Dieser Blogbeitrag ist eine Fortsetzung des vorherigen Teils 1, in dem wir die Grundlagen der SNMP-Integration mit ClusterControl behandelt haben.
In diesem Blogbeitrag konzentrieren wir uns auf SNMP-Traps und -Warnungen. SNMP-Traps sind die am häufigsten verwendeten Warnmeldungen, die von einem entfernten SNMP-fähigen Gerät (einem Agenten) an einen zentralen Kollektor, den „SNMP-Manager“, gesendet werden. Im Fall von ClusterControl könnte ein Trap eine Warnung sein, nachdem der kritische Alarm für einen Cluster nicht 0 ist, was darauf hinweist, dass etwas Schlimmes passiert.
Wie im vorherigen Blogpost gezeigt, haben wir zum Zweck dieses Proof-of-Concept zwei Definitionen für SNMP-Trap-Benachrichtigungen:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Die Benachrichtigungen (oder Traps) sind "criticalAlarmNotification" und "criticalAlarmNotificationEnded". Beide Benachrichtigungsereignisse können verwendet werden, um unserem Nagios-Dienst zu signalisieren, ob der Cluster aktiv kritische Alarme hat oder nicht. In Nagios wird dies als passive Prüfung bezeichnet, wobei Nagios nicht versucht festzustellen, ob ein Host/Service DOWN oder UNREACHABLE ist. Wir werden auch die aktiven Prüfungen konfigurieren, bei denen Prüfungen von der Prüflogik im Nagios-Daemon initiiert werden, indem die Dienstdefinition verwendet wird, um auch die von unserem Cluster gemeldeten kritischen/warnenden Alarme zu überwachen.
Beachten Sie, dass für diesen Blogpost die MIB und der SNMP-Agent von Multiplenines korrekt konfiguriert sein müssen, wie im ersten Teil dieser Blogserie gezeigt.
Installieren von Nagios Core
Nagios Core ist die kostenlose Version der Nagios Monitoring Suite. Als erstes müssen wir es und alle notwendigen Pakete installieren, gefolgt von den Nagios-Plugins, snmptrapd und snmptt. Beachten Sie, dass die Anweisungen in diesem Blogbeitrag davon ausgehen, dass alle Knoten unter CentOS 7 ausgeführt werden.
Installieren Sie die notwendigen Pakete, um Nagios auszuführen:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlErstellen Sie einen Nagios-Benutzer und eine Nagcmd-Gruppe, damit die externen Befehle über die Webschnittstelle ausgeführt werden können, fügen Sie den Nagios- und Apache-Benutzer als Teil der Nagcmd-Gruppe hinzu:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheLaden Sie hier die neueste Version von Nagios Core herunter, kompilieren und installieren Sie sie:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstallieren Sie die Nagios-Webkonfiguration:
$ make install-webconfInstallieren Sie optional das Nagios-Peeling-Design (oder Sie bleiben beim Standard-Design):
$ make install-exfoliationErstellen Sie ein Benutzerkonto (nagiosadmin) für die Anmeldung an der Nagios-Weboberfläche. Merken Sie sich das Passwort, das Sie diesem Benutzer zuweisen:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminStarten Sie den Apache-Webserver neu, damit die neuen Einstellungen wirksam werden:
$ systemctl restart httpd
$ systemctl enable httpdLaden Sie die Nagios-Plugins von hier herunter, kompilieren und installieren Sie sie:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installÜberprüfen Sie die standardmäßigen Nagios-Konfigurationsdateien:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosÖffnen Sie den Browser und gehen Sie zu https://{IPaddress}/nagios und Sie sollten sehen, dass eine HTTP-Basisauthentifizierung erscheint, wo Sie den Benutzernamen als nagiosadmin mit Ihrem zuvor erstellten Passwort angeben müssen.
Hinzufügen des ClusterControl-Servers zu Nagios
Erstellen Sie eine Nagios-Host-Definitionsdatei für ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgUnd fügen Sie die folgenden Zeilen hinzu:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Einige Erklärungen:
-
Im ersten Abschnitt definieren wir unseren Host mit dem Hostnamen und der Adresse des ClusterControl-Servers.
-
Die Dienstabschnitte, in denen wir unsere Dienstdefinitionen ablegen, die von Nagios überwacht werden sollen. Die ersten beiden weisen den Dienst im Grunde an, die SNMP-Ausgabe auf eine bestimmte Objekt-ID zu überprüfen. Beim ersten Dienst geht es um den kritischen Alarm, daher fügen wir -c0 in den Befehl check_snmp ein, um anzuzeigen, dass es sich um einen kritischen Alarm in Nagios handeln sollte, wenn der Wert über 0 hinausgeht. Während wir bei den Warnalarmen darauf hinweisen, wenn der Wert ist 1 und höher.
-
Die letzte Service-Definition betrifft die SNMP-Traps, die wir bei einem kritischen Alarm vom ClusterControl-Server erwarten würden angehoben ist größer als 0. Dieser Abschnitt verwendet die snmp_trap_template-Definition, wie im nächsten Schritt gezeigt.
Konfigurieren Sie das snmp_trap_template, indem Sie die folgenden Zeilen in /usr/local/nagios/etc/objects/templates.cfg hinzufügen:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Fügen Sie die ClusterControl-Konfigurationsdatei in Nagios ein, indem Sie die folgende Zeile darin einfügen
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgFühren Sie eine Preflight-Konfigurationsprüfung durch:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgStellen Sie sicher, dass Sie am Ende der Ausgabe die folgende Zeile erhalten:
"Things look okay - No serious problems were detected during the pre-flight check"Starten Sie Nagios neu, um die Änderung zu laden:
$ systemctl restart nagiosWenn wir uns nun die Nagios-Seite unter dem Service-Abschnitt (Menü auf der linken Seite) ansehen, würden wir so etwas sehen:
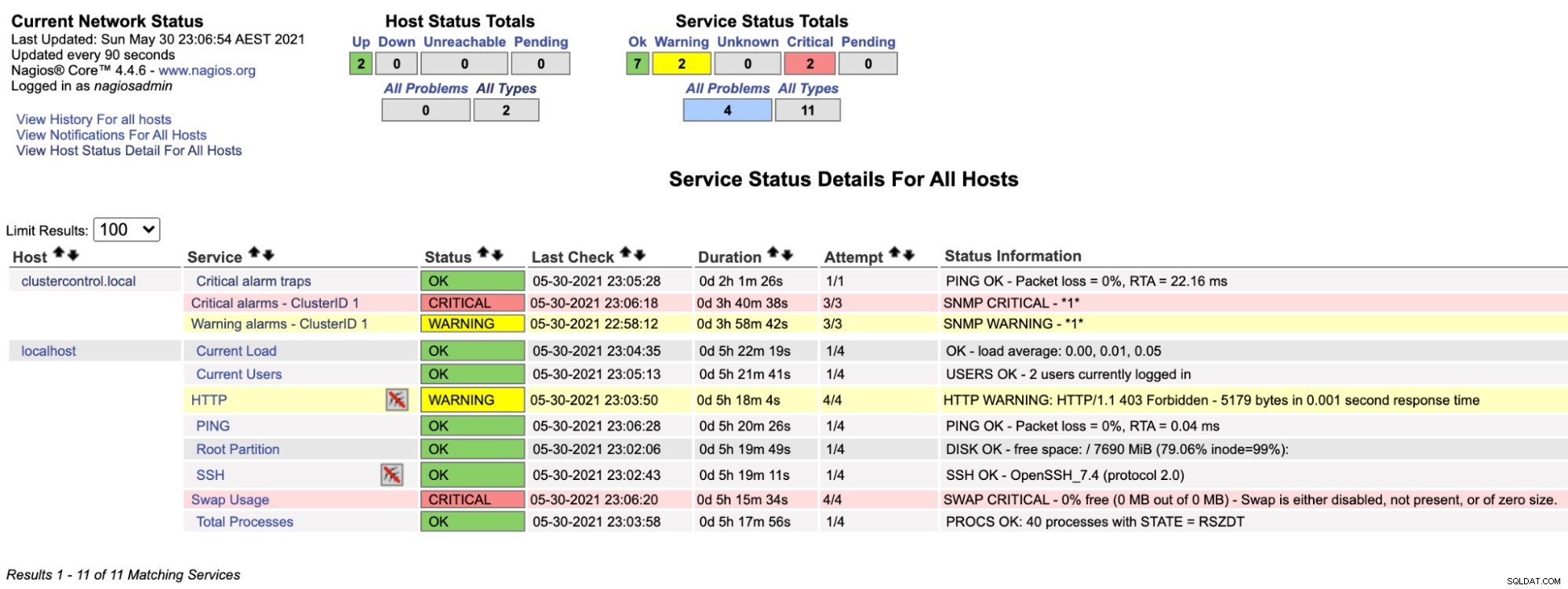
Beachten Sie, dass die Zeile „Kritische Alarme – ClusterID 1“ rot wird, wenn der von ClusterControl gemeldete kritische Alarmwert größer als 0 ist, während die Zeile „Warnalarme – ClusterID 1“ gelb ist, was darauf hinweist, dass ein Warnalarm ausgelöst wurde. Falls nichts Interessantes passiert, sehen Sie für clustercontrol.local alles grün.
Nagios so konfigurieren, dass es einen Trap empfängt
Traps werden von entfernten Geräten an den Nagios-Server gesendet, dies wird als passive Prüfung bezeichnet. Im Idealfall wissen wir nicht, wann ein Trap gesendet wird, da dies davon abhängt, ob das sendende Gerät entscheidet, dass es einen Trap sendet. Zum Beispiel mit einer USV (Batterie-Backup), sobald das Gerät die Stromversorgung verliert, sendet es eine Falle, um zu sagen:"Hey, ich habe die Stromversorgung verloren". So wird Nagios sofort informiert.
Um SNMP-Traps zu empfangen, müssen wir den Nagios-Server mit den folgenden Dingen konfigurieren:
-
snmptrapd (SNMP-Trap-Empfänger-Daemon)
-
snmptt (SNMP Trap Translator, der Trap-Handler-Daemon)
Nachdem der snmptrapd einen Trap empfängt, leitet er ihn an snmptt weiter, wo wir ihn konfigurieren werden, um das Nagios-System zu aktualisieren, und dann sendet Nagios die Warnung gemäß der Kontaktgruppenkonfiguration.
Installieren Sie das EPEL-Repository, gefolgt von den erforderlichen Paketen:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogKonfigurieren Sie den SNMP-Trap-Daemon unter /etc/snmp/snmptrapd.conf und setzen Sie die folgenden Zeilen:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerDas Obige bedeutet einfach, dass vom snmptrapd-Daemon empfangene Traps an /usr/sbin/snmptthandler weitergeleitet werden.
Fügen Sie die SEVERALNINES-CLUSTERCONTROL-MIB.txt in /usr/share/snmp/mibs hinzu, indem Sie /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt erstellen:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtErstellen Sie /etc/snmp/snmp.conf (Hinweis ohne das "d") und fügen Sie dort unsere benutzerdefinierte MIB hinzu:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBStarten Sie den snmptrapd-Dienst:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdAls nächstes müssen wir die folgenden Konfigurationszeilen in /etc/snmp/snmptt.ini konfigurieren:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDBeachten Sie, dass wir das net_snmp_perl-Modul aktiviert und einen weiteren Konfigurationspfad hinzugefügt haben, /etc/snmp/snmptt-cc.conf innerhalb von snmptt.ini. Wir müssen hier ClusterControl snmptt-Ereignisse definieren, damit sie an Nagios übergeben werden können. Erstellen Sie eine neue Datei unter /etc/snmp/snmptt-cc.conf und fügen Sie die folgenden Zeilen hinzu:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCEinige Erklärungen:
-
Wir haben zwei Traps definiert - kritischeAlarmNotifikation und kritischeAlarmNotifikationEnded.
-
Die criticalAlarmNotification löst einfach einen kritischen Alarm aus und leitet ihn an den in Nagios definierten "Critical Alarm Traps"-Dienst weiter. Das $aA bedeutet, die IP-Adresse des Trap-Agenten zurückzugeben. Der Wert 2 ist der Prüfergebniswert, der in diesem Fall kritisch ist (0=OK, 1=WARNUNG, 2=KRITISCH, 3=UNBEKANNT).
-
Die criticalAlarmNotificationEnded löst einfach eine OK-Warnung aus und leitet sie an den Dienst „Critical Alarm Traps“ weiter, um dies abzubrechen vorherige Falle, nachdem alles wieder normal ist. Das $aA bedeutet, die IP-Adresse des Trap-Agenten zurückzugeben. Der Wert 0 ist der Prüfergebniswert, der in diesem Fall OK ist. Weitere Einzelheiten zu von snmptt erkannten Zeichenfolgenersetzungen finden Sie in diesem Artikel im Abschnitt "FORMAT".
-
Sie können snmpttconvertmib verwenden, um eine snmptt-Event-Handler-Datei für eine bestimmte MIB zu generieren.
Beachten Sie, dass der Eventhandlers-Pfad standardmäßig nicht vom Nagios Core bereitgestellt wird. Daher müssen wir dieses eventhandlers-Verzeichnis aus der Nagios-Quelle in das contrib-Verzeichnis kopieren, wie unten gezeigt:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersWir müssen auch die snmptt-Gruppe als Teil der nagcmd-Gruppe zuweisen, damit sie die nagios.cmd innerhalb des submit_check_result-Skripts ausführen kann:
$ usermod -a -G nagcmd snmpttStarten Sie den snmptt-Dienst:
$ systemctl start snmptt
$ systemctl enable snmpttDer SNMP-Manager (Nagios-Server) ist nun bereit, unsere eingehenden SNMP-Traps zu akzeptieren und zu verarbeiten.
Trap vom ClusterControl-Server senden
Angenommen, man möchte einen SNMP-Trap an den SNMP-Manager 192.168.10.11 (Nagios-Server) senden, weil die Gesamtzahl der kritischen Alarme 2 für Cluster-ID 1 erreicht hat, würde man den folgenden Befehl ausführen der ClusterControl-Server (clientseitig), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Oder im OID-Format (empfohlen):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Wobei .1.3.6.1.4.1.57397.1.1.3.1 gleich dem Trap-Ereignis "criticalAlarmNotification" ist und die nachfolgenden OIDs Darstellungen der Gesamtzahl der aktuellen kritischen Alarme bzw. der Cluster-ID sind .
Auf dem Nagios-Server sollten Sie feststellen, dass der Trap-Dienst rot geworden ist:
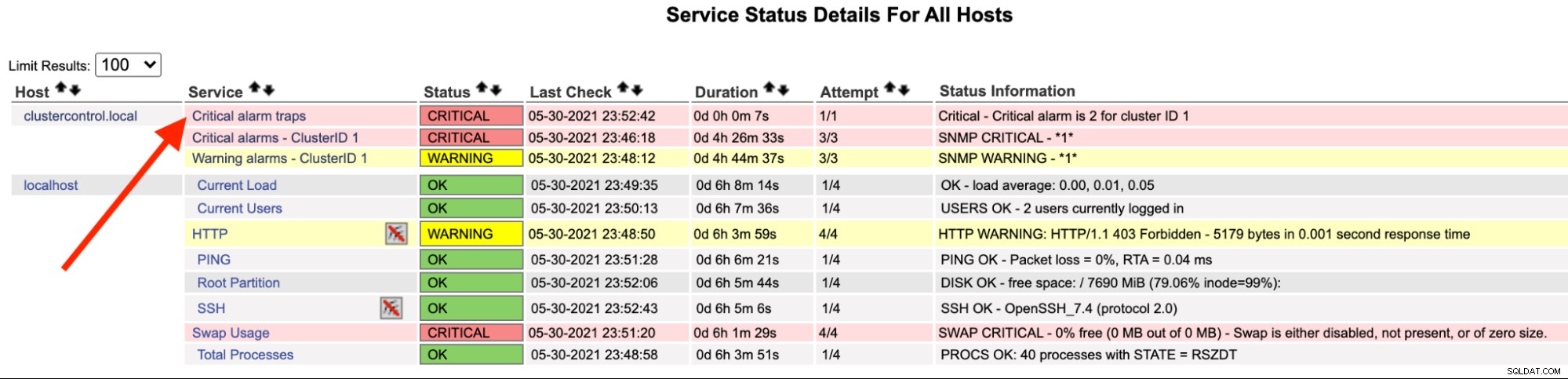
Sie können es auch in /var/log/messages der folgenden Zeile sehen:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Sobald der Alarm behoben ist, können wir den folgenden Befehl ausführen, um einen normalen Trap zu senden:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Wobei .1.3.6.1.4.1.57397.1.1.3.2 gleich dem Ereignis "criticalAlarmNotificationEnded" ist und die nachfolgenden OIDs Darstellungen der Gesamtzahl der aktuellen kritischen Alarme sind (sollte in diesem Fall 0 sein ) bzw. die Cluster-ID.
Auf dem Nagios-Server sollten Sie feststellen, dass der Trap-Dienst wieder grün ist:
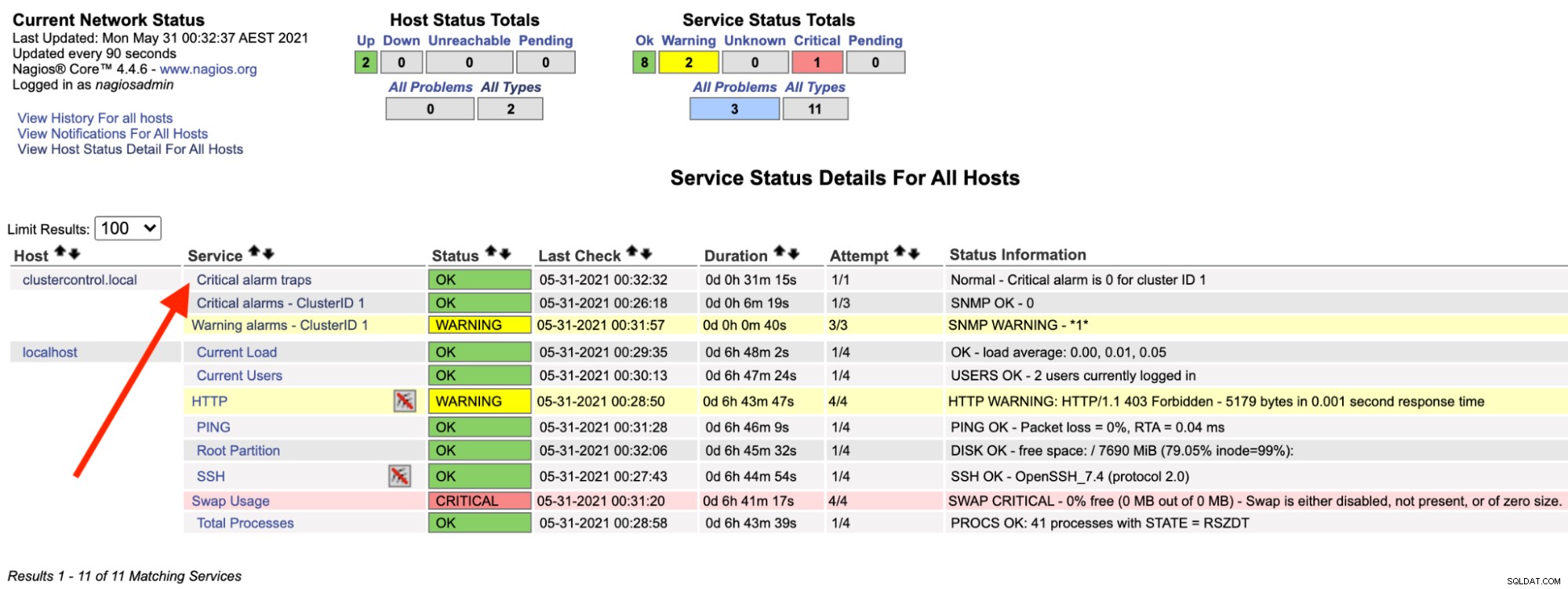
Das obige kann mit einem einfachen Bash-Skript automatisiert werden:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneUm das Skript im Hintergrund auszuführen, tun Sie einfach:
$ bash alarmtrapper.bash &An diesem Punkt sollten wir in der Lage sein, den "Critical Alarm Traps"-Dienst von Nagios automatisch in Aktion zu sehen, wenn in unserem Cluster automatisch ein Fehler auftritt.
Abschließende Gedanken
In dieser Blogserie haben wir einen Proof-of-Concept gezeigt, wie ClusterControl für die Überwachung, Generierung/Verarbeitung von Traps und Alarmierung mit dem SNMP-Protokoll konfiguriert werden kann. Dies markiert auch den Beginn unserer Reise zur Integration von SNMP in unsere zukünftigen Versionen. Bleiben Sie dran, wir werden weitere Updates zu dieser aufregenden Funktion veröffentlichen.



