Bei der Arbeit mit Personennamen und der Durchführung von Fuzzy-Lookups für sie funktionierte für mich die Erstellung einer zweiten Tabelle mit Wörtern. Erstellen Sie außerdem eine dritte Tabelle, die eine Schnitttabelle für die viele-zu-viele-Beziehung zwischen der Tabelle, die den Text enthält, und der Worttabelle ist. Wenn der Texttabelle eine Zeile hinzugefügt wird, teilen Sie den Text in Wörter auf und füllen die Schnittmengentabelle entsprechend aus, indem Sie bei Bedarf neue Wörter zur Worttabelle hinzufügen. Sobald diese Struktur vorhanden ist, können Sie Suchen etwas schneller durchführen, da Sie nur Ihre Damlev-Funktion über die Tabelle mit eindeutigen Wörtern ausführen müssen. Durch einfaches Verbinden erhalten Sie den Text, der die passenden Wörter enthält. 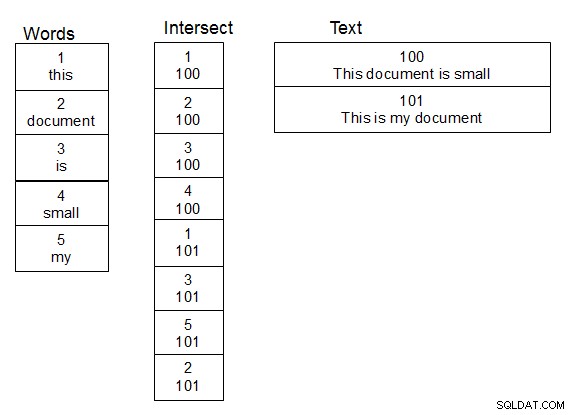
Eine Abfrage für eine einzelne Wortübereinstimmung würde in etwa so aussehen:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
und zwei Wörter würden so aussehen (aus dem Kopf, also vielleicht nicht ganz richtig):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Die Vorteile bestehen hier, auf Kosten von etwas Datenbankplatz, darin, dass Sie die zeitaufwändige Damlev-Funktion nur auf die eindeutigen Wörter anwenden müssen, die wahrscheinlich nur in die Zehntausende gehen werden, unabhängig von der Größe Ihrer Texttabelle. Dies ist wichtig, da die damlev-UDF keine Indizes verwendet – sie scannt die gesamte Tabelle, auf die sie angewendet wird, um einen Wert für jede Zeile zu berechnen. Das Scannen nur der eindeutigen Wörter sollte viel schneller sein. Der andere Vorteil ist, dass der Damlev auf der Wortebene angewendet wird, was anscheinend das ist, wonach Sie fragen. Ein weiterer Vorteil besteht darin, dass Sie die Abfrage erweitern können, um die Suche nach mehreren Wörtern zu unterstützen, und die Ergebnisse ordnen können, indem Sie die übereinstimmenden sich überschneidenden Zeilen auf TextId gruppieren und nach der Anzahl der Übereinstimmungen ordnen.