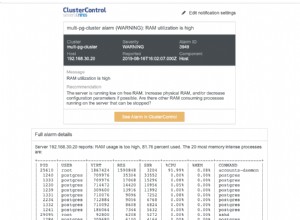
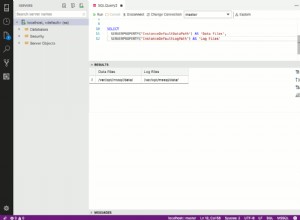
Sie verwechseln UTF-8 mit Unicode.
0x00FC ist der Unicode Codepunkt für ü:
mysql> select char(0x00FC using ucs2);
+----------------------+
| char(0x00FC using ucs2) |
+----------------------+
| ü |
+----------------------+
In UTF-8 Codierung, 0x00FC wird durch zwei Bytes dargestellt :
mysql> select char(0xC3BC using utf8);
+-------------------------+
| char(0xC3BC using utf8) |
+-------------------------+
| ü |
+-------------------------+
UTF-8 ist lediglich eine Art der Codierung Unicode-Zeichen im Binärformat. Es soll platzsparend sein, weshalb ASCII-Zeichen nur ein einzelnes Byte benötigen und iso-8859-1-Zeichen wie ü nur zwei Bytes. Einige andere Zeichen benötigen drei oder vier Bytes, sind aber viel seltener.