Hier sind einige Hinweise:Aurora hat viele Instanzen. Einer ist "Schreiber" (Master), andere sind "Leser" (Slaves).
Wenn ein Writer ausfällt, wird ein Slave zum neuen Master befördert, andere Slaves replizieren nun von diesem neuen Master (automatischer Neustart). Wenn der alte Meister wieder auftaucht, wird er ein Sklave.
Aurora hat einen DNS-Endpunkt für Cluster wie „xx.cluster-yy.zz.rds.amazonaws.com“, der auf den aktuellen Master verweist. Wenn ein Failover auftritt, wird DNS aktualisiert ... aber nicht sofort.
Eine "Verbindung" zu Aurora bedeutet 2 zugrunde liegende Verbindungen zu Instanzen:eine zum Master, eine zum Slave. Der Treiber verwendet die zugrunde liegende Verbindung zum Master oder Slave gemäß Connection.setReadonly().
Jedes Mal, wenn der Treiber eine Verbindung zu einer Instanz herstellt, wird sichergestellt, dass der aktuelle Status die globale Variable "innodb_read_only" (OFF =Master) überprüft.
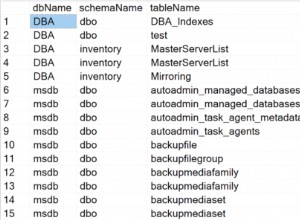
Aurora-Instanzen können hinzugefügt werden, sodass bei der ersten Verbindung mit dem Benutzercluster-Endpunkt die aktuelle Liste der Instanzen mit information_schema.replica_host_status abgerufen wird.
Um die 2 zugrunde liegenden Verbindungen herzustellen, verbindet sich der Treiber mit einem zufälligen Host. Wenn dies der aktuelle Master ist, sind alle anderen Hosts Slaves. Wenn nicht, fragt der Treiber den Slave nach seinem aktuellen Master, sodass die nächste Verbindung den Host mithilfe von information_schema verbindet. replica_host_status, wobei session_id ='MASTER_SESSION_ID' (zuverlässiger als die Verwendung von DNS). Wenn die Verbindung zu einer Instanz fehlschlägt, wird dieser Instanzname für eine bestimmte Zeit auf eine schwarze Liste gesetzt (diese schwarze Liste wird pro jvm geteilt), um eine Wiederverwendung zu vermeiden. Der Treiber versucht, einen zufällig verfügbaren Host erneut zu verbinden, bis keiner mehr auf der schwarzen Liste steht, und kann es dann für einige Zeit mit einem auf der schwarzen Liste erneut versuchen (abhängig von den Parametern). Wenn die Verbindung erfolgreich ist, wird die Instanz von der schwarzen Liste befreit.
Für das Failover der zugrunde liegenden Slave-Verbindung wird dann die Master-Verbindung verwendet, und ein zugrunde liegender Pool von Threads versucht dann, eine Slave-Instanz im Hintergrund erneut zu verbinden.