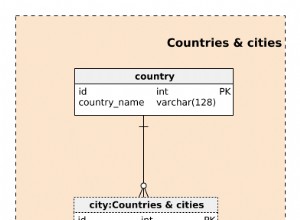
Die Partitionierung in postgresql funktioniert hervorragend für große Protokolle. Erstellen Sie zuerst die übergeordnete Tabelle:
create table game_history_log (
gameid integer,
views integer,
plays integer,
likes integer,
log_date date
);
Erstellen Sie nun die Partitionen. In diesem Fall wäre eine für jeden Monat, 900.000 Zeilen, gut:
create table game_history_log_201210 (
check (log_date between '2012-10-01' and '2012-10-31')
) inherits (game_history_log);
create table game_history_log_201211 (
check (log_date between '2012-11-01' and '2012-11-30')
) inherits (game_history_log);
Beachten Sie die Check Constraints in jeder Partition. Wenn Sie versuchen, in die falsche Partition einzufügen:
insert into game_history_log_201210 (
gameid, views, plays, likes, log_date
) values (1, 2, 3, 4, '2012-09-30');
ERROR: new row for relation "game_history_log_201210" violates check constraint "game_history_log_201210_log_date_check"
DETAIL: Failing row contains (1, 2, 3, 4, 2012-09-30).
Einer der Vorteile der Partitionierung besteht darin, dass nur in der richtigen Partition gesucht wird, wodurch die Suchgröße drastisch und konsistent reduziert wird, unabhängig davon, wie viele Jahre an Daten vorhanden sind. Hier die Erklärung für die Suche nach einem bestimmten Datum:
explain
select *
from game_history_log
where log_date = date '2012-10-02';
QUERY PLAN
------------------------------------------------------------------------------------------------------
Result (cost=0.00..30.38 rows=9 width=20)
-> Append (cost=0.00..30.38 rows=9 width=20)
-> Seq Scan on game_history_log (cost=0.00..0.00 rows=1 width=20)
Filter: (log_date = '2012-10-02'::date)
-> Seq Scan on game_history_log_201210 game_history_log (cost=0.00..30.38 rows=8 width=20)
Filter: (log_date = '2012-10-02'::date)
Beachten Sie, dass abgesehen von der übergeordneten Tabelle nur die richtige Partition gescannt wurde. Natürlich können Sie Indizes auf den Partitionen haben, um einen sequentiellen Scan zu vermeiden.