Erfahren Sie mehr über die Datenerfassungsarchitektur nahezu in Echtzeit zum Transformieren und Anreichern von Datenströmen mit Apache Flume, Apache Kafka und RocksDB bei Santander UK.
Cloudera Professional Services hat mit Santander UK zusammengearbeitet, um ein Nahezu-Echtzeit-Transaktionsanalysesystem (NRT) auf Apache Hadoop aufzubauen. Ziel ist es, eine Transaktion innerhalb weniger Sekunden nach dem Kