Dies ist die geschriebene Version meines neuen YouTube-Videos ✍️ 🙂
In diesem Redis-Tutorial erfahren Sie mehr über Redis und wie Redis als primäre Datenbank für komplexe Anwendungen verwendet werden kann die Daten in mehreren Formaten speichern müssen.
Übersicht 📝
- Was Redis ist und seine Verwendung und warum es für moderne komplexe Microservice-Anwendungen geeignet ist?
- Wie Redis das Speichern mehrerer Datenformate für verschiedene Zwecke durch seine Module unterstützt ?
- Wie Redis als In-Memory-Datenbank Daten speichern und nach Datenverlust wiederherstellen kann ?
- Wie man Redis skaliert und repliziert ?
- Da schließlich Kubernetes eine der beliebtesten Plattformen zum Ausführen von Mikrodiensten ist und das Ausführen von zustandsbehafteten Anwendungen in Kubernetes eine gewisse Herausforderung darstellt, werden wir sehen, wie Sie ganz einfach Redis in Kubernetes ausführen können
Was ist Redis?
Redis steht für re mote dic tionäre s immer
Redis ist eine In-Memory-Datenbank . So viele Leute haben es als Cache für andere Datenbanken verwendet um die Anwendungsleistung zu verbessern. 🤓
Was viele jedoch nicht wissen, ist, dass Redis eine vollwertige primäre Datenbank ist die zum Speichern und Persistieren mehrerer Datenformate für komplexe Anwendungen verwendet werden können. 😎
Sehen wir uns also die Anwendungsfälle dafür an.
Warum Multi-Model-Datenbank?
Sehen wir uns ein allgemeines Setup für eine Microservices-Anwendung an.
Nehmen wir an, wir haben eine komplexe Social-Media-Anwendung mit Millionen von Benutzern. Dazu müssen wir ggf. unterschiedliche Datenformate in unterschiedlichen Datenbanken hinterlegen:
- Relationale Datenbank , wie Mysql, um unsere Daten zu speichern
- ElasticSearch zum schnellen Suchen und Filtern
- Grafikdatenbank um die Verbindungen der Nutzer darzustellen
- Dokumentendatenbank , wie MongoDB, um täglich von unseren Benutzern geteilte Medieninhalte zu speichern
- Cache-Dienst für eine bessere Leistung der Anwendung
Es ist offensichtlich, dass dies ein ziemlich komplexes Setup ist.
Herausforderungen bei mehreren Datendiensten
- ❌ Jeder Datendienst muss bereitgestellt und gewartet werden
- ❌ Know-How für jeden Datendienst erforderlich
- ❌ Unterschiedliche Skalierungs- und Infrastrukturanforderungen
- ❌ Komplexerer Anwendungscode für die Interaktion mit all diesen verschiedenen DBs
- ❌ Höhere Latenz (langsamer) aufgrund von mehr Netzwerk-Hopping
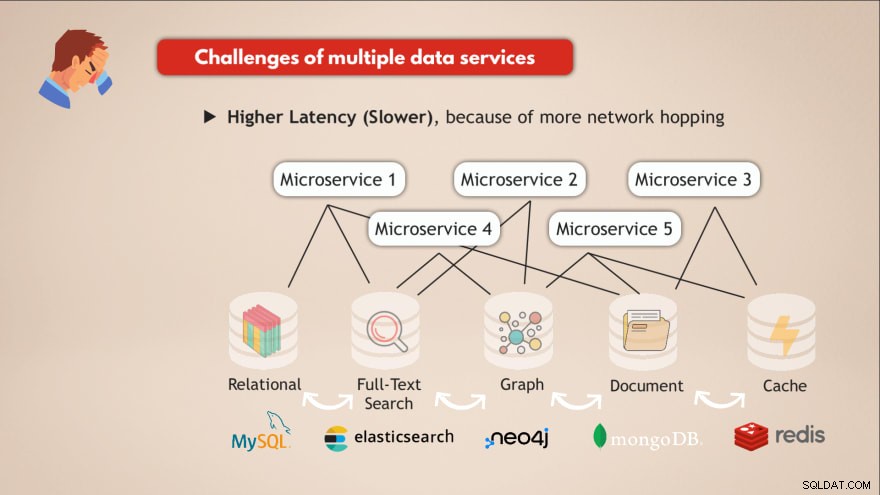
Eine Datenbank mit mehreren Modellen haben
Im Vergleich zu einer Multi-Modell-Datenbank lösen Sie die meisten dieser Herausforderungen. Zunächst einmal betreiben und pflegen Sie nur 1 Datendienst . Ihre Anwendung muss also auch mit einem einzelnen Datenspeicher kommunizieren, und das erfordert nur eine programmatische Schnittstelle für diesen Datendienst.
Darüber hinaus wird die Latenz verringert, indem zu einem einzigen Datenendpunkt gewechselt und mehrere interne Netzwerk-Hubs eliminiert werden.
Eine einzige Datenbank wie Redis, die es Ihnen ermöglicht, verschiedene Arten von Daten zu speichern oder im Grunde mehrere Arten von Datenbanken in einer zu haben und gleichzeitig als Cache zu fungieren, löst solche Herausforderungen.
- ✅ Führen und pflegen Sie nur eine Datenbank
- ✅ Einfacher
- ✅ Reduzierte Latenz (schneller)
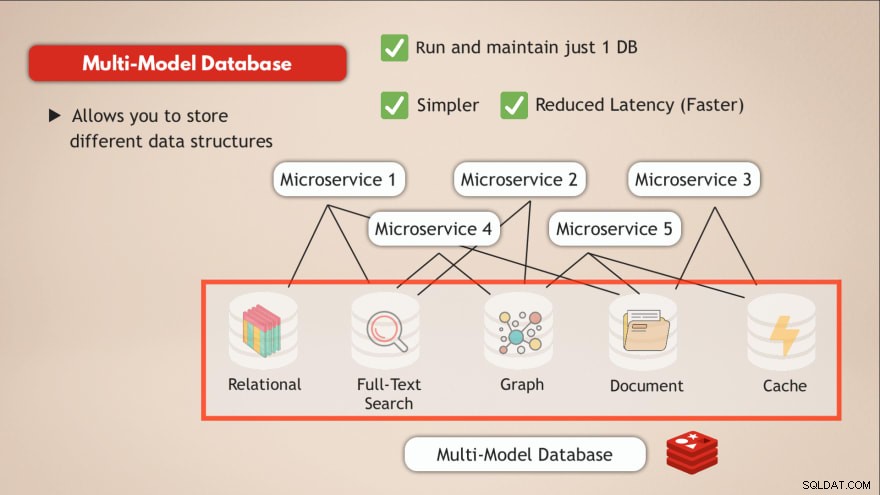
Wie Redis funktioniert?
Redis-Module 📦
Es funktioniert so, dass Sie Redis Core, einen Schlüsselwertspeicher haben das bereits das Speichern mehrerer Datentypen unterstützt, und dann können Sie diesen Kern mit sogenannten Modulen für verschiedene Datentypen erweitern , die Ihre Anwendung für verschiedene Zwecke benötigt. So zum Beispiel RediSearch für Suchfunktionen wie ElasticSearch oder Redis Graph für die Speicherung von Diagrammdaten und so weiter:

Und das Tolle daran ist, dass es modular ist . Diese verschiedenen Arten von Datenbankfunktionalitäten sind also nicht fest in eine Datenbank integriert, sondern Sie können genau auswählen, welche Datendienstfunktionalität Sie für Ihre Anwendung benötigen, und dann im Grunde dieses Modul hinzufügen.
Standard-Cache ⚡️
Wenn Sie Redis als primäre Datenbank verwenden, benötigen Sie natürlich keinen zusätzlichen Cache, da Sie diesen mit Redis automatisch aus der Box haben. Das bedeutet wiederum weniger Komplexität in Ihrer Anwendung, da Sie die Logik zum Verwalten des Füllens und Invalidierens des Caches nicht implementieren müssen.
Redis ist schnell 🚀
Als In-Memory-Datenbank (Daten werden im RAM gespeichert) ist Redis superschnell und leistungsfähig, was natürlich die Anwendung selbst schneller macht.
Aber an dieser Stelle fragen Sie sich vielleicht:
Wie kann eine In-Memory-Datenbank Daten speichern? 🤔
Wie kann Redis Daten beibehalten und nach Datenverlust wiederherstellen? 🧐
Wenn der Redis-Prozess oder der Server, auf dem Redis läuft, ausfällt, sind alle Daten im Speicher weg, richtig? Wie also werden die Daten gespeichert und wie kann ich im Grunde sicher sein, dass meine Daten sicher sind? 👀
Redis replizieren?
Nun, der einfachste Weg für Datensicherungen ist die Replikation von Redis . Wenn also die Redis-Masterinstanz ausfällt, werden die Replikate weiterhin ausgeführt und verfügen über alle Daten. Wenn Sie also ein repliziertes Redis haben, enthalten die Replikate die Daten.
Aber natürlich verlieren Sie die Daten, wenn alle Redis-Instanzen ausfallen, da keine Replik mehr übrig bleibt. 🤯Also brauchen wir wirkliche Beharrlichkeit .
Schnappschuss &AOF
Redis verfügt über mehrere Mechanismen zum Persistieren und Sichern der Daten.
Schnappschüsse
Erstens:die Snapshots, die Sie basierend auf Zeit, Anzahl der Anfragen usw. konfigurieren können. So werden Snapshots Ihrer Daten auf einer Festplatte gespeichert , mit dem Sie Ihre Daten wiederherstellen können, wenn die gesamte Redis-Datenbank weg ist.
Beachten Sie jedoch, dass dabei die Daten der letzten Minuten verloren gehen , da Sie je nach Bedarf normalerweise alle fünf Minuten oder jede Stunde Schnappschüsse erstellen. 😐
AOF
Als Alternative verwendet Redis also etwas namens AOF , was für A steht O anhängen nur F Datei.
In diesem Fall wird jede Änderung dauerhaft auf der Festplatte gespeichert . Und beim Neustart von Redis oder nach einem Ausfall spielt Redis die Append Only File-Protokolle ab, um den Status wiederherzustellen.
AOF ist also haltbarer , kann aber langsamer sein als Snapshots.
Beste Option 💡 :Verwenden Sie eine Kombination aus AOF und Snapshots, wobei AOF kontinuierlich Daten vom Speicher auf die Festplatte speichert und Sie regelmäßige Snapshots dazwischen haben, um den Datenstatus zu speichern, falls Sie ihn wiederherstellen müssen:

Wie skaliere ich eine Redis-Datenbank?
Angenommen, meine 1 Redis-Instanz hat keinen Arbeitsspeicher mehr, sodass die Daten zu groß werden, um sie im Arbeitsspeicher zu halten, oder Redis wird zu einem Engpass und kann keine weiteren Anforderungen verarbeiten. Wie kann ich in einem solchen Fall die Kapazität und Speichergröße erhöhen? für meine Redis-Datenbank? 🤔
Dafür haben wir mehrere Möglichkeiten:
1. Clusterbildung
Zunächst einmal unterstützt Redis Clustering . Das bedeutet, dass Sie eine primäre oder Master-Redis-Instanz haben können, die zum Lesen und Schreiben von Daten verwendet werden kann, und Sie können mehrere Replikate dieser primären Instanz zum Lesen der Daten haben :
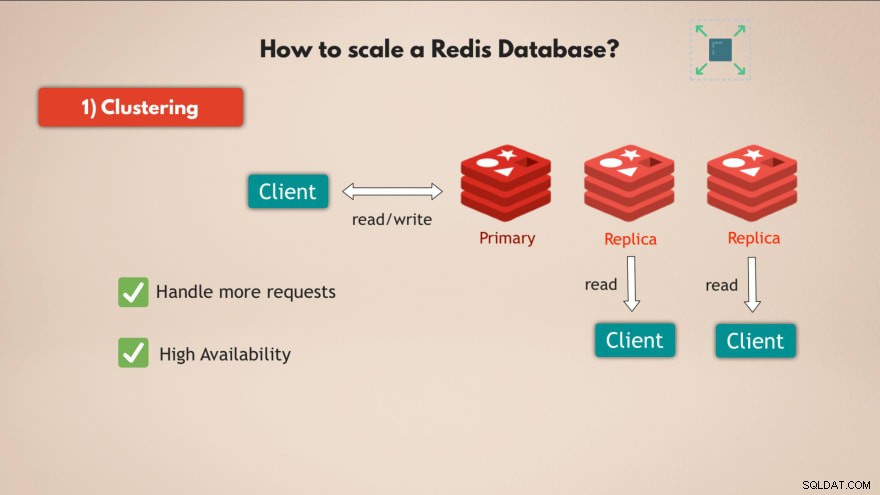
Auf diese Weise können Sie Redis skalieren, um mehr Anfragen zu verarbeiten und zusätzlich die Hochverfügbarkeit erhöhen Ihrer Datenbank, denn wenn der Master ausfällt, kann 1 der Replikate übernehmen und Ihre Redis-Datenbank kann grundsätzlich ohne Probleme weiter funktionieren.
2. Sharding
Nun, das scheint gut genug, aber was wäre, wenn
- Ihr Datensatz wird zu groß, um in den Speicher eines einzelnen Servers zu passen .
- Außerdem haben wir die Lesevorgänge in der Datenbank skaliert, also alle Anfragen, die im Grunde nur die Daten abfragen. Aber unsere Masterinstanz ist immer noch allein und muss immer noch alle Schreibvorgänge verarbeiten .
Was ist hier also die Lösung? 🤔
Dafür verwenden wir das Konzept des Sharding , was ein allgemeines Konzept in Datenbanken ist und das auch von Redis unterstützt wird.
Also Sharding bedeutet im Grunde, dass Sie Ihren vollständigen Datensatz nehmen und ihn in kleinere Teile oder Teilmengen von Daten aufteilen , wobei jeder Shard für seine eigene Teilmenge von Daten verantwortlich ist.
Das heißt, anstatt eine Master-Instanz zu haben, die alle Schreibvorgänge für den vollständigen Datensatz verarbeitet, können Sie ihn in sagen wir 4 Shards aufteilen, von denen jeder für Lese- und Schreibvorgänge in einer Teilmenge der Daten verantwortlich ist . 💡
Und jedes Shard benötigt auch weniger Speicherkapazität , weil sie nur ein Viertel der Daten haben. Das bedeutet, dass Sie Shards auf kleineren Knoten verteilen und ausführen und Ihren Cluster grundsätzlich horizontal skalieren können:
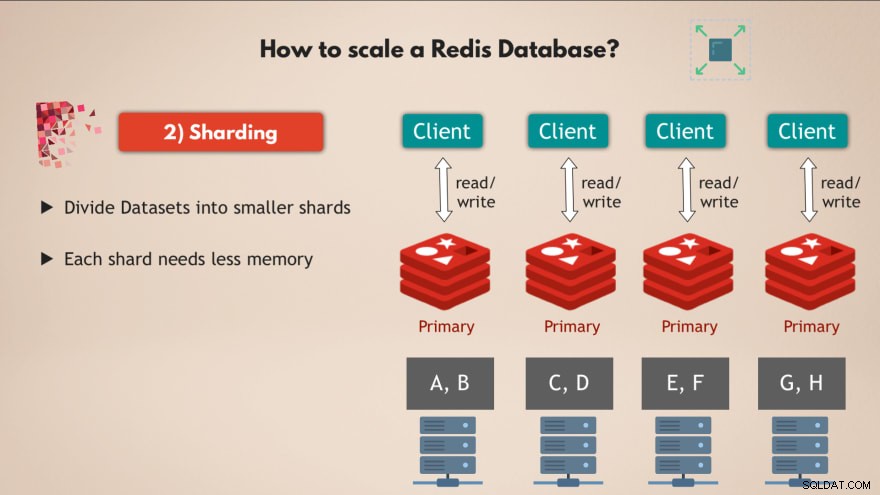
Also mit mehreren Knoten , die mehrere Replikate ausführen von Redis, die alle geteilt sind bietet Ihnen eine sehr performante, hochverfügbare Redis-Datenbank, die viel mehr Anfragen verarbeiten kann, ohne Engpässe zu erzeugen 👍
Weitere Themen...
Schauen Sie sich mein Video unten für die letzten 2 Themen und Szenarien an:
- Anwendungen, die eine noch höhere Verfügbarkeit und Leistung an mehreren geografischen Standorten erfordern
- Der neue Standard zum Ausführen von Mikrodiensten ist die Kubernetes-Plattform, also das Ausführen von Redis in Kubernetes ist ein sehr interessanter und häufiger Anwendungsfall
Das ganze Video gibt es hier:🤓
Ich hoffe, das war hilfreich und interessant für einige von euch! 😊
Gefällt mir, teile und folge mir 😍 für mehr Inhalt:
- Instagram – viele Dinge hinter den Kulissen posten
- Private FB-Gruppe



