Es gibt keinen Unterschied zwischen diesen beiden Anweisungen, und der Optimierer transformiert den IN zu = wenn IN enthält nur ein Element.
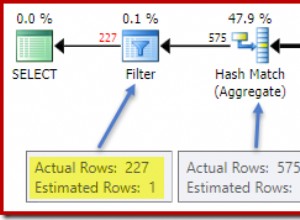
Wenn Sie jedoch eine Frage wie diese haben, führen Sie einfach beide Anweisungen aus, führen Sie ihren Ausführungsplan aus und sehen Sie sich die Unterschiede an. Hier - Sie werden keine finden.
Nach langer Online-Suche fand ich ein Dokument auf SQL, um dies zu unterstützen (ich nehme an, es gilt für alle DBMS):
Hier ist der Ausführungsplan beider Abfragen in Oracle (die meisten DBMS verarbeiten dies gleich):
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number = '123456789'
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
Und für IN() :
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number in('123456789');
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
Wie Sie sehen können, sind beide identisch. Dies ist in einer indizierten Spalte. Dasselbe gilt für eine nicht indizierte Spalte (nur vollständiger Tabellenscan).