Ich stimme Klennepette und Brian zu - mit ein paar Vorbehalten.
Wenn Ihre Daten von Natur aus relational sind und Abfragen unterliegen, die gut mit SQL funktionieren, sollten Sie in der Lage sein, ohne exotische Hardwareanforderungen auf Hunderte von Millionen Datensätzen zu skalieren.
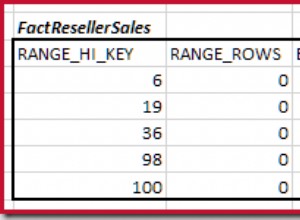
Sie müssen in Indizierung, Abfrageoptimierung und gelegentliche Opfer für das relationale Modell im Interesse der Geschwindigkeit investieren. Beim Entwerfen von Tabellen sollten Sie zumindest der Leistung nicken – zum Beispiel Integer gegenüber Strings für Schlüssel bevorzugen.
Wenn Sie jedoch dokumentzentrierte Anforderungen haben, eine Freitextsuche benötigen oder viele hierarchische Beziehungen haben, müssen Sie möglicherweise noch einmal nachsehen.
Wenn Sie ACID-Transaktionen benötigen, können Sie früher auf Skalierbarkeitsprobleme stoßen, als wenn Sie sich nicht um Transaktionen kümmern (obwohl dies in der Praxis wahrscheinlich immer noch keine Auswirkungen auf Sie hat). Wenn Sie langwierige oder komplexe Transaktionen haben, nimmt Ihre Skalierbarkeit ziemlich schnell ab.
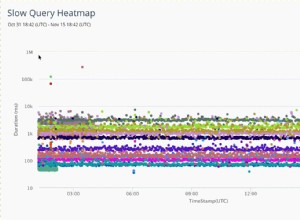
Ich würde empfehlen, das Projekt von Grund auf unter Berücksichtigung der Skalierbarkeitsanforderungen aufzubauen. In der Vergangenheit habe ich eine Testumgebung eingerichtet, die mit Millionen von Datensätzen gefüllt ist (ich habe DBMonster verwendet, bin mir aber nicht sicher, ob es das noch gibt), und in Arbeit befindlichen Code regelmäßig gegen diese Datenbank mit Lasttest-Tools wie getestet Jmeter.