Datenbanken müssen optimal laufen, aber das ist keine so einfache Aufgabe. Die INFORMATION SCHEMA-Datenbank kann Ihre Geheimwaffe im Krieg der Datenbankoptimierung sein.
Wir sind es gewohnt, Datenbanken mit einer grafischen Oberfläche oder einer Reihe von SQL-Befehlen zu erstellen. Das ist völlig in Ordnung, aber es ist auch gut, ein bisschen zu verstehen, was im Hintergrund vor sich geht. Dies ist wichtig für die Erstellung, Wartung und Optimierung einer Datenbank, und es ist auch eine gute Möglichkeit, Änderungen „hinter den Kulissen“ zu verfolgen.
In diesem Artikel sehen wir uns eine Handvoll SQL-Abfragen an, die Ihnen helfen können, einen Blick in die Funktionsweise einer MySQL-Datenbank zu werfen.
Die INFORMATION_SCHEMA-Datenbank
Wir haben bereits das INFORMATION_SCHEMA besprochen Datenbank in diesem Artikel. Wenn Sie es noch nicht gelesen haben, würde ich Ihnen auf jeden Fall empfehlen, dies zu tun, bevor Sie fortfahren.
Wenn Sie eine Auffrischung des INFORMATION_SCHEMA benötigen Datenbank – oder falls Sie sich entscheiden, den ersten Artikel nicht zu lesen – hier sind einige grundlegende Fakten, die Sie wissen müssen:
- Das
INFORMATION_SCHEMADatenbank ist Teil des ANSI-Standards. Wir werden mit MySQL arbeiten, aber andere RDBMS haben ihre Varianten. Sie finden Versionen für H2 Database, HSQLDB, MariaDB, Microsoft SQL Server und PostgreSQL. - Dies ist die Datenbank, die alle anderen Datenbanken auf dem Server verfolgt; Beschreibungen aller Objekte finden Sie hier.
- Wie jede andere Datenbank ist auch das
INFORMATION_SCHEMADie Datenbank enthält eine Reihe verwandter Tabellen und Informationen zu verschiedenen Objekten. - Sie können diese Datenbank mit SQL abfragen und die Ergebnisse verwenden für:
- Datenbankstatus und -leistung überwachen und
- Generieren Sie automatisch Code basierend auf Abfrageergebnissen.
Fahren wir nun mit der Abfrage der Datenbank INFORMATION_SCHEMA fort. Wir beginnen mit einem Blick auf das Datenmodell, das wir verwenden werden.
Das Datenmodell
Das Modell, das wir in diesem Artikel verwenden, ist unten abgebildet.
Dies ist ein vereinfachtes Modell, das es uns ermöglicht, Informationen über Klassen, Lehrer, Schüler und andere zugehörige Details zu speichern. Gehen wir kurz die Tabellen durch.
Wir speichern die Liste der Dozenten im lecturer Tisch. Für jeden Dozenten erfassen wir einen first_name und ein last_name .
Die class Tabelle listet alle Klassen auf, die wir in unserer Schule haben. Für jeden Datensatz in dieser Tabelle speichern wir den class_name , die Dozenten-ID, ein geplantes start_date und end_date , und alle zusätzlichen class_details . Der Einfachheit halber gehe ich davon aus, dass wir nur einen Dozenten pro Klasse haben.
Der Unterricht ist in der Regel als Vorlesungsreihe organisiert. Sie erfordern in der Regel eine oder mehrere Prüfungen. Wir speichern Listen mit verwandten Vorlesungen und Prüfungen in der lecture und exam Tische. Beide haben die ID der zugehörigen Klasse und die erwartete start_time und end_time .
Jetzt brauchen wir Schüler für unseren Unterricht. Eine Liste aller Studenten wird im student Tisch. Auch hier speichern wir nur den first_name und der last_name jedes Schülers.
Als letztes müssen wir die Aktivitäten der Schüler verfolgen. Wir speichern eine Liste aller Kurse, für die sich ein Schüler angemeldet hat, die Anwesenheitsliste des Schülers und seine Prüfungsergebnisse. Jede der verbleibenden drei Tabellen – on_class , on_lecture und on_exam – wird einen Verweis auf den Schüler und einen Verweis auf die entsprechende Tabelle enthalten. Nur die on_exam Die Tabelle hat einen zusätzlichen Wert:grade.
Ja, dieses Modell ist sehr einfach. Wir könnten noch viele weitere Details zu Studierenden, Dozenten und Lehrveranstaltungen hinzufügen. Wir könnten historische Werte speichern, wenn Datensätze aktualisiert oder gelöscht werden. Dennoch wird dieses Modell für die Zwecke dieses Artikels ausreichen.
Erstellen einer Datenbank
Wir sind bereit, eine Datenbank auf unserem lokalen Server zu erstellen und zu untersuchen, was darin passiert. Wir exportieren das Modell (in Vertabelo) mit dem „Generate SQL script " Taste.
