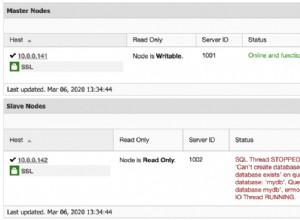
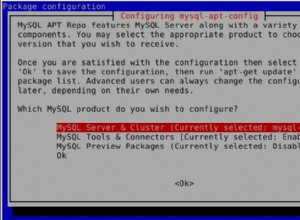
So habe ich es gemacht.
Ich habe ein unbenutztes Feld in patient wiederverwendet Tabelle, um nicht duplizierte (N), erste von duplizierten (X) und andere duplizierte Patienten (Y) zu markieren. Sie könnten dafür auch eine Spalte hinzufügen (und nach Gebrauch löschen).
Hier sind die Schritte, die ich befolgt habe, um meine Datenbank zu bereinigen:
/*1: List duplicated */
select pk,pat_id, t.`pat_id_issuer`, t.`pat_name`, t.pat_custom1
from patient t
where pat_id in (
select pat_id from (
select pat_id, count(*)
from patient
group by 1
having count(*)>1
) xxx);
/*2: Delete orphan patients */
delete from patient where pk not in (select patient_fk from study);
/*3: Reset flag for duplicated (or not) patients*/
update patient t set t.`pat_custom1`='N';
/*4: Mark all duplicated */
update patient t set t.`pat_custom1`='Y'
where pat_id in (
select pat_id from (
select pat_id, count(*)
from patient
group by 1
having count(*)>1
) xxx) ;
/*5: Unmark the 1st of the duplicated*/
update patient t
join (select pk from (
select min(pk) as pk, pat_id from patient
where pat_custom1='Y'
group by pat_id
) xxx ) x
on (x.pk=t.pk)
set t.`pat_custom1`='X'
where pat_custom1='Y'
;
/*6: Verify update is correct*/
select pk, pat_id,pat_custom1
from `patient`
where pat_custom1!='N'
order by pat_id, pat_custom1;
/*7: Verify studies linked to duplicated patient */
select p.* from study s
join patient p on (p.pk=s.patient_fk)
where p.pat_custom1='Y';
/*8: Relink duplicated patients */
update study s
join patient p on (p.pk=s.patient_fk)
set patient_fk = (select pk from patient pp
where pp.pat_id=p.pat_id and pp.pat_custom1='X')
where p.pat_custom1='Y';
/*9: Delete newly orphan patients */
delete from patient where pk not in (select patient_fk from study);
/* 10: reset flag */
update patient t set t.`pat_custom1`=null;
/* 11: Commit changes */
commit;
Es gibt sicherlich einen kürzeren Weg mit etwas intelligenterem (kompliziertem?) SQL, aber ich persönlich bevorzuge den einfachen Weg. Dadurch kann ich auch überprüfen, ob jeder Schritt das tut, was ich erwarte.