an OOP gewöhnt sind.
- Sie können Ihre Daten innerhalb des Programms manipulieren .
Leider hat alles seinen Preis. Das nicht so Gute an ORMs:
- In manchen Fällen kann ein ORM langsam sein .
- Schreiben von komplexen Abfragen könnte noch komplizierter werden oder zu langsamen Abfragen führen. Dies ist jedoch bei Verwendung von SQLAlchemy nicht der Fall.
- Wenn Sie Ihr DBMS gut kennen, ist es Zeitverschwendung zu lernen, wie man dasselbe in ein ORM schreibt.
Nachdem wir dieses Thema behandelt haben, kehren wir zu SQLAlchemy zurück.
Bevor wir anfangen...
… erinnern wir uns an das Ziel dieses Artikels. Wenn Sie nur an der Installation von SQLAlchemy interessiert sind und eine kurze Anleitung zur Ausführung einfacher Befehle benötigen, wird dieser Artikel dies tun. Die in diesem Artikel vorgestellten Befehle werden jedoch im nächsten Artikel verwendet, um den ETL-Prozess auszuführen und den SQL- (gespeicherte Prozeduren) und Python-Code zu ersetzen, den wir in früheren Artikeln vorgestellt haben.
Okay, fangen wir jetzt ganz von vorne an:mit der Installation von SQLAlchemy.
Installieren von SQLAlchemy
1. Überprüfen Sie, ob das Modul bereits installiert ist
Um ein Python-Modul zu verwenden, müssen Sie es installieren (wenn es nicht bereits installiert war). Eine Möglichkeit, zu überprüfen, welche Module installiert wurden, ist die Verwendung dieses Befehls in der Python-Shell:
help('modules')
Um zu überprüfen, ob ein bestimmtes Modul installiert ist, versuchen Sie einfach, es zu importieren. Verwenden Sie diese Befehle:
import sqlalchemy sqlalchemy.__version__
Wenn SQLAlchemy bereits installiert ist, wird die erste Zeile erfolgreich ausgeführt. import ist ein Standard-Python-Befehl, der zum Importieren von Modulen verwendet wird. Wenn das Modul nicht installiert ist, wirft Python einen Fehler aus – eigentlich eine Liste von Fehlern in roter Schrift – die Sie nicht übersehen können :)
Der zweite Befehl gibt die aktuelle Version von SQLAlchemy zurück. Das zurückgegebene Ergebnis ist unten abgebildet:

Wir brauchen auch ein anderes Modul, und das ist PyMySQL . Dies ist eine reine Python-Leichtgewichts-MySQL-Client-Bibliothek. Dieses Modul unterstützt alles, was wir für die Arbeit mit einer MySQL-Datenbank benötigen, von der Ausführung einfacher Abfragen bis hin zu komplexeren Datenbankaktionen. Wir können mit help('modules') überprüfen, ob es existiert , wie zuvor beschrieben, oder mit den beiden folgenden Anweisungen:
import pymysql pymysql.__version__
Natürlich sind dies dieselben Befehle, die wir verwendet haben, um zu testen, ob SQLAlchemy installiert wurde.
Was ist, wenn SQLAlchemy oder PyMySQL noch nicht installiert ist?
Das Importieren zuvor installierter Module ist nicht schwierig. Was aber, wenn die benötigten Module noch nicht installiert sind?
Einige Module haben ein Installationspaket, aber meistens verwenden Sie den Pip-Befehl, um sie zu installieren. PIP ist ein Python-Tool zum Installieren und Deinstallieren von Modulen. Der einfachste Weg, ein Modul zu installieren (im Windows-Betriebssystem), ist:
- Verwenden Sie Eingabeaufforderung -> Ausführen -> cmd .
- Position zum Python-Verzeichnis cd C:\...\Python\Python37\Scripts .
- Führen Sie den Befehl pip
installaus (in unserem Fall führen wirpip install pyMySQLaus undpip install sqlAlchemy.
PIP kann auch verwendet werden, um das vorhandene Modul zu deinstallieren. Dazu sollten Sie pip uninstall verwenden .
2. Mit der Datenbank verbinden
Es ist zwar wichtig, alles zu installieren, was zur Verwendung von SQLAlchemy erforderlich ist, aber es ist nicht sehr interessant. Es ist auch nicht wirklich Teil dessen, woran wir interessiert sind. Wir haben nicht einmal eine Verbindung zu den Datenbanken hergestellt, die wir verwenden möchten. Das lösen wir jetzt:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Mit dem obigen Skript stellen wir eine Verbindung zu der Datenbank her, die sich auf unserem lokalen Server befindet, dem subscription_live Datenbank.
(Hinweis: Ersetzen Sie
Lassen Sie uns das Skript Befehl für Befehl durchgehen.
import sqlalchemy from sqlalchemy.engine import create_engine
Diese beiden Zeilen importieren unser Modul und die create_engine Funktion.
Als nächstes stellen wir eine Verbindung zu der Datenbank her, die sich auf unserem Server befindet.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Die Funktion create_engine erstellt die Engine und verwendet .connect() , verbindet sich mit der Datenbank. Die create_engine Funktion verwendet diese Parameter:
dialect+driver://username:password@host:port/database
In unserem Fall ist der Dialekt mysql , der Treiber ist pymysql (zuvor installiert) und die verbleibenden Variablen sind spezifisch für den Server und die Datenbank(en), zu denen wir eine Verbindung herstellen möchten.
(Hinweis: Wenn Sie eine lokale Verbindung herstellen, verwenden Sie localhost statt Ihrer „lokalen“ IP-Adresse 127.0.0.1 und den entsprechenden Port :3306 .)

Das Ergebnis des Befehls print(engine_live.table_names()) ist im Bild oben dargestellt. Wie erwartet haben wir die Liste aller Tische aus unserer Betriebs-/Live-Datenbank erhalten.
3. Ausführen von SQL-Befehlen mit SQLAlchemy
In diesem Abschnitt analysieren wir die wichtigsten SQL-Befehle, untersuchen die Tabellenstruktur und führen alle vier DML-Befehle aus:SELECT, INSERT, UPDATE und DELETE.
Wir werden die in diesem Skript verwendeten Anweisungen separat besprechen. Bitte beachten Sie, dass wir den Verbindungsteil dieses Skripts bereits durchgegangen sind und Tabellennamen bereits aufgelistet haben. Es gibt geringfügige Änderungen in dieser Zeile:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Wir haben gerade alles, was wir verwenden werden, aus SQLAlchemy importiert.
Tabellen und Struktur
Wir führen das Skript aus, indem wir den folgenden Befehl in die Python-Shell eingeben:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Das Ergebnis ist das ausgeführte Skript. Lassen Sie uns nun den Rest des Skripts analysieren.
SQLAlchemy importiert Informationen zu Tabellen, Strukturen und Beziehungen. Um mit diesen Informationen zu arbeiten, könnte es nützlich sein, die Liste der Tabellen (und ihrer Spalten) in der Datenbank zu überprüfen:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Dies gibt einfach eine Liste aller Tabellen aus der verbundenen Datenbank zurück.
Hinweis: Die table_names() -Methode gibt eine Liste mit Tabellennamen für die angegebene Engine zurück. Sie können die gesamte Liste drucken oder sie mit einer Schleife durchlaufen (wie Sie es mit jeder anderen Liste tun könnten).
Als Nächstes geben wir eine Liste aller Attribute aus der ausgewählten Tabelle zurück. Der relevante Teil des Skripts und das Ergebnis werden unten angezeigt:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
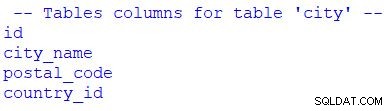
Sie können sehen, dass ich for verwendet habe um die Ergebnismenge zu durchlaufen. Wir könnten table_city.c ersetzen mit table_city.columns .
Hinweis: Der Prozess des Ladens der Datenbankbeschreibung und des Erstellens von Metadaten in SQLAlchemy wird Reflektion genannt.
Hinweis: MetaData ist das Objekt, das Informationen über Objekte in der Datenbank speichert, daher sind Tabellen in der Datenbank auch mit diesem Objekt verknüpft. Im Allgemeinen speichert dieses Objekt Informationen darüber, wie das Datenbankschema aussieht. Sie verwenden es als zentrale Anlaufstelle, wenn Sie Änderungen am DB-Schema vornehmen oder Informationen über das DB-Schema erhalten möchten.
Hinweis: Die Attribute autoload = True und autoload_with = engine_live sollte verwendet werden, um sicherzustellen, dass Tabellenattribute hochgeladen werden (falls dies noch nicht geschehen ist).
AUSWÄHLEN
Ich glaube nicht, dass ich erklären muss, wie wichtig die SELECT-Anweisung ist :) Sagen wir also einfach, dass Sie SQLAlchemy verwenden können, um SELECT-Anweisungen zu schreiben. Wenn Sie an die MySQL-Syntax gewöhnt sind, wird es einige Zeit dauern, sich daran zu gewöhnen; trotzdem ist alles ziemlich logisch. Um es so einfach wie möglich auszudrücken, würde ich sagen, dass die SELECT-Anweisung zerlegt ist und einige Teile weggelassen wurden, aber alles ist immer noch in der gleichen Reihenfolge.