Dann erstellen wir eine Datenbank auf der MySQL Server-Instanz. Ich habe meine Datenbank „classes_and_students“ genannt “.
Als nächstes müssen wir ein zuvor generiertes SQL-Skript ausführen.
Jetzt haben wir die Datenbank mit all ihren Objekten (Tabellen, Primär- und Fremdschlüssel, Alternativschlüssel).
Datenbankgröße
Nachdem das Skript ausgeführt wurde, werden Daten über die „classes and students ” Datenbank wird im INFORMATION_SCHEMA gespeichert Datenbank. Diese Daten befinden sich in vielen verschiedenen Tabellen. Ich werde sie hier nicht alle noch einmal auflisten; das haben wir im vorigen Artikel gemacht.
Sehen wir uns an, wie wir Standard-SQL auf dieser Datenbank verwenden können. Ich beginne mit einer sehr wichtigen Abfrage:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Wir fragen nur die INFORMATION_SCHEMA.TABLES Tabelle hier. Diese Tabelle sollte uns mehr als genug Details über alle Tabellen auf dem Server geben. Bitte beachten Sie, dass ich nur Tabellen aus den „classes_and_students " Datenbank mit dem SET Variable in der ersten Zeile und später diesen Wert in der Abfrage verwenden. Die meisten Tabellen enthalten die Spalten TABLE_NAME und TABLE_SCHEMA , die die Tabelle und das Schema/die Datenbank bezeichnen, zu der diese Daten gehören.
Diese Abfrage gibt die aktuelle Größe unserer Datenbank und den für unsere Datenbank reservierten freien Speicherplatz zurück. Hier ist das tatsächliche Ergebnis:

Wie erwartet beträgt die Größe unserer leeren Datenbank weniger als 1 MB und der reservierte freie Speicherplatz ist viel größer.
Tabellengrößen und Eigenschaften
Als nächstes wäre es interessant, sich die Größen der Tische in unserer Datenbank anzusehen. Dazu verwenden wir die folgende Abfrage:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Die Abfrage ist fast identisch mit der vorherigen, mit einer Ausnahme:Das Ergebnis wird auf Tabellenebene gruppiert.
Hier ist ein Bild des von dieser Abfrage zurückgegebenen Ergebnisses:
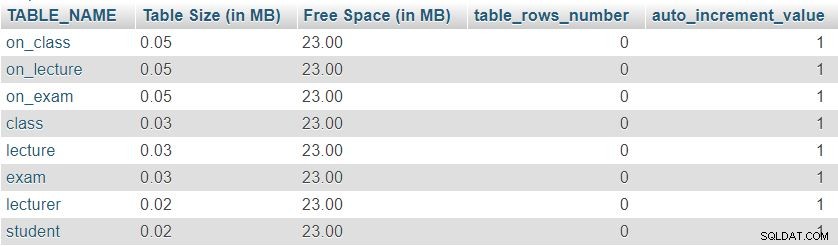
Zunächst können wir feststellen, dass alle acht Tabellen eine minimale "Tabellengröße" haben reserviert für die Tabellendefinition, die die Spalten, den Primärschlüssel und den Index enthält. Der "Freiplatz" wird gleichmäßig auf alle Tabellen verteilt.
Wir können auch die Anzahl der Zeilen sehen, die sich derzeit in jeder Tabelle befinden, und den aktuellen Wert von auto_increment Eigenschaft für jede Tabelle. Da alle Tabellen komplett leer sind, haben wir keine Daten und auto_increment auf 1 gesetzt (ein Wert, der der nächsten eingefügten Zeile zugewiesen wird).
Primärschlüssel
Für jede Tabelle sollte ein Primärschlüsselwert definiert sein, daher ist es ratsam zu prüfen, ob dies für unsere Datenbank gilt. Eine Möglichkeit, dies zu tun, besteht darin, eine Liste aller Tabellen mit einer Liste von Einschränkungen zu verknüpfen. Dies sollte uns die Informationen geben, die wir brauchen.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
Wir haben auch die INFORMATION_SCHEMA.COLUMNS Tabelle in dieser Abfrage. Während der erste Teil der Abfrage einfach alle Tabellen in der Datenbank zurückgibt, ist der zweite Teil (nach LEFT JOIN ) zählt die Anzahl der PRIs in diesen Tabellen. Wir haben LEFT JOIN verwendet weil wir sehen wollen, ob eine Tabelle 0 PRI in den COLUMNS hat Tabelle.
Wie erwartet enthält jede Tabelle in unserer Datenbank genau eine Primärschlüsselspalte (PRI).
„Inseln“?
