Database Load Balancing verteilt gleichzeitige Client-Anfragen auf mehrere Datenbankserver, um die Last auf jedem einzelnen Server zu reduzieren. Dies kann die Leistung Ihrer Datenbank drastisch verbessern. Glücklicherweise kann MongoDB standardmäßig die Anfragen mehrerer Clients verarbeiten, dieselben Daten gleichzeitig zu lesen und zu schreiben. Es verwendet einige Parallelitätskontrollmechanismen und Sperrprotokolle, um die Datenkonsistenz jederzeit sicherzustellen.
Auf diese Weise stellt MongoDB auch sicher, dass alle Clients jederzeit eine konsistente Sicht auf die Daten erhalten. Aufgrund dieser integrierten Funktion zur Verarbeitung von Anfragen von mehreren Clients müssen Sie sich keine Gedanken über das Hinzufügen eines externen Lastenausgleichs auf Ihren MongoDB-Servern machen. Wenn Sie dennoch die Leistung Ihrer Datenbank mithilfe von Load Balancing verbessern möchten, finden Sie hier einige Möglichkeiten, dies zu erreichen.
Vertikale MongoDB-Skalierung
In einfachen Worten bedeutet vertikales Skalieren, Ihrem Server mehr Ressourcen hinzuzufügen, um das Laden zu bewältigen. Wie alle Datenbanksysteme bevorzugt MongoDB mehr RAM- und IO-Kapazität. Dies ist die einfachste Möglichkeit, die Leistung von MongoDB zu steigern, ohne die Last auf mehrere Server zu verteilen. Die vertikale Skalierung der MongoDB-Datenbank umfasst in der Regel die Erhöhung der CPU-Kapazität oder der Festplattenkapazität und die Erhöhung des Durchsatzes (E/A-Vorgänge). Durch das Hinzufügen weiterer Ressourcen wird Ihr Mongo-Server besser in der Lage, die Anfragen mehrerer Clients zu verarbeiten. Somit besseres Load-Balancing für Ihre Datenbank.
Der Nachteil bei der Verwendung dieses Ansatzes ist die technische Einschränkung beim Hinzufügen von Ressourcen zu einem einzelnen System. Außerdem haben alle Cloud-Anbieter Einschränkungen beim Hinzufügen neuer Hardwarekonfigurationen. Der andere Nachteil dieses Ansatzes ist ein Single Point of Failure. Bei diesem Ansatz werden alle Ihre Daten in einem einzigen System gespeichert, was zu einem dauerhaften Verlust Ihrer Daten führen kann.
Horizontale MongoDB-Skalierung
Horizontale Skalierung bezieht sich auf die Aufteilung Ihrer Datenbank in Chunks und deren Speicherung auf mehreren Servern. Der Hauptvorteil dieses Ansatzes besteht darin, dass Sie zusätzliche Server im Handumdrehen hinzufügen können, um Ihre Datenbankleistung ohne Ausfallzeiten zu steigern. MongoDB bietet horizontale Skalierung durch Sharding. MongoDB-Sharding bietet zusätzliche Kapazität, um die Schreiblast auf mehrere Server (Shards) zu verteilen. Hier kann jeder Shard als eine unabhängige Datenbank und die Sammlung aller Shards als eine große logische Datenbank betrachtet werden. Sharding ermöglicht Ihrer MongoDB, die Daten auf mehrere Server zu verteilen, um gleichzeitige Client-Anfragen effizient zu verarbeiten. Daher erhöht es den Lese- und Schreibdurchsatz Ihrer Datenbank.
MongoDB-Sharding
Ein Shard kann eine einzelne Mongod-Instanz oder ein Replikatsatz sein, der die Teilmenge der Mongo-Shard-Datenbank enthält. Sie können Shard im Replikatsatz konvertieren, um eine hohe Datenverfügbarkeit und Redundanz zu gewährleisten.
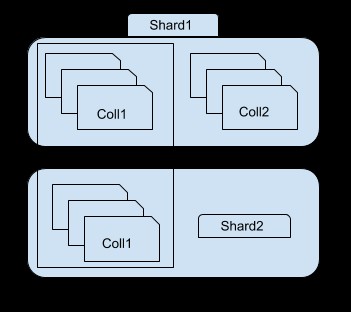
Wie Sie im obigen Bild sehen können, enthält Shard 1 eine Teilmenge von Sammlung 1 und ganze Sammlung2, während Shard 2 nur eine andere Teilmenge von Sammlung1 enthält. Sie können über die Mongos-Instanz auf jeden Shard zugreifen. Wenn Sie sich beispielsweise mit der Shard1-Instanz verbinden, können Sie nur eine Teilmenge von Sammlung1 sehen/auf sie zugreifen.
Mongos
Mongos ist der Abfrage-Router, der den Zugriff auf Sharding-Cluster für Client-Anwendungen bereitstellt. Sie können mehrere Mongos-Instanzen für einen besseren Lastausgleich haben. Beispielsweise können Sie in Ihrem Produktionscluster eine Mongos-Instanz für jeden Anwendungsserver haben. Hier können Sie jetzt einen externen Load Balancer verwenden, der die Anfrage Ihres Anwendungsservers an die entsprechende Mongos-Instanz umleitet. Stellen Sie beim Hinzufügen solcher Konfigurationen zu Ihrem Produktionsserver sicher, dass die Verbindung von jedem Client immer mit derselben Mongos-Instanz verbunden wird, da einige Mongo-Ressourcen wie Cursor für die Mongos-Instanz spezifisch sind.
Server konfigurieren
Konfigurationsserver speichern die Konfigurationseinstellungen und Metadaten zu Ihrem Cluster. Ab MongoDB Version 3.4 müssen Sie Konfigurationsserver als Replikatsatz bereitstellen. Wenn Sie Sharding in einer Produktionsumgebung aktivieren, müssen Sie unbedingt drei separate Konfigurationsserver verwenden, die sich jeweils auf verschiedenen Computern befinden.
Sie können dieser Anleitung folgen, um Ihren Replikatsatz-Cluster in einen fragmentierten Cluster umzuwandeln. Hier ist die Beispieldarstellung eines Shard-Produktionsclusters:
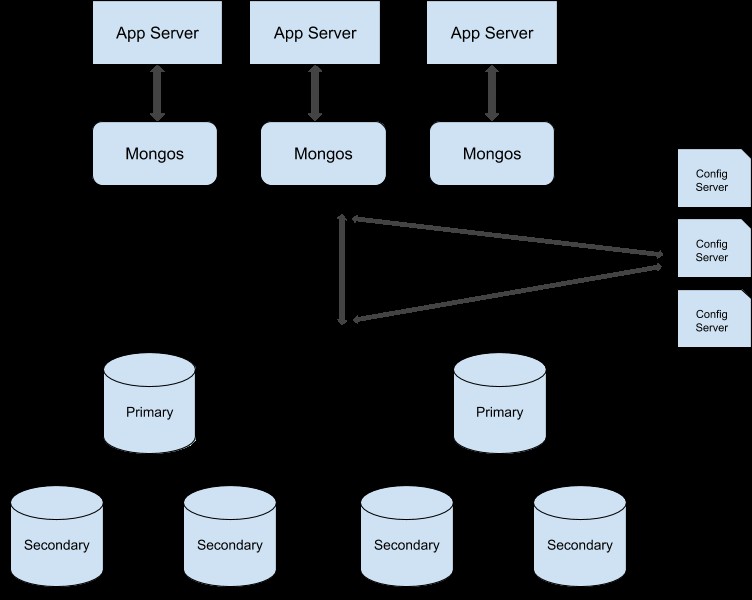
MongoDB-Load-Balancing mithilfe von Replikation
Manchmal kann die MongoDB-Replikation verwendet werden, um mehr Datenverkehr von Clients zu bewältigen und die Last auf dem primären Server zu reduzieren. Dazu können Sie Clients anweisen, von Sekundärservern statt vom Primärserver zu lesen. Dies kann die Belastung des primären Servers reduzieren, da alle Leseanfragen von Clients von sekundären Servern verarbeitet werden und der primäre Server sich nur um Schreibanfragen kümmert.
Folgend ist der Befehl, um die Lesepräferenz auf sekundär zu setzen:
db.getMongo().setReadPref('secondary')Sie können auch einige Tags spezifizieren, um auf bestimmte Secondarys abzuzielen, während die Leseabfragen verarbeitet werden.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Hier versucht MongoDB, den sekundären Knoten mit dem Tag-Wert des Rechenzentrums als APAC zu finden. Wenn gefunden, bedient Mongo die Leseanforderungen von allen sekundären Servern mit dem Tag datacenter:„APAC“. Wenn es nicht gefunden wird, versucht Mongo, Secondaries mit der Tag-Region „East“ zu finden. Wenn immer noch keine Secondaries gefunden werden, funktioniert {} als Standardfall und Mongo bedient die Anfragen von allen berechtigten Secondaries.
Dieser Ansatz für den Lastenausgleich ist jedoch nicht ratsam, um den Lesedurchsatz zu erhöhen. Weil jeder Lesepräferenzmodus außer dem primären Server alte Daten zurückgeben kann, wenn kürzlich Schreibaktualisierungen auf dem primären Server vorgenommen wurden. Normalerweise braucht der primäre Server einige Zeit, um die Schreibanforderungen zu bearbeiten und die Änderungen an die sekundären Server weiterzugeben. Wenn während dieser Zeit jemand einen Lesevorgang für dieselben Daten anfordert, gibt der sekundäre Server veraltete Daten zurück, da er nicht mit dem primären Server synchronisiert ist. Sie können diesen Ansatz verwenden, wenn Ihre Anwendung Lesevorgänge im Vergleich zu Schreibvorgängen erfordert.
Fazit
Da MongoDB gleichzeitige Anfragen selbst verarbeiten kann, ist es nicht erforderlich, einen Load Balancer in Ihrem MongoDB-Cluster hinzuzufügen. Für den Lastenausgleich der Clientanforderungen können Sie entweder die vertikale Skalierung oder die horizontale Skalierung auswählen, da es nicht ratsam ist, Secondaries zum Aufskalieren Ihrer Lese- und Schreibvorgänge zu verwenden. Die vertikale Skalierung kann, wie oben besprochen, an die technischen Grenzen stoßen. Daher ist es für kleine Anwendungen geeignet. Für große Anwendungen ist die horizontale Skalierung durch Sharding der beste Ansatz für den Lastenausgleich der Lese- und Schreibvorgänge.



