Jeder Datenbankarchitekt, der eine MySQL-Datenbank entwirft, steht vor dem Problem, die richtige Speicher-Engine auszuwählen. Normalerweise verwendet eine Anwendung nur eine Engine:MyISAM oder InnoDB . Aber lassen Sie uns versuchen, etwas flexibler zu sein und uns vorstellen, wie verschiedene Speicher-Engines verwendet werden können.
Das anfängliche Datenmodell
Lassen Sie uns zunächst ein vereinfachtes Datenmodell für ein CRM-System (Customer Relationship Management) erstellen, das wir verwenden werden, um den Punkt zu veranschaulichen. Das Design wird die wichtigsten CRM-Funktionen abdecken:Verkaufsdaten, Produktdefinitionen und Informationen für Analysen. Es enthält keine Details, die normalerweise in CRM-Systemen verwendet werden.
Wie Sie sehen können, enthält dieses Datenmodell Tabellen, die Transaktionsinformationen namens sale und sale_item . Wenn ein Kunde etwas kauft, erstellt die Anwendung eine neue Zeile im sale Tisch. Jedes gekaufte Produkt wird im sale_item Tisch. Eine zugehörige Tabelle, sale_status , dient zum Speichern möglicher Status (z. B. ausstehend, abgeschlossen usw.).
Das product Tabelle speichert Informationen über Waren. Es definiert jedes Produkt und seine grundlegenden Deskriptoren. In einem detaillierteren Diagramm würde ich weitere Tabellen hinzufügen, um die Produktspezifikation und -kategorisierung zu handhaben. Aber für unsere aktuellen Anforderungen ist das nicht notwendig.
Die Kundentabelle enthält Daten über Kunden. Dies ist ein integraler Bestandteil jedes CRM-Systems und verfolgt normalerweise die individuellen Aktivitäten aller Benutzer. Offensichtlich enthält es oft wirklich detaillierte Informationen. Aber wie ich angemerkt habe, brauchen wir diese Details im Moment nicht.
Das log Tabelle speichert, was jeder Kunde innerhalb der Anwendung getan hat. Und der report_sales Die Tabelle ist für die Verwendung von Datenanalysen konzipiert.
Als Nächstes beschreibe ich die MySQL-Speicher-Engines, die möglicherweise in diesem Design verwendet werden könnten. Und später besprechen wir, welche Engine für welchen Tischtyp geeignet ist.
Ein Überblick über MySQL-Speicher-Engines
Eine Speicher-Engine ist ein Softwaremodul, das MySQL verwendet, um Daten aus einer Datenbank zu erstellen, zu lesen oder zu aktualisieren. Es wird nicht empfohlen, eine Engine zufällig auszuwählen, aber viele Entwickler verwenden gerne entweder MyISAM oder InnoDB, obwohl auch andere Optionen verfügbar sind. Jeder Motor hat seine eigenen Vor- und Nachteile, und die richtige Motorauswahl hängt von mehreren Faktoren ab. Werfen wir einen Blick auf die beliebtesten Engines.
- MyISAM hat eine lange Geschichte mit MySQL. Es war die Standard-Engine für MySQL-Datenbanken vor der Version 5.5. MyISAM unterstützt keine Transaktionen und hat nur Sperren auf Tabellenebene. Es wird hauptsächlich für leseintensive Anwendungen verwendet.
- InnoDB ist eine allgemeine Speicher-Engine, die hohe Zuverlässigkeit und gute Leistung in Einklang bringt. Es unterstützt Transaktionen, Sperren auf Zeilenebene, die Wiederherstellung nach einem Absturz und die Steuerung des gleichzeitigen Zugriffs auf mehrere Versionen. Außerdem bietet es eine Einschränkung der referenziellen Integrität von Fremdschlüsseln.
- Die Erinnerung Engine speichert alle Daten im RAM. Es kann zum Speichern von Suchreferenzen verwendet werden.
- Eine andere Engine, CSV , speichert Daten in Textdateien mit kommagetrennten Werten. Dieses Format wird hauptsächlich für die Integration mit anderen Systemen verwendet.
- Zusammenführen ist eine gute Wahl für Berichtssysteme, z. B. im Data Warehousing. Es erlaubt die logische Gruppierung einer Menge identischer MyISAM-Tabellen, die auch als ein Objekt referenziert werden können.
- Archivieren ist für das Hochgeschwindigkeits-Kuvertieren optimiert. Es speichert Informationen in kompakten, nicht indizierten Tabellen und unterstützt keine Transaktionen. Die Archive-Speicher-Engine ist ideal für die Aufbewahrung großer Mengen selten referenzierter historischer oder archivierter Daten.
- Der Föderierte engine bietet die Möglichkeit, MySQL-Server zu trennen oder aus vielen physischen Servern eine logische Datenbank zu erstellen. In den lokalen Tabellen werden keine Daten gespeichert und Abfragen werden automatisch in den entfernten (verbundenen) Tabellen ausgeführt.
- Das Schwarze Loch Engine fungiert als „schwarzes Loch“, das Daten akzeptiert, aber nicht speichert. Alle Auswahlen geben einen leeren Datensatz zurück.
- Die Engine Beispiel wird verwendet, um zu zeigen, wie neue Speicher-Engines entwickelt werden.
Dies ist keine vollständige Liste der Speicher-Engines. MySQL 5.x unterstützt neun davon direkt aus der Box, plus Dutzende weitere, die von der MySQL-Community entwickelt wurden. Weitere Details zu Speicher-Engines finden Sie in der offiziellen Dokumentation von MySQL.
