Die Implementierung einer benutzerfreundlichen Suche kann schwierig, aber auch sehr effizient sein. Woher weiß ich das? Vor nicht allzu langer Zeit musste ich eine Suchmaschine in einer mobilen App implementieren. Die App wurde auf dem Ionic-Framework erstellt und würde sich mit einem CakePHP 2-Backend verbinden. Die Idee war, Ergebnisse anzuzeigen, während der Benutzer tippt. Dafür gab es mehrere Optionen, aber nicht alle erfüllten die Anforderungen meines Projekts.
Um zu veranschaulichen, was diese Art von Aufgabe beinhaltet, stellen wir uns vor, nach Songs und ihren möglichen Beziehungen (wie Künstler, Alben usw.) zu suchen.
Die Datensätze müssten nach Relevanz sortiert werden, die davon abhängen würde, ob das Suchwort mit Feldern aus dem Datensatz selbst oder aus anderen Spalten in zugehörigen Tabellen übereinstimmt. Außerdem sollte die Suche zumindest einige grundlegende Wortstämme implementieren. (Stämme werden verwendet, um die Stammform für ein Wort zu erhalten. „Stämme“, „Stemmer“, „Stämme“ und „Stämme“ haben alle denselben Stamm:„Stamm“.)
Der hier vorgestellte Ansatz wurde mit mehreren hunderttausend Datensätzen getestet und konnte während der Eingabe des Benutzers nützliche Ergebnisse abrufen.
Zu berücksichtigende Produkte für die Volltextsuche
Es gibt mehrere Möglichkeiten, wie wir diese Art der Suche implementieren könnten. Unser Projekt hatte einige Einschränkungen in Bezug auf Zeit und Serverressourcen, daher mussten wir die Lösung so einfach wie möglich halten. Schließlich tauchten ein paar Konkurrenten auf:
Elasticsearch
Elasticsearch bietet Volltextsuche in einem dokumentenorientierten Dienst. Es wurde entwickelt, um große Mengen an Last auf verteilte Weise zu verwalten:Es kann Ergebnisse nach Relevanz ordnen, Aggregationen durchführen und mit Wortstämmen und arbeiten Synonyme. Dieses Tool ist für Echtzeitsuchen gedacht. Von ihrer Website:
Elasticsearch baut verteilte Funktionen auf Apache Lucene auf, um die leistungsstärksten verfügbaren Volltextsuchfunktionen bereitzustellen. Leistungsstarke, entwicklerfreundliche Abfrage-API unterstützt mehrsprachige Suche, Geolokalisierung, kontextbezogene „Meinten Sie“-Vorschläge, automatische Vervollständigung und Ergebnisausschnitte.
Elasticsearch kann als REST-Service arbeiten, auf HTTP-Anfragen antworten und sehr schnell eingerichtet werden. Um die Engine als Dienst zu starten, müssen Sie jedoch über einige Serverzugriffsrechte verfügen. Und wenn Ihr Hosting-Provider Elasticsearch nicht standardmäßig unterstützt, müssen Sie einige Pakete installieren.
Das Fazit ist, dass dieses Produkt eine großartige Option ist, wenn Sie eine felsenfeste Suchlösung wünschen. (Hinweis:Möglicherweise benötigen Sie einen VPS oder einen dedizierten Server, da die Hardwareanforderungen ziemlich hoch sind.)
Sphinx
Wie Elasticsearch bietet auch Sphinx ein sehr solides Produkt für die Volltextsuche:Craigslist bedient damit mehr als 300.000.000 Abfragen pro Tag. Sphinx bietet keine native RESTful-Schnittstelle. Es ist in C implementiert und benötigt weniger Hardware als Elasticsearch (das in Java implementiert ist und auf jedem Betriebssystem mit jvm ausgeführt werden kann). Sie benötigen außerdem Root-Zugriff auf den Server mit dediziertem RAM/CPU, um Sphinx ordnungsgemäß auszuführen.
MySQL-Volltextsuche
In der Vergangenheit wurden Volltextsuchen in MyISAM-Engines unterstützt. Ab Version 5.6 unterstützte MySQL auch die Volltextsuche in InnoDB-Speicher-Engines. Dies waren großartige Neuigkeiten, da Entwickler von der referenziellen Integrität von InnoDB, der Fähigkeit zur Durchführung von Transaktionen und Sperren auf Zeilenebene profitieren können.
Es gibt grundsätzlich zwei Ansätze für die Volltextsuche in MySQL:natürliche Sprache und boolescher Modus. (Eine dritte Option erweitert die Suche in natürlicher Sprache um eine zweite Erweiterungsabfrage.)
Der Hauptunterschied zwischen dem natürlichen und dem booleschen Modus besteht darin, dass der boolesche Modus bestimmte Operatoren als Teil der Suche zulässt. Beispielsweise können boolesche Operatoren verwendet werden, wenn ein Wort eine größere Relevanz als andere in der Abfrage hat oder wenn ein bestimmtes Wort in den Ergebnissen vorhanden sein soll usw. Es ist erwähnenswert, dass die Ergebnisse in beiden Fällen nach der berechneten Relevanz sortiert werden können MySQL während der Suche.
Die Entscheidungen treffen
Die beste Lösung für unser Problem war die Verwendung der InnoDb-Volltextsuche im booleschen Modus. Wieso den?
- Wir hatten wenig Zeit, um die Suchfunktion zu implementieren.
- Zu diesem Zeitpunkt hatten wir weder große Datenmengen zu verarbeiten noch eine massive Last, die etwas wie Elasticsearch oder Sphinx erforderte.
- Wir haben Shared Hosting verwendet, das weder Elasticsearch noch Sphinx unterstützt, und die Hardware war zu diesem Zeitpunkt ziemlich begrenzt.
- Während wir Wortstamm in unserer Suchfunktion wollten, war es kein Deal Breaker:Wir konnten es (innerhalb von Einschränkungen) durch einfache PHP-Codierung und Datendenormalisierung implementieren
- Volltextsuchen im booleschen Modus können Wörter mit Platzhaltern (für die Wortstammung) suchen und die Ergebnisse nach Relevanz sortieren.
Volltextsuche im booleschen Modus
Wie bereits erwähnt, ist die Suche in natürlicher Sprache der einfachste Ansatz:Suchen Sie einfach nach einer Phrase oder einem Wort in den Spalten, in denen Sie einen Volltextindex festgelegt haben, und Sie erhalten nach Relevanz sortierte Ergebnisse.
Im normalisierten Vertabelo-Modell
Mal sehen, wie eine einfache Suche funktionieren würde. Zuerst erstellen wir eine Beispieltabelle:
-- Erstellt von Vertabelo (https://vertabelo.com)-- Datum der letzten Änderung:2016-04-25 15:01:22.153-- tables-- Tabelle:artistsCREATE TABLE artists ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE VOLLTEXTINDEX artist_idx_1 ON artist (name);-- End of file.
Im natürlichen Sprachmodus
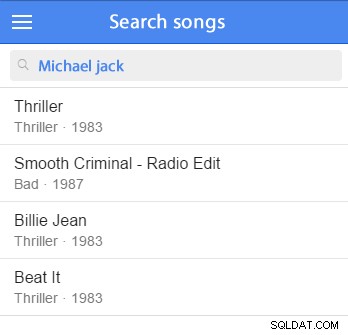
Sie können einige Beispieldaten einfügen und mit dem Testen beginnen. (Es wäre gut, es zu Ihrem Beispieldatensatz hinzuzufügen.) Zum Beispiel versuchen wir, nach Michael Jackson zu suchen:
WÄHLEN SIE *FROM artistWHERE MATCH (artists.name) GEGEN ('Michael Jackson' IN NATURAL LANGUAGE MODE) Diese Abfrage findet Datensätze, die mit den Suchbegriffen übereinstimmen, und sortiert übereinstimmende Datensätze nach Relevanz; Je besser die Übereinstimmung, desto relevanter ist sie und desto höher erscheint das Ergebnis in der Liste.
Im booleschen Modus
Wir können die gleiche Suche im booleschen Modus durchführen. Wenn wir keine Operatoren auf unsere Abfrage anwenden, besteht der einzige Unterschied darin, dass die Ergebnisse nicht sind sortiert nach Relevanz:
SELECT *FROM artistWHERE MATCH (artists.name) AGAINST ('Michael Jackson' IN BOOLEAN MODE) Der Wildcard-Operator im booleschen Modus
Da wir nach Wortstämmen und Teilwörtern suchen möchten, benötigen wir den Platzhalteroperator (*). Dieser Operator kann in Suchvorgängen im booleschen Modus verwendet werden, weshalb wir diesen Modus gewählt haben.
