Die Verbesserung der Systemleistung, insbesondere für Computerstrukturen, erfordert einen Prozess, um sich einen guten Überblick über die Leistung zu verschaffen. Dieser Vorgang wird allgemein als Überwachung bezeichnet. Die Überwachung ist ein wesentlicher Bestandteil des Datenbankmanagements und die detaillierten Leistungsinformationen Ihrer MongoDB helfen Ihnen nicht nur dabei, ihren Funktionszustand einzuschätzen; sondern geben auch einen Hinweis auf Anomalien, was bei der Wartung hilfreich ist. Es ist wichtig, ungewöhnliches Verhalten zu erkennen und zu beheben, bevor es zu schwerwiegenderen Fehlern eskaliert.
Einige der Arten von Fehlern, die auftreten könnten, sind...
- Verzögerung oder Verlangsamung
- Ressourcenunzulänglichkeit
- Systemfehler
Die Überwachung konzentriert sich häufig auf die Analyse von Metriken. Zu den wichtigsten Metriken, die Sie überwachen sollten, gehören...
- Leistung der Datenbank
- Ressourcennutzung (CPU-Nutzung, verfügbarer Arbeitsspeicher und Netzwerknutzung)
- Aufkommende Rückschläge
- Sättigung und Begrenzung der Ressourcen
- Durchsatzoperationen
In diesem Blog werden wir diese Metriken im Detail besprechen und uns verfügbare Tools von MongoDB ansehen (z. B. Dienstprogramme und Befehle). Wir werden uns auch andere Softwaretools wie Pandora, FMS Open Source und Robo 3T ansehen. Der Einfachheit halber verwenden wir in diesem Artikel die Robo 3T-Software, um die Metriken zu demonstrieren.
Leistung der Datenbank
Das Wichtigste, was man bei einer Datenbank überprüfen sollte, ist ihre allgemeine Performance, zum Beispiel, ob der Server aktiv ist oder nicht. Wenn Sie diesen Befehl db.serverStatus() auf einer Datenbank in Robo 3T ausführen, werden Ihnen diese Informationen präsentiert, die den Status Ihres Servers zeigen.
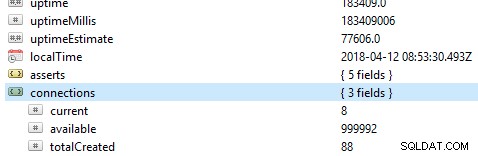

Replik-Sets
Replikatsatz ist eine Gruppe von Mongod-Prozessen, die denselben Datensatz verwalten. Wenn Sie Replikatsätze insbesondere im Produktionsmodus verwenden, bilden Betriebsprotokolle eine Grundlage für den Replikationsprozess. Alle Schreibvorgänge werden mithilfe von Knoten verfolgt, d. h. einem primären Knoten und einem sekundären Knoten, die eine Sammlung begrenzter Größe speichern. Auf dem primären Knoten werden die Schreibvorgänge angewendet und verarbeitet. Wenn jedoch der primäre Knoten ausfällt, bevor sie in die Betriebsprotokolle kopiert werden, wird das sekundäre Schreiben durchgeführt, aber in diesem Fall werden die Daten möglicherweise nicht repliziert.
Wichtige Kennzahlen, die Sie im Auge behalten sollten...
Replikationsverzögerung
Dies definiert, wie weit der sekundäre Knoten hinter dem primären Knoten liegt. Ein optimaler Zustand erfordert, dass der Spalt so klein wie möglich ist. Auf einem normalen Betriebssystem wird diese Verzögerung auf 0 geschätzt. Wenn die Lücke zu groß ist, wird die Datenintegrität beeinträchtigt, sobald der sekundäre Knoten zum primären Knoten hochgestuft wird. In diesem Fall können Sie einen Schwellenwert festlegen, z. B. 1 Minute, und wenn dieser überschritten wird, wird eine Warnung gesetzt. Häufige Ursachen für eine große Replikationsverzögerung sind...
- Shards, die möglicherweise eine unzureichende Schreibkapazität haben, was oft mit Ressourcensättigung verbunden ist.
- Der sekundäre Knoten stellt Daten langsamer bereit als der primäre Knoten.
- Knoten können auch in irgendeiner Weise an der Kommunikation gehindert werden, möglicherweise aufgrund eines schlechten Netzwerks.
- Vorgänge auf dem primären Knoten könnten auch langsamer sein und dadurch die Replikation blockieren. In diesem Fall können Sie die folgenden Befehle ausführen:
- db.getProfilingLevel():Wenn Sie einen Wert von 0 erhalten, dann sind Ihre DB-Operationen optimal.
Wenn der Wert 1 ist, dann entspricht dies langsamen Operationen, was folglich auf langsame Abfragen zurückzuführen sein kann. - db.getProfilingStatus():In diesem Fall prüfen wir den Wert von slowms, standardmäßig sind es 100ms. Wenn der Wert größer ist, haben Sie möglicherweise umfangreiche Schreibvorgänge auf dem primären oder unzureichende Ressourcen auf dem sekundären. Um dieses Problem zu lösen, können Sie den sekundären Server so skalieren, dass er genauso viele Ressourcen wie der primäre hat.
- db.getProfilingLevel():Wenn Sie einen Wert von 0 erhalten, dann sind Ihre DB-Operationen optimal.
Cursor
Wenn Sie beispielsweise eine Leseanforderung stellen, wird Ihnen ein Cursor bereitgestellt, der ein Zeiger auf den Datensatz des Ergebnisses ist. Wenn Sie diesen Befehl db.serverStatus() ausführen und zum Metrikobjekt und dann zum Cursor navigieren, sehen Sie Folgendes …

In diesem Fall wurde die Eigenschaft cursor.timeOut schrittweise auf 9 aktualisiert, da 9 Verbindungen abgebrochen wurden, ohne dass der Cursor geschlossen wurde. Die Folge ist, dass es auf dem Server geöffnet bleibt und daher Speicher verbraucht, es sei denn, es wird durch die Standardeinstellung von MongoDB geerntet. Eine Warnung an Sie sollte darin bestehen, nicht aktive Cursor zu identifizieren und sie zu entfernen, um Speicherplatz zu sparen. Sie können auch Nicht-Timeout-Cursor vermeiden, da sie häufig Ressourcen festhalten und dadurch die interne Systemleistung verlangsamen. Dies kann erreicht werden, indem der Wert der Eigenschaft cursor.open.noTimeout auf den Wert 0 gesetzt wird.
Journaling
In Anbetracht der WiredTiger Storage Engine werden Daten, bevor sie aufgezeichnet werden, zuerst in die Festplattendateien geschrieben. Dies wird als Journaling bezeichnet. Das Journaling stellt die Verfügbarkeit und Dauerhaftigkeit von Daten zu einem Fehlerereignis sicher, aus denen eine Wiederherstellung durchgeführt werden kann.
Zum Zwecke der Wiederherstellung verwenden wir häufig Checkpoints (insbesondere für das WiredTiger-Speichersystem), um vom letzten Checkpoint wiederherzustellen. Wenn MongoDB jedoch unerwartet heruntergefahren wird, verwenden wir die Journaling-Technik, um alle Daten wiederherzustellen, die nach dem letzten Prüfpunkt verarbeitet oder bereitgestellt wurden.
Das Journaling sollte im ersten Fall nicht ausgeschaltet werden, da es nur etwa 60 Sekunden dauert, um einen neuen Checkpoint zu erstellen. Wenn also ein Fehler auftritt, kann MongoDB das Journal wiederholen, um Daten wiederherzustellen, die innerhalb dieser Sekunden verloren gegangen sind.
Durch das Journaling wird im Allgemeinen das Zeitintervall zwischen dem Anlegen von Daten an den Speicher und der dauerhaften Speicherung auf der Festplatte verkürzt. Das Objekt storage.journal hat eine Eigenschaft, die die Commit-Häufigkeit beschreibt, also commitIntervalMs, die für WiredTiger oft auf einen Wert von 100 ms gesetzt ist. Wenn Sie ihn auf einen niedrigeren Wert einstellen, wird die häufige Aufzeichnung von Schreibvorgängen verbessert, wodurch Datenverluste reduziert werden.
Sperrleistung
Dies kann durch mehrere Lese- und Schreibanforderungen von vielen Clients verursacht werden. In diesem Fall muss die Konsistenz gewahrt und Schreibkonflikte vermieden werden. Um dies zu erreichen, verwendet MongoDB Multi-Granularity-Locking, wodurch Sperrvorgänge auf verschiedenen Ebenen stattfinden können, z. B. auf globaler, Datenbank- oder Sammlungsebene.
Wenn Sie schlechte Schemaentwurfsmuster haben, sind Sie anfällig für Sperren, die lange gehalten werden. Dies tritt häufig auf, wenn zwei oder mehr verschiedene Schreibvorgänge auf ein einzelnes Dokument in derselben Sammlung ausgeführt werden, mit der Folge, dass sie sich gegenseitig blockieren. Für die WiredTiger-Speicher-Engine können wir das Ticketsystem verwenden, bei dem Lese- oder Schreibanforderungen von so etwas wie einer Warteschlange oder einem Thread kommen.
Standardmäßig wird die Anzahl gleichzeitiger Lese- und Schreibvorgänge durch die Parameter wiredTigerConcurrentWriteTransactions und wiredTigerConcurrentReadTransactions definiert, die beide auf den Wert 128 gesetzt sind.
Wenn Sie diesen Wert zu hoch skalieren, werden Sie am Ende durch CPU-Ressourcen begrenzt. Um den Durchsatz von Operationen zu erhöhen, wäre es ratsam, horizontal zu skalieren, indem mehr Shards bereitgestellt werden.
Multiplenines Become a MongoDB DBA – Bringing MongoDB to ProductionErfahren Sie, was Sie wissen müssen, um MongoDBDownload for Free bereitzustellen, zu überwachen, zu verwalten und zu skalierenRessourcennutzung
Dies beschreibt allgemein die Nutzung verfügbarer Ressourcen wie CPU-Kapazität/Verarbeitungsrate und RAM. Die Leistung, insbesondere für die CPU, kann sich entsprechend ungewöhnlicher Verkehrslasten drastisch ändern. Zu den zu überprüfenden Dingen gehören...
- Anzahl der Verbindungen
- Speicherung
- Zwischenspeichern
Anzahl der Verbindungen
Wenn die Anzahl der Verbindungen höher ist als das, was das Datenbanksystem verarbeiten kann, kommt es zu vielen Warteschlangen. Folglich wird dies die Leistung der Datenbank überfordern und Ihr Setup verlangsamen. Diese Nummer kann zu Treiberproblemen oder sogar Komplikationen mit Ihrer Anwendung führen.
Wenn Sie eine bestimmte Anzahl von Verbindungen über einen bestimmten Zeitraum überwachen und dann feststellen, dass dieser Wert seinen Höchststand erreicht hat, empfiehlt es sich immer, eine Warnung einzurichten, wenn die Verbindung diese Zahl überschreitet.
Wenn die Zahl zu hoch wird, können Sie skalieren, um diesem Anstieg gerecht zu werden. Dazu müssen Sie die Anzahl der verfügbaren Verbindungen innerhalb eines bestimmten Zeitraums kennen, andernfalls werden Anfragen nicht rechtzeitig bearbeitet, wenn die verfügbaren Verbindungen nicht ausreichen.
Standardmäßig unterstützt MongoDB bis zu 1 Million Verbindungen. Stellen Sie bei Ihrer Überwachung immer sicher, dass die aktuellen Verbindungen diesem Wert nie zu nahe kommen. Sie können den Wert im Verbindungsobjekt überprüfen.

Speicherung
Jede Zeile und jeder Datensatz in MongoDB wird als Dokument bezeichnet. Dokumentdaten sind im BSON-Format. Wenn Sie für eine bestimmte Datenbank den Befehl db.stats() ausführen, werden Ihnen diese Daten angezeigt.
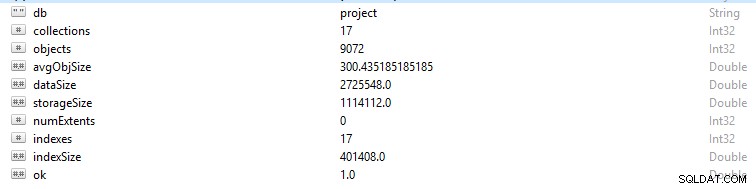
- StorageSize definiert die Größe aller Datenbereiche in der Datenbank.
- IndexSize beschreibt die Größe aller in dieser Datenbank erstellten Indizes.
- dataSize ist ein Maß für den gesamten Speicherplatz, den die Dokumente in der Datenbank einnehmen.
Sie können manchmal eine Änderung im Speicher sehen, insbesondere wenn viele Daten gelöscht wurden. In diesem Fall sollten Sie eine Warnung einrichten, um sicherzustellen, dass es sich nicht um böswillige Aktivitäten handelt.
Manchmal kann die Gesamtspeichergröße explodieren, während das Diagramm des Datenbankverkehrs konstant ist, und in diesem Fall sollten Sie Ihre Anwendung oder Datenbankstruktur überprüfen, um zu vermeiden, dass Duplikate vorhanden sind, wenn diese nicht benötigt werden.
Wie der allgemeine Speicher eines Computers verfügt auch MongoDB über Caches, in denen aktive Daten zwischengespeichert werden. Eine Operation kann jedoch Daten anfordern, die sich nicht in diesem aktiven Speicher befinden, wodurch eine Anforderung vom Hauptplattenspeicher gestellt wird. Diese Anforderung oder Situation wird als Seitenfehler bezeichnet. Seitenfehleranforderungen haben die Einschränkung, dass die Ausführung länger dauert, und können nachteilig sein, wenn sie häufig auftreten. Um dieses Szenario zu vermeiden, stellen Sie sicher, dass die Größe Ihres Arbeitsspeichers immer ausreicht, um den Datensätzen gerecht zu werden, mit denen Sie arbeiten. Sie sollten auch sicherstellen, dass Sie keine Schemaredundanz oder unnötige Indizes haben.
Zwischenspeichern
Cache ist ein temporäres Datenspeicherelement für häufig aufgerufene Daten. In WiredTiger werden häufig der Dateisystem-Cache und der Speicher-Engine-Cache verwendet. Stellen Sie immer sicher, dass Ihr Arbeitssatz nicht über den verfügbaren Cache hinausgeht, da sonst die Anzahl der Seitenfehler zunimmt und einige Leistungsprobleme verursacht.
An einem bestimmten Punkt entscheiden Sie sich möglicherweise dafür, Ihre häufigen Vorgänge zu ändern, aber die Änderungen werden manchmal nicht im Cache widergespiegelt. Diese unveränderten Daten werden als „Dirty Data“ bezeichnet. Es ist vorhanden, weil es noch nicht auf die Festplatte geschrieben wurde. Engpässe entstehen, wenn die Menge an „Dirty Data“ auf einen Durchschnittswert anwächst, der durch langsames Schreiben auf die Festplatte definiert wird. Das Hinzufügen weiterer Shards hilft, diese Zahl zu reduzieren.
CPU-Auslastung
Unsachgemäße Indizierung, schlechte Schemastruktur und unfreundlich gestaltete Abfragen erfordern mehr CPU-Aufmerksamkeit und erhöhen daher offensichtlich die Auslastung.
Durchsatzoperationen
Das Einholen ausreichender Informationen über diese Vorgänge kann es einem weitgehend ermöglichen, Folgerückschläge wie Fehler, Ressourcenüberlastung und funktionelle Komplikationen zu vermeiden.
Sie sollten immer die Anzahl der Lese- und Schreibvorgänge in der Datenbank notieren, dh eine allgemeine Ansicht der Aktivitäten des Clusters. Wenn Sie die Anzahl der für die Anforderungen generierten Operationen kennen, können Sie die Last berechnen, die die Datenbank voraussichtlich verarbeiten wird. Die Last kann dann entweder durch Hochskalieren Ihrer Datenbank oder durch Hochskalieren gehandhabt werden. abhängig von der Art der Ressourcen, die Sie haben. Auf diese Weise können Sie leicht das Quotientenverhältnis messen, in dem sich die Anfragen zu der Rate anhäufen, mit der sie verarbeitet werden. Außerdem können Sie Ihre Abfragen entsprechend optimieren, um die Performance zu verbessern.
Um die Anzahl der Lese- und Schreibvorgänge zu überprüfen, führen Sie diesen Befehl db.serverStatus() aus und navigieren Sie dann zum locks.global-Objekt, der Wert für die Eigenschaft r repräsentiert die Anzahl der Leseanforderungen und w die Anzahl der Schreibvorgänge.
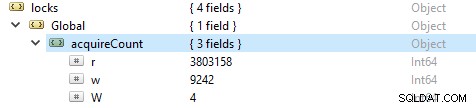
Häufiger sind die Leseoperationen mehr als die Schreiboperationen. Aktive Client-Metriken werden unter globalLock gemeldet.
Sättigung und Begrenzung der Ressourcen
Manchmal hält die Datenbank möglicherweise nicht mit der Schreib- und Lesegeschwindigkeit Schritt, was sich in einer zunehmenden Anzahl von Anfragen in der Warteschlange zeigt. In diesem Fall müssen Sie Ihre Datenbank vergrößern, indem Sie mehr Shards bereitstellen, damit MongoDB die Anforderungen schnell genug bearbeiten kann.
Aufkommende Rückschläge
MongoDB-Protokolldateien geben immer einen allgemeinen Überblick über zurückgegebene Assert-Ausnahmen. Dieses Ergebnis gibt Ihnen einen Hinweis auf mögliche Fehlerursachen. Wenn Sie den Befehl db.serverStatus() ausführen, werden Sie folgende Fehlermeldungen bemerken:

- Regelmäßige Behauptungen:Diese sind das Ergebnis eines Vorgangsfehlers. Wenn beispielsweise in einem Schema ein Zeichenfolgenwert für ein Ganzzahlfeld bereitgestellt wird, führt dies zu einem Fehler beim Lesen des BSON-Dokuments.
- Warnung behauptet:Dies sind oft Warnungen zu einem bestimmten Problem, haben aber keine großen Auswirkungen auf den Betrieb. Wenn Sie beispielsweise Ihre MongoDB aktualisieren, werden Sie möglicherweise über veraltete Funktionen gewarnt.
- Msg behauptet:Sie sind das Ergebnis interner Server-Ausnahmen wie langsames Netzwerk oder wenn der Server nicht aktiv ist.
- Benutzer-Asserts:Wie normale Asserts treten diese Fehler beim Ausführen eines Befehls auf, werden jedoch häufig an den Client zurückgegeben. Zum Beispiel, wenn es doppelte Schlüssel, unzureichenden Speicherplatz oder keinen Zugriff zum Schreiben in die Datenbank gibt. Sie entscheiden sich dafür, Ihre Anwendung zu überprüfen, um diese Fehler zu beheben.