Aktualisierung des Datenmodelldesigns
Sehen Sie sich noch einmal unser Datenmodell an. Offensichtlich werden verschiedene Tabellen auf unterschiedliche Weise verwendet. Der sale Tabelle muss Transaktionen unterstützen. Andererseits das log und report_sales Tabellen erfordern diese Funktion nicht. Die Hauptaufgabe des log table speichert Daten mit maximaler Effizienz. Schnelles Auffinden ist die Hauptanforderung für den report_sales Tisch.
Denken wir an die obigen Punkte und ändern unser Datenbankschema. In Vertabelo können Sie die „Speicher-Engine“ in den Tabelleneigenschaften einstellen Tafel. Bitte sehen Sie sich die Bilder unten an.

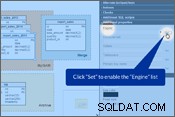
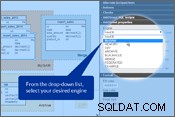
Festlegen der Speicher-Engine
Sehen wir uns also das aktualisierte Datenbankdesign an.
Ich habe Speicher-Engines für vorhandene Tabellen angegeben und den report_sales Tisch. Wie Sie sehen können, sind die Tabellen in drei Gruppen unterteilt:
- Transaktionstabellen, die mit der Hauptanwendung verwendet werden
- Berichtstabellen für BI-Analysen
- Log-Tabelle zum Speichern aller Benutzeraktivitäten
Lassen Sie uns über alle einzeln sprechen.
Transaktionstabellen
Diese Tabellen enthalten Daten, die von Benutzern während des täglichen Routinebetriebs eingegeben werden. In unserem Fall wären Verkaufsinformationen wie:
- welcher Mitarbeiter den Verkauf getätigt hat
- wer das Produkt gekauft hat
- was verkauft wurde
- wie viel es gekostet hat
In den meisten Fällen ist InnoDB die beste Lösung für Transaktionstabellen. Diese Speicher-Engine unterstützt das Sperren von Zeilen, und einige Benutzer können zusammenarbeiten. Ebenso erlaubt InnoDB die Verwendung von Transaktionen und Fremdschlüsseln. Aber wie Sie wissen, sind diese Vorteile nicht kostenlos; Die Engine führt möglicherweise ausgewählte Anweisungen langsamer aus als MyISAM und speichert Daten mit weniger Effizienz als Archive.
Alle oben beschriebenen Engines verfügen über einige Schutzmaßnahmen, sodass Entwickler nicht für jede Operation komplexe Rollback-Funktionen schreiben müssen. In einer typischen Vertriebsanwendung ist die Wahrung der Datenkonsistenz wichtiger als mögliche Leistungsprobleme.
Berichtstabellen
Im neuen Design habe ich einen Tisch in mehrere kleinere Tische unterteilt. Dies spart Aufwand bei der Datenverwaltung und der Tabellen- und Indexpflege. Es ermöglicht uns auch, die MERGE-Tabelle sale_report zum Kombinieren anderer Berichtstabellen. Als Ergebnis ruft das BI-Tool immer noch Daten aus einer riesigen Tabelle ab (für Analysezwecke), aber wir haben den Vorteil, mit kleineren Tabellen zu arbeiten.
Der Report_sale_{year} Tabellen sind MyISAM-Tabellen. Diese Speicher-Engine unterstützt keine Transaktionen und kann nur die Tabelle als Ganzes sperren. Da sich MyISAM nicht um diese komplexen Elemente kümmert, führt es Datenmanipulationsvorgänge mit hoher Geschwindigkeit durch. Aufgrund seiner Dateistruktur liest diese Speicher-Engine Daten schneller als die beliebtere InnoDB.
Die Protokolltabelle
Die Archive-Speicher-Engine ist eine gute Wahl zum Speichern von Protokolldaten. Es kann Zeilen einfügen und gespeicherte Daten schnell komprimieren. Das Aufbewahren von Informationen über Benutzeraktivitäten bietet große Vorteile. Das Archiv hat jedoch einige Einschränkungen. Es unterstützt keine Aktualisierungsvorgänge und ruft Daten langsam ab. Aber in einer Protokolltabelle sind die beschriebenen Vorteile wichtiger als die Nachteile.
Speicher-Engines integrieren
Jedes System muss mit dem externen Leben integriert werden. Bei Anwendungen können dies Benutzer sein, die Referenz- und Transaktionstabellen füllen. Das können Dienste und Integrationen über REST, SOAP, WCF oder ähnliches sein. Und nicht zuletzt kann es die Datenbankintegration sein.
MySQL und Oracle haben zwei wirklich hilfreiche Speicher-Engines entwickelt:Federated und CSV . Die erste, Federated , sollte zum Laden von Daten aus einer externen MySQL-Datenbank verwendet werden. Die zweite Speicher-Engine, CSV , ermöglicht es Datenbanken, Datensätze im CSV-Format zu speichern und kommagetrennte Dateien on air zu lesen, ohne zusätzlichen Aufwand.
Wie Sie sehen können, verleiht die Verwendung verschiedener Speicher-Engines für unterschiedliche Zwecke Ihrer Datenbank mehr Flexibilität. Wenn ein Datenbankarchitekt seine Entscheidung nach Abwägung aller Vor- und Nachteile trifft, kann das Ergebnis wirklich beeindruckend sein.
Haben Sie Erfahrung mit der Verwendung verschiedener Speicher-Engines im Datenbankdesign? Ich würde gerne eure Tipps und Vorschläge sehen. Bitte teilen Sie sie im Kommentarbereich.