Lassen Sie uns jetzt ein paar SELECT-Anweisungen ausprobieren.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Die erste ist eine einfache SELECT-Anweisung Zurückgeben aller Werte aus der angegebenen Tabelle. Die Syntax dieser Anweisung ist sehr einfach:Ich habe den Namen der Tabelle in select() platziert . Bitte beachten Sie, dass ich:
- Anweisung vorbereitet -
stmt = select([table_city]. - Ausdruck der Anweisung mit
print(stmt), was uns eine gute Vorstellung von der gerade ausgeführten Anweisung gibt. Dies könnte auch zum Debuggen verwendet werden. - Druckte das Ergebnis mit
print(connection_live.execute(stmt).fetchall()). - Durchläuft das Ergebnis und druckt jeden einzelnen Datensatz.
Hinweis: Da wir auch Primär- und Fremdschlüsseleinschränkungen in SQLAlchemy geladen haben, nimmt die SELECT-Anweisung eine Liste von Tabellenobjekten als Argumente und stellt bei Bedarf automatisch Beziehungen her.
Das Ergebnis ist im Bild unten dargestellt:

Python ruft alle Attribute aus der Tabelle ab und speichert sie im Objekt. Wie gezeigt, können wir dieses Objekt verwenden, um zusätzliche Operationen auszuführen. Das Endergebnis unserer Anweisung ist eine Liste aller Städte aus dem city Tabelle.
Jetzt sind wir bereit für eine komplexere Abfrage. Ich habe gerade eine ORDER BY-Klausel hinzugefügt .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Hinweis: Der asc() -Methode führt eine aufsteigende Sortierung anhand des übergeordneten Objekts durch, wobei definierte Spalten als Parameter verwendet werden.
Die zurückgegebene Liste ist dieselbe, aber jetzt ist sie nach dem ID-Wert in aufsteigender Reihenfolge sortiert. Es ist wichtig zu beachten, dass wir einfach .order_by( hinzugefügt haben zur vorherigen SELECT-Abfrage. Der .order_by(...) -Methode ermöglicht es uns, die Reihenfolge der zurückgegebenen Ergebnismenge zu ändern, genauso wie wir es in einer SQL-Abfrage verwenden würden. Daher sollten Parameter der SQL-Logik folgen und Spaltennamen oder Spaltenreihenfolge sowie ASC oder DESC verwenden.
Als Nächstes werden wir WHERE hinzufügen zu unserer SELECT-Anweisung.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Hinweis: Das .where() Methode wird verwendet, um eine Bedingung zu testen, die wir als Argument verwendet haben. Wir könnten auch .filter() verwenden -Methode, die komplexere Bedingungen besser filtert.
Noch einmal, das .where part wird einfach mit unserer SELECT-Anweisung verkettet. Beachten Sie, dass wir die Bedingung in die Klammern gesetzt haben. Welche Bedingung auch immer in Klammern steht, sie wird auf die gleiche Weise getestet, wie sie im WHERE-Teil einer SELECT-Anweisung getestet würde. Die Gleichheitsbedingung wird mit ==statt =getestet.
Das letzte, was wir mit SELECT versuchen werden, ist das Verbinden von zwei Tischen. Schauen wir uns zuerst den Code und sein Ergebnis an.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Es gibt zwei wichtige Teile in der obigen Aussage:
select([table_city.columns.city_name, table_country.columns.country_name])definiert, welche Spalten in unserem Ergebnis zurückgegeben werden..select_from(table_city.join(table_country))definiert die Join-Bedingung/Tabelle. Beachten Sie, dass wir nicht die vollständige Join-Bedingung einschließlich der Schlüssel aufschreiben mussten. Dies liegt daran, dass SQLAlchemy „weiß“, wie diese beiden Tabellen verknüpft sind, da Primärschlüssel- und Fremdschlüsselregeln im Hintergrund importiert werden.
EINFÜGEN / AKTUALISIEREN / LÖSCHEN
Dies sind die drei verbleibenden DML-Befehle, die wir in diesem Artikel behandeln werden. Obwohl ihre Struktur sehr komplex werden kann, sind diese Befehle normalerweise viel einfacher. Der verwendete Code ist unten dargestellt.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Dasselbe Muster wird für alle drei Anweisungen verwendet:Vorbereiten der Anweisung, Drucken und Ausführen und Drucken des Ergebnisses nach jeder Anweisung, damit wir sehen können, was tatsächlich in der Datenbank passiert ist. Beachten Sie noch einmal, dass Teile der Anweisung als Objekte behandelt wurden (.values(), .where()).

Wir werden dieses Wissen im nächsten Artikel nutzen, um ein vollständiges ETL-Skript mit SQLAlchemy zu erstellen.
Als Nächstes:SQLAlchemy im ETL-Prozess
Heute haben wir analysiert, wie man SQLAlchemy einrichtet und einfache DML-Befehle ausführt. Im nächsten Artikel werden wir dieses Wissen nutzen, um den vollständigen ETL-Prozess mit SQLAlchemy zu schreiben.
Sie können das vollständige Skript, das in diesem Artikel verwendet wird, hier herunterladen.