Lassen Sie uns also die Kraft der booleschen Suche entfesseln und versuchen, nach einem Teil des Namens des Künstlers zu suchen. Wir verwenden den Wildcard-Operator, um alle Künstler abzugleichen, deren Name mit „Mich“ beginnt:
SELECT *FROM artistWHERE MATCH (name) AGAINST ('Mich*' IN BOOLEAN MODE) Sortierung nach Relevanz im booleschen Modus
Sehen wir uns nun die berechnete Relevanz für die Suche an. Dies wird uns helfen, die Sortierung zu verstehen, die wir später mit Cake durchführen werden:
SELECT *, MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE) AS rankFROM artistWHERE MATCH (name) AGAINST ('mich*' IN BOOLEAN MODE)ORDER BY rank DESC Diese Abfrage ruft Suchübereinstimmungen und den Relevanzwert ab, den MySQL für jeden Datensatz berechnet. Der Engine-Optimierer erkennt, dass wir die Relevanz auswählen, sodass er sich nicht die Mühe macht, den Rang neu zu berechnen.
Wortstamm in der Volltextsuche
Wenn wir Wortstämme in eine Suche integrieren, wird die Suche benutzerfreundlicher. Auch wenn das Ergebnis kein Wort an sich ist, versuchen Algorithmen, für abgeleitete Wörter dieselbe Wurzel zu erzeugen. Zum Beispiel ist der Stamm „argu“ kein englisches Wort, aber er kann als Stamm für „argue“, „argued“, „argues“, „arguing“, „Argus“ und andere Wörter verwendet werden.
Stemming verbessert die Ergebnisse, da der Benutzer möglicherweise ein Wort eingibt, das keine genaue Übereinstimmung hat, aber sein „Stamm“. Obwohl PHP-Stemmer oder Python-Stemmer von Snowball eine Option sein könnten (wenn Sie Root-SSH-Zugriff auf Ihren Server haben), verwenden wir die Klasse PorterStemmer.php.
Diese Klasse implementiert den von Martin Porter vorgeschlagenen Algorithmus, um englische Wörter zu stammeln. Wie vom Autor auf seiner Website angegeben, kann es für jeden Zweck kostenlos verwendet werden. Ziehen Sie die Datei einfach in Ihr Vendors-Verzeichnis in CakePHP, schließen Sie die Bibliothek in Ihr Modell ein und rufen Sie die statische Methode auf, um ein Wort zu erstellen:
//Bibliothek (sollte PorterStemmer.php heißen) in den Vendors-Ordner von CakePHP einschließenApp::import('Vendor', 'PorterStemmer'); //ein Wort stammeln (Wörter müssen einzeln gestammt werden)echo PorterStemmer::Stem(‘stemming’); //Ausgabe ist „stem“ Unser Ziel ist es, die Suche schnell und effizient zu gestalten und Ergebnisse nach ihrer Volltextrelevanz sortieren zu können. Dazu müssen wir Wortstämme auf zwei Arten anwenden:
- Die vom Benutzer eingegebenen Wörter
- Songbezogene Daten (die wir in Spalten speichern und nach Relevanz sortieren)
Die erste Art der Wortstammbildung kann wie folgt erreicht werden:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /unerwünschte Zeichen entfernen$words =explode(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ Wort) . "* ";//Wir fügen den Platzhalter nach jedem Wort hinzu $unstemmedSearch =$word . "* ";//um die Künstlerspalte zu suchen, die nicht gestemmt ist}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //Andernfalls wird sich mySql beschweren, da Sie den Platzhalter nicht alleine verwenden können $stemmedSearch =""; $unstemmedSearch ="";} Wir haben zwei Zeichenfolgen erstellt:eine zum Suchen nach dem Künstlernamen (ohne Wortstamm) und eine zum Suchen in den anderen Spalten mit Wortstamm. Dies wird uns später dabei helfen, unser „Gegen“ aufzubauen Teil der Volltextabfrage. Sehen wir uns nun an, wie wir die Daten des Songs sammeln und sortieren können.
Songdaten denormalisieren
Unsere Sortierkriterien basieren darauf, zuerst den Interpreten des Songs (ohne Stemming) zu finden. Als nächstes werden der Name des Songs, das Album und verwandte Kategorien angezeigt. Stemming wird für alle sekundären Suchkriterien verwendet.
Nehmen wir zur Veranschaulichung an, ich suche nach „Nirvana“ und es gibt ein Lied namens „Nirvana Games“ von „XYZ“ und ein weiteres Lied namens „Polly“ des Künstlers „Nirvana“. Die Ergebnisse sollten „Polly“ zuerst auflisten, da die Übereinstimmung mit dem Künstlernamen wichtiger ist als eine Übereinstimmung mit dem Songnamen (basierend auf den Kriterien).
Dazu habe ich 4 Felder in den songs Tabelle, eine für jedes gewünschte Such-/Sortierkriterium:
ALTER TABLE `songs` ADD `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255) NOT NULL AFTER` denorm_trackname`,ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Unser vollständiges Datenbankmodell würde so aussehen:
Immer wenn Sie einen Song mit Hinzufügen/Bearbeiten in CakePHP speichern, müssen Sie nur den Künstlernamen in der Spalte denorm_artist speichern ohne es einzudämmen. Fügen Sie als Nächstes den Titelnamen mit Stamm in denorm_trackname hinzu (ähnlich wie im Suchtext) und speichern Sie den Namen des Albums mit Stamm im denorm_album Säule. Speichern Sie schließlich die für den Song festgelegte gestemmte Kategorie in den denorm_categories Feld, Verketten der Wörter und Hinzufügen eines Leerzeichens zwischen jedem Kategoriennamen mit Stamm.
Volltextsuche und Relevanzsortierung in CakePHP
Fahren wir mit dem Beispiel der Suche nach „Nirvana“ fort und sehen wir uns an, was eine ähnliche Abfrage erreichen kann:
SELECT trackname, MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank1, MATCH(denorm_trackname) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank2, MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) als Rang 3, MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) as rank4 FROM songs WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR MATCH(denorm_trackname) AGAINST ('Nirvana*' ' IN BOOLEAN MODE) OR MATCH(denorm_album) AGAINST ('Nirvana*' IN BOOLEAN MODE) OR MATCH(denorm_categories) AGAINST ('Nirvana*' IN BOOLEAN MODE) ORDER BY rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC Wir würden die folgende Ausgabe erhalten:
| Titelname | Rang1 | Rang2 | Rang3 | Rang4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| Nirvana-Spiele | 0 | 0,0906190574169159 | 0 | 0 |
Dazu in CakePHP die find Die Methode muss mit einer Kombination aus den Parametern „fields“, „conditions“ und „order“ aufgerufen werden. Weiter mit dem früheren PHP-Beispielcode:
//innerhalb der Modelldatei Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE) as `rank1`", "MATCH(Song. denorm_trackname) GEGEN ({$stemmedSearch} IN BOOLEAN MODE) als `rank2`", "MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} IN BOOLEAN MODE) as `rank3`", "MATCH(Song.denorm_categories) AGAINST ( {$stemmedSearch} IN BOOLEAN MODE) as `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( „OR“ => array( „MATCH(Song.denorm_artist) AGAINST ({$unstemmedSearch} IN BOOLEAN MODE)“, „MATCH(Song.denorm_trackname) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)“, „MATCH(Song. denorm_album) GEGEN ({$stemmedSearch} IN BOOLEAN MODE)", "MATCH(Song.denorm_categories) AGAINST ({$stemmedSearch} IN BOOLEAN MODE)" ) );$results =$this->find ('all',array('conditions'=>$conditions,'fields'=>$fields,'order'=>$order); $Ergebnisse wird das Array von Songs sein, die nach den Kriterien sortiert sind, die wir zuvor definiert haben.
Mit dieser Lösung können für den Benutzer aussagekräftige Suchen generiert werden – ohne zu viel Zeit von den Entwicklern zu beanspruchen oder den Code erheblich zu komplizieren.
CakePHP-Suchen noch besser machen
Erwähnenswert ist, dass das „Würzen“ der denormalisierten Spalten mit mehr Daten zu besseren Ergebnissen führen kann.
Mit „Würzen“ meine ich, dass Sie in die denormalisierten Spalten mehr Daten aus zusätzlichen Spalten aufnehmen können, die Sie für nützlich halten, um die Ergebnisse relevanter zu machen, z. B. wenn Sie wüssten, dass das Land eines Künstlers in den Suchbegriffen vorkommen könnte, Sie könnte das Land zusammen mit dem Künstlernamen in denorm_artist hinzufügen Säule. Dies würde die Qualität der Suchergebnisse verbessern.
Aus meiner Erfahrung (abhängig von den tatsächlichen Daten, die Sie verwenden, und den Spalten, die Sie denormalisieren) sind die obersten Ergebnisse in der Regel sehr genau. Dies ist großartig für mobile Apps, da das Herunterscrollen einer langen Liste für den Benutzer frustrierend sein kann.
Wenn Sie schließlich mehr Daten aus den Tabellen erhalten müssen, auf die sich der Song bezieht, können Sie immer eine Verbindung herstellen und den Künstler, die Kategorien, Alben, Songkommentare usw. abrufen. Wenn Sie den Containable-Verhaltensfilter von CakePHP verwenden, würde ich schlagen vor, das EagerLoader-Plug-in hinzuzufügen, um die Verknüpfungen effizient auszuführen.
Wenn Sie Ihren eigenen Ansatz zur Implementierung der Volltextsuche haben, teilen Sie ihn bitte in den Kommentaren unten mit. Wir können alle von den Erfahrungen der anderen lernen.