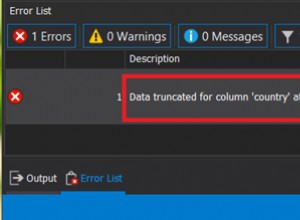
select
p.ID,
e.NAME
from
Paychecks p
inner join Employee e on p.EmployeeID = e.ID
group by
p.ID
order by
max(p.AmountPaid) desc
Eine andere Schreibweise, die logischer aussieht, aber möglicherweise langsamer ist (müssen Sie testen), ist:
select
e.ID,
e.NAME
from
Employee e
inner join Paychecks p on p.EmployeeID = e.ID
group by
e.ID
order by
max(p.AmountPaid) desc
Bei zig Millionen Zeilen wächst jede Abfrage manchmal langsam, aber mit den richtigen Indizes geht das so schnell wie es nur geht. Ich denke, Sie brauchen im Grunde genommen einen Index für Paychecks.EmployeeID und Paychecks.AmountPaid kombiniert. Und Index auf Employee.ID kann helfen.
Wenn Sie der Join am Ende umbringt, können Sie zwei Abfragen ausführen. Der erste verwendet nur die Gehaltsschecks, um sie nach EmployeeID zu gruppieren und sie nach dem Maximum (PaycheckAmount) zu ordnen, und ein zweiter kann verwendet werden, um die Namen für jede ID abzurufen. Manchmal kosten Beitritte mehr Leistung, als Sie möchten, und wenn Sie 10 Millionen Gehaltsschecks für 500 Mitarbeiter erhalten, ist es möglicherweise schneller, dies in zwei Schritten zu tun, obwohl dies bedeutet, dass sie im Durchschnitt seit etwa 1600 Jahren im Unternehmen arbeiten .;-)