Ihre Frage ist wirklich ungenau. Bitte folgen Sie den Vorschlägen von @RiggsFolly und lesen Sie die Referenzen zum Stellen einer guten Frage.
Außerdem sollten Sie, wie von @DuduMarkovitz vorgeschlagen, damit beginnen, das Problem zu vereinfachen und Ihre Daten zu bereinigen. Ein paar Ressourcen für den Einstieg:
- Einfaches Tutorial zur Textverarbeitung von Matt Deny
- Handling und Verarbeitung von Zeichenketten in R von Gaston Sanchez
Wenn Sie mit den Ergebnissen zufrieden sind, können Sie damit fortfahren, eine Gruppe für jede Var1 zu identifizieren Eintrag (dies wird Ihnen später helfen, weitere Analysen/Manipulationen an ähnlichen Einträgen durchzuführen) Dies könnte auf viele verschiedene Arten erfolgen, aber wie von @GordonLinoff erwähnt, ist eine Möglichkeit die Levenshtein-Distanz.
Hinweis :Bei 50.000 Einträgen ist das Ergebnis nicht 100 % genau, da dies immer nicht der Fall sein wird kategorisieren Sie die Begriffe in der entsprechenden Gruppe, aber dies sollte den manuellen Aufwand erheblich reduzieren.
In R können Sie dies mit
Unter Verwendung Ihrer Beispieldaten:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
Für diese kleine Stichprobe können Sie die 3 unterschiedlichen Gruppen (die Cluster mit niedrigen Levensthein-Abstandswerten) sehen und sie leicht manuell zuweisen, aber für größere Sets benötigen Sie wahrscheinlich einen Clustering-Algorithmus.
Ich habe Sie bereits in den Kommentaren auf einen meiner vorherige Antwort
zeigt, wie man das mit hclust() macht und die Minimum-Varianz-Methode von Ward, aber ich denke, hier wären Sie besser dran, andere Techniken zu verwenden (eine meiner Lieblingsressourcen zu diesem Thema für einen schnellen Überblick über einige der am häufigsten verwendeten Methoden in R ist diese detaillierte Antwort
)
Hier ist ein Beispiel für die Verwendung von Affinity Propagation Clustering:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Sie finden im APResult-Objekt d_ap die jedem Cluster zugeordneten Elemente und die optimale Anzahl von Clustern, in diesem Fall:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Sie können auch eine visuelle Darstellung sehen:
> heatmap(d_ap, margins = c(10, 10))
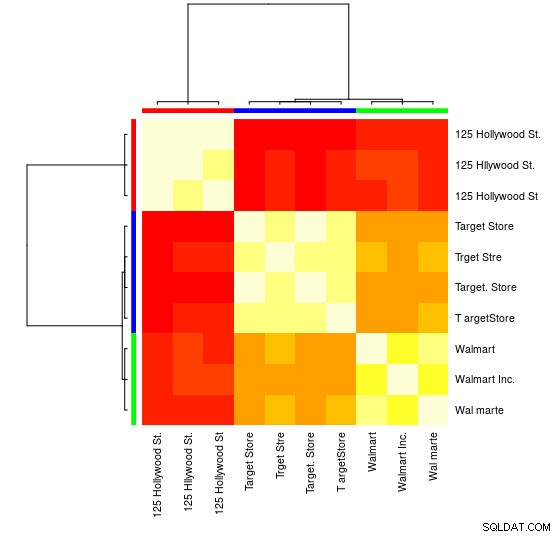
Anschließend können Sie weitere Manipulationen für jede Gruppe vornehmen. Als Beispiel verwende ich hier hunspell um jedes einzelne Wort von Var1 nachzuschlagen Suchen Sie in einem en_US-Wörterbuch nach Rechtschreibfehlern und versuchen Sie, innerhalb jeder Gruppe zu finden , welche id enthält keine Rechtschreibfehler (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Was ergibt:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Hinweis :Da wir hier keine Textverarbeitung durchgeführt haben, sind die Ergebnisse nicht sehr aussagekräftig, aber Sie bekommen eine Idee.
Daten
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)



