[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]
Das MERGE -Anweisung (eingeführt in SQL Server 2008) ermöglicht es uns, eine Mischung aus INSERT auszuführen , UPDATE , und DELETE Operationen mit einer einzigen Anweisung. Die Halloween-Schutzprobleme für MERGE sind meistens eine Kombination der Anforderungen der einzelnen Operationen, aber es gibt einige wichtige Unterschiede und ein paar interessante Optimierungen, die nur für MERGE gelten .
Das Halloween-Problem mit MERGE vermeiden
Wir beginnen mit einem erneuten Blick auf das Demo- und Staging-Beispiel aus Teil zwei:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Wie Sie sich vielleicht erinnern, wurde dieses Beispiel verwendet, um zu zeigen, dass ein INSERT erfordert Halloween-Schutz, wenn die Insert-Target-Tabelle auch in SELECT referenziert wird Teil der Abfrage (der EXISTS Klausel in diesem Fall). Das korrekte Verhalten für INSERT Die obige Aussage besteht darin, zu versuchen, beide hinzuzufügen 1234 Werte und schlägt folglich mit einem PRIMARY KEY fehl Verstoß. Ohne Phasentrennung das INSERT würde fälschlicherweise einen Wert hinzufügen und ohne Fehlermeldung abschließen.
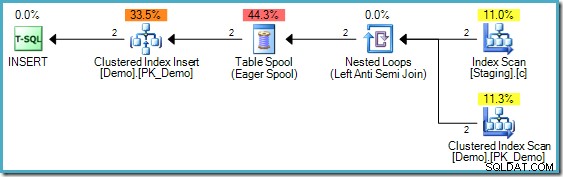
Der INSERT-Ausführungsplan
Der obige Code hat einen Unterschied zu dem in Teil zwei; Ein nicht gruppierter Index für die Staging-Tabelle wurde hinzugefügt. Das INSERT Ausführungsplan noch erfordert jedoch Halloween-Schutz:
Der MERGE-Ausführungsplan
Versuchen Sie nun dieselbe logische Einfügung, die mit MERGE ausgedrückt wird Syntax:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Falls Sie mit der Syntax nicht vertraut sind, besteht die Logik darin, Zeilen in den Staging- und Demo-Tabellen mit dem SomeKey-Wert zu vergleichen, und wenn keine übereinstimmende Zeile in der Zieltabelle (Demo) gefunden wird, fügen wir eine neue Zeile ein. Dies hat genau dieselbe Semantik wie das vorherige INSERT...WHERE NOT EXISTS Code natürlich. Der Ausführungsplan ist jedoch ganz anders:
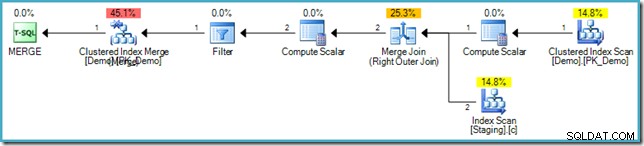
Beachten Sie das Fehlen einer Eager Table Spool in diesem Plan. Trotzdem liefert die Abfrage immer noch die richtige Fehlermeldung. Es scheint, dass SQL Server einen Weg gefunden hat, MERGE auszuführen Planen Sie iterativ unter Beachtung der vom SQL-Standard geforderten logischen Phasentrennung.
Die Lochfüllungsoptimierung
Unter den richtigen Umständen kann der SQL Server-Optimierer erkennen, dass MERGE Aussage ist Löcher füllend , was nur eine andere Art zu sagen ist, dass die Anweisung nur Zeilen hinzufügt, bei denen eine Lücke im Schlüssel der Zieltabelle vorhanden ist.
Damit diese Optimierung angewendet wird, werden die in WHEN NOT MATCHED BY TARGET verwendeten Werte verwendet Klausel muss genau sein dem ON entsprechen Teil von USING Klausel. Außerdem muss die Zieltabelle einen eindeutigen Schlüssel haben (eine Anforderung, die vom PRIMARY KEY erfüllt wird im aktuellen Fall). Wo diese Anforderungen erfüllt sind, wird der MERGE Aussage erfordert keinen Schutz vor dem Halloween-Problem.
Natürlich das MERGE Aussage ist logisch kein mehr oder weniger Löcherfüllen als das Original INSERT...WHERE NOT EXISTS Syntax. Der Unterschied besteht darin, dass der Optimierer die vollständige Kontrolle über die Implementierung von MERGE hat -Anweisung, während die INSERT Syntax würde es erfordern, über die breitere Semantik der Abfrage nachzudenken. Ein Mensch kann leicht erkennen, dass INSERT ist auch Lückenfüller, aber der Optimierer denkt nicht auf die gleiche Weise wie wir.
Zur Veranschaulichung der genauen Übereinstimmung Anforderung, die ich erwähnt habe, betrachten Sie die folgende Abfragesyntax, die nicht Profitieren Sie von der Lochfülloptimierung. Das Ergebnis ist ein vollständiger Halloween-Schutz, der von einer Eager Table Spool geboten wird:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Der einzige Unterschied besteht in der Multiplikation mit Eins in den VALUES -Klausel – etwas, das die Logik der Abfrage nicht ändert, aber ausreicht, um zu verhindern, dass die Optimierung zum Füllen von Löchern angewendet wird.
Löcher füllen mit Nested Loops
Im vorherigen Beispiel entschied sich der Optimierer dafür, die Tabellen mit einem Merge-Join zu verknüpfen. Die Lochfüllungsoptimierung kann auch angewendet werden, wenn ein Nested-Loops-Join gewählt wird, aber dies erfordert eine zusätzliche Eindeutigkeitsgarantie für die Quelltabelle und eine Indexsuche auf der Innenseite des Joins. Um dies in Aktion zu sehen, können wir die vorhandenen Staging-Daten löschen, dem Nonclustered-Index Eindeutigkeit hinzufügen und MERGE ausprobieren nochmal:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Der resultierende Ausführungsplan verwendet erneut die Optimierung zum Füllen von Löchern, um den Halloween-Schutz zu vermeiden, indem er eine Verknüpfung mit verschachtelten Schleifen und eine innere Suche in der Zieltabelle verwendet:
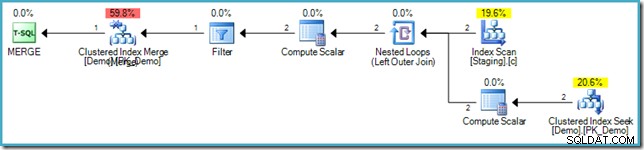
Unnötige Indexdurchläufe vermeiden
Wo die Lochfüllungsoptimierung gilt, kann die Engine auch eine weitere Optimierung anwenden. Es kann sich beim Lesen die aktuelle Indexposition merken die Zieltabelle (verarbeiten Sie jeweils eine Zeile, denken Sie daran) und verwenden Sie diese Informationen beim Ausführen der Einfügung wieder, anstatt den B-Baum zu durchsuchen, um die Einfügeposition zu finden. Der Grund dafür ist, dass sich die aktuelle Leseposition sehr wahrscheinlich auf derselben Seite befindet, auf der die neue Zeile eingefügt werden sollte. Die Überprüfung, ob die Zeile tatsächlich auf diese Seite gehört, geht sehr schnell, da nur die niedrigsten und höchsten Schlüssel überprüft werden, die derzeit dort gespeichert sind.
Die Kombination aus dem Eliminieren des Eager Table Spool und dem Speichern einer Indexnavigation pro Zeile kann einen erheblichen Vorteil bei OLTP-Workloads bieten, vorausgesetzt, der Ausführungsplan wird aus dem Cache abgerufen. Die Kompilierungskosten für MERGE Anweisungen ist etwas höher als bei INSERT , UPDATE und DELETE , daher ist die Wiederverwendung von Plänen eine wichtige Überlegung. Es ist auch hilfreich, sicherzustellen, dass die Seiten über ausreichend freien Speicherplatz für neue Zeilen verfügen, um Seitenteilungen zu vermeiden. Dies wird typischerweise durch die normale Indexpflege und die Zuweisung eines geeigneten FILLFACTOR erreicht .
Ich erwähne OLTP-Arbeitslasten, die typischerweise eine große Anzahl relativ kleiner Änderungen aufweisen, weil die MERGE Optimierungen sind möglicherweise keine gute Wahl, wenn eine große Anzahl von Zeilen pro Anweisung verarbeitet wird. Andere Optimierungen wie minimal protokollierte INSERTs derzeit nicht mit Lochfüllung kombinierbar. Wie immer sollten die Leistungsmerkmale verglichen werden, um sicherzustellen, dass die erwarteten Vorteile realisiert werden.
Die Lückenfülloptimierung für MERGE Einfügungen können mit Aktualisierungen und Löschungen kombiniert werden, indem zusätzliches MERGE verwendet wird Klauseln; jede Datenänderungsoperation wird für das Halloween-Problem separat bewertet.
Joint vermeiden
Die letzte Optimierung, die wir uns ansehen werden, kann dort angewendet werden, wo MERGE -Anweisung enthält Aktualisierungs- und Löschoperationen sowie eine lückenhafte Einfügung, und die Zieltabelle hat einen eindeutigen gruppierten Index. Das folgende Beispiel zeigt ein allgemeines MERGE Muster, bei dem nicht übereinstimmende Zeilen eingefügt werden und übereinstimmende Zeilen abhängig von einer zusätzlichen Bedingung aktualisiert oder gelöscht werden:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
Das MERGE -Anweisung, die erforderlich ist, um alle erforderlichen Änderungen vorzunehmen, ist bemerkenswert kompakt:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Der Ausführungsplan ist ziemlich überraschend:

Kein Halloween-Schutz, kein Join zwischen den Quell- und Zieltabellen, und es kommt nicht oft vor, dass Sie einen Clustered Index Insert-Operator sehen, gefolgt von einem Clustered Index Merge in dieselbe Tabelle. Dies ist eine weitere Optimierung, die auf OLTP-Arbeitslasten mit hoher Wiederverwendung von Plänen und geeigneter Indizierung abzielt.
Die Idee ist, eine Zeile aus der Quelltabelle zu lesen und sofort zu versuchen, sie in das Ziel einzufügen. Wenn ein Schlüsselverstoß auftritt, wird der Fehler unterdrückt, der Insert-Operator gibt die widersprüchliche Zeile aus, die er gefunden hat, und diese Zeile wird dann für einen Aktualisierungs- oder Löschvorgang unter Verwendung des Merge-Plan-Operators wie gewohnt verarbeitet.
Wenn die ursprüngliche Einfügung erfolgreich ist (ohne eine Schlüsselverletzung), wird die Verarbeitung mit der nächsten Zeile aus der Quelle fortgesetzt (der Merge-Operator verarbeitet nur Aktualisierungen und Löschungen). Diese Optimierung kommt vor allem MERGE zugute Abfragen, bei denen die meisten Quellzeilen zu einer Einfügung führen. Auch hier ist ein sorgfältiges Benchmarking erforderlich, um sicherzustellen, dass die Leistung besser ist als die Verwendung separater Anweisungen.
Zusammenfassung
Das MERGE -Anweisung bietet mehrere einzigartige Optimierungsmöglichkeiten. Unter den richtigen Umständen kann es die Notwendigkeit vermeiden, einen expliziten Halloween-Schutz hinzuzufügen, verglichen mit einem äquivalenten INSERT Operation oder vielleicht sogar eine Kombination aus INSERT , UPDATE , und DELETE Aussagen. Zusätzliches MERGE -spezifische Optimierungen können die Index-B-Tree-Traversierung vermeiden, die normalerweise erforderlich ist, um die Einfügeposition für eine neue Zeile zu finden, und können auch die Notwendigkeit vermeiden, die Quell- und Zieltabellen vollständig zu verknüpfen.
Im letzten Teil dieser Serie sehen wir uns an, wie der Abfrageoptimierer die Notwendigkeit des Halloween-Schutzes begründet, und identifizieren einige weitere Tricks, die er anwenden kann, um die Notwendigkeit zu vermeiden, Eager Table Spools zu Ausführungsplänen hinzuzufügen, die Daten ändern.
[ Teil 1 | Teil 2 | Teil 3 | Teil 4 ]