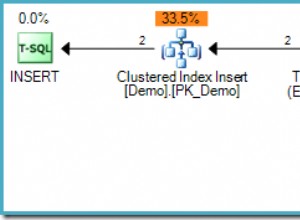
Es gibt viele Dinge zu beachten, aber im Allgemeinen würde ich die relationale Zuordnung in Ihrem Fall auf das Row Data Gateway stützen Muster (RDG). Wenn Sie nicht zu viele verschiedene Objekttypen haben, sollte dieser Architekturansatz gut genug skalieren. RDG sollte Ihre Caching-Implementierung erleichtern, wenn Sie die Cache-Buchführung auf die Finder-Klasse beschränken.
Wenn Sie Zeit und Lust haben, sehen Sie sich die Patterns of Enterprise Application Architecture von Martin Fowler an . Es ist eine Quelle guter Informationen.
Nun zu den Einzelheiten...
- identifizieren Sie die Daten durch eine Art ID
Normalerweise würden Sie dafür eine automatisch inkrementierte Integer-Spalte in der Datenbank verwenden. Sie können unordered_map verwenden, um diese Objekte schnell aus dem Cache zu ziehen. Da Sie alle Objekte in Ihrem Cache haben, könnten Sie zur Optimierung auch einige der find* implementieren Funktionen, um zuerst den Cache zu durchsuchen. Sie können unordered_map/unordered_multimap verwenden, um einige der Daten zu 'indizieren', wenn Ihre Suchzeit stark eingeschränkt ist, oder einfach bei der guten alten Karte/Multimap bleiben. Dies verdoppelt jedoch die Arbeit, und Sie haben diese Art von Abfragen bereits kostenlos in der Datenbank.
- Bearbeiten Sie die zwischengespeicherten Daten/Objekte
Schmutzige Daten sollten für den Rest des Systems nicht sichtbar sein, bis Sie sie tatsächlich in die Datenbank schreiben. Sobald Sie das Update starten und alles wie vorgesehen läuft, können Sie entweder das Objekt im Cache durch das Objekt ersetzen, das Sie für das Update verwendet haben, oder einfach das Objekt im Cache löschen und andere Leser es aus der Datenbank abrufen lassen (was zur Folge hat beim erneuten Zwischenspeichern des Objekts). Sie können dies implementieren, indem Sie das ursprüngliche Gateway-Objekt klonen, aber die Quintessenz ist, dass Sie eine Sperrstrategie implementiert haben sollten.
- alte Daten/Objekte löschen und neue Daten/Objekte hinzufügen
Hier löschen Sie einfach das Objekt aus dem Cache und versuchen, es aus der Datenbank zu löschen. Wenn das Löschen in der Datenbank fehlschlägt, wird es von anderen Readern zwischengespeichert. Stellen Sie einfach sicher, dass kein Client auf denselben Datensatz zugreifen kann, während Sie gerade dabei sind, ihn zu löschen. Wenn Sie neue Datensätze hinzufügen, instanziieren Sie einfach das Gateway-Objekt, übergeben es an das Objekt auf Domänenebene, und wenn Sie mit den Änderungen fertig sind, rufen Sie insert für das Gateway-Objekt auf. Sie können das neue Gateway-Objekt entweder in den Cache stellen oder es einfach dem ersten Leser überlassen, es in den Cache zu stellen.
- Ordnen Sie die Daten nach irgendeiner Art von Priorität (zuletzt verwendet)
- Wie lassen sich die Daten/Objekte basierend auf den bereitgestellten Informationen UND WARUM am besten zwischenspeichern?
Hier geht es darum, den besten Caching-Algorithmus auszuwählen. Diese Frage ist nicht leicht zu beantworten, aber LRU sollte gut funktionieren. Ohne tatsächliche Metriken gibt es keine richtige Antwort, aber LRU ist einfach zu implementieren, und wenn es Ihren Anforderungen nicht entspricht, nehmen Sie einfach die Metriken vor und entscheiden Sie sich für einen neuen Algorithmus. Stellen Sie sicher, dass Sie dies nahtlos tun können, indem Sie eine gute Schnittstelle zum Cache haben. Eine andere Sache, die Sie beachten sollten, ist, dass Ihre Objekte auf Domänenebene niemals von den Grenzen Ihres Caches abhängen sollten. Wenn Sie 100.000 Objekte benötigen, aber nur 50.000 Cache haben, haben Sie immer noch alle 100.000 Objekte im Arbeitsspeicher, aber 50.000 davon befinden sich im Cache. Mit anderen Worten, Ihre Objekte sollten nicht vom Zustand Ihres Caches abhängen und sich auch nicht darum kümmern, ob Sie überhaupt Caching haben.
Als nächstes, wenn Sie immer noch mit der Idee von RDG konfrontiert sind, speichern Sie einfach Gateway-Objekte in Ihrem Cache. Sie können Instanzen der Gateway-Objekte mithilfe von shared_ptr in Ihrem Cache behalten, sollten aber auch Ihre Sperrstrategie (optimistisch vs. pessimistisch) berücksichtigen, wenn Sie Dirty Writes vermeiden möchten. Außerdem können alle Ihre Gateways (eines für jede Tabelle) dieselbe Schnittstelle erben, sodass Sie Ihre Speicher-/Ladestrategien verallgemeinern können, und Sie könnten auch einen einzelnen Pool verwenden, während Sie die Dinge einfach halten. (Sieh dir boost::pool an. Vielleicht hilft es dir bei der Cache-Implementierung.)
Ein letzter Punkt:
Der Kuchen ist eine Lüge! :D Egal, wofür Sie sich entscheiden, stellen Sie sicher, dass es auf einer anständigen Menge an Leistungsmetriken basiert. Wenn Sie die Leistung um 20 % verbessern und 2 Monate damit verbracht haben, lohnt es sich vielleicht, darüber nachzudenken, ob Sie Ihrer Hardware noch ein paar GB RAM hinzufügen sollten. Machen Sie einen leicht überprüfbaren Proof of Concept, der Ihnen genügend Informationen darüber gibt, ob sich die Implementierung Ihres Caches auszahlt, und wenn nicht, probieren Sie einige der getesteten und zuverlässigen Lösungen von der Stange aus (Memcached oder ähnliches, wie @Layne bereits kommentiert hat). P>