„Inseln“ sind Tabellen, die vollständig vom Rest des Modells getrennt sind. Sie treten auf, wenn eine Tabelle keine Fremdschlüssel enthält und in keiner anderen Tabelle referenziert wird. Dies sollte wirklich nicht passieren, es sei denn, es gibt einen wirklich guten Grund, z. wenn Tabellen Parameter enthalten oder Ergebnisse oder Berichte innerhalb des Modells speichern.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Was ist die Idee hinter dieser Abfrage? Nun, wir verwenden den INFORMATION_SCHEMA.KEY_COLUMN_USAGE table, um zu testen, ob eine Spalte in der Tabelle ein Verweis auf eine andere Tabelle ist oder ob eine Spalte als Verweis in einer anderen Tabelle verwendet wird. Der erste Teil der Abfrage wählt alle Tabellen aus. Nach dem ersten LEFT JOIN zählen wir, wie oft eine Spalte aus dieser Tabelle als Referenz verwendet wurde. Nach dem zweiten LEFT JOIN zählen wir, wie oft eine Spalte dieser Tabelle auf eine andere Tabelle verwiesen hat.
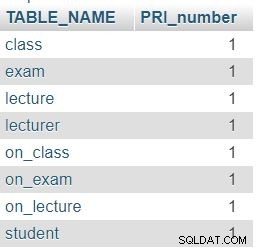
Das zurückgegebene Ergebnis ist:
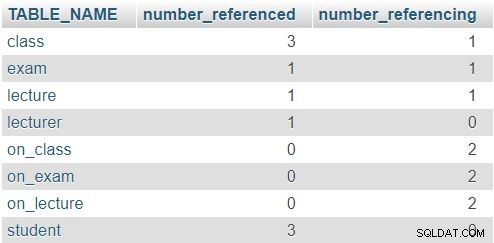
In der Zeile für die class Tabelle, die Zahlen 3 und 1 zeigen an, dass diese Tabelle dreimal referenziert wurde (in der lecture , exam und on_class Tabellen) und dass es ein Attribut enthält, das auf eine andere Tabelle verweist (lecturer_id ). Die anderen Tabellen folgen einem ähnlichen Muster, obwohl die tatsächlichen Zahlen natürlich anders sein werden. Hier gilt die Regel, dass keine Zeile in beiden Spalten eine 0 haben darf.
Zeilen hinzufügen
Bisher ist alles wie erwartet gelaufen. Wir haben unser Datenmodell erfolgreich von Vertabelo auf den lokalen MySQL-Server importiert. Alle Tabellen enthalten Schlüssel, so wie wir es wollen, und alle Tabellen sind miteinander verbunden – es gibt keine „Inseln“ in unserem Modell.
Jetzt fügen wir einige Zeilen in unsere Tabellen ein und verwenden die zuvor demonstrierten Abfragen, um die Änderungen in unserer Datenbank zu verfolgen.
Nachdem wir 1.000 Zeilen in der Dozententabelle hinzugefügt haben, führen wir erneut die Abfrage aus „Table Sizes and Properties“ aus " Sektion. Es wird das folgende Ergebnis zurückgegeben:
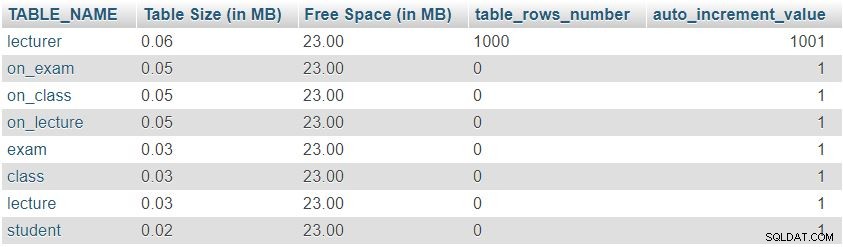
Wir können leicht feststellen, dass sich die Anzahl der Zeilen und die auto_increment-Werte wie erwartet geändert haben, aber es gab keine signifikante Änderung der Tabellengröße.
Dies war nur ein Testbeispiel; In realen Situationen würden wir signifikante Veränderungen bemerken. Die Anzahl der Zeilen ändert sich drastisch in Tabellen, die von Benutzern oder automatisierten Prozessen gefüllt werden (d. h. Tabellen, die keine Wörterbücher sind). Das Überprüfen der Größe und Werte in solchen Tabellen ist eine sehr gute Möglichkeit, unerwünschtes Verhalten schnell zu finden und zu korrigieren.
Möchten Sie teilen?
Die Arbeit mit Datenbanken ist ein ständiges Streben nach optimaler Leistung. Um bei dieser Verfolgung erfolgreicher zu sein, sollten Sie jedes verfügbare Tool verwenden. Heute haben wir einige Abfragen gesehen, die in unserem Kampf um bessere Leistung nützlich sind. Haben Sie sonst noch etwas Nützliches gefunden? Haben Sie mit dem INFORMATION_SCHEMA gespielt Datenbank vorher? Teilen Sie Ihre Erfahrungen in den Kommentaren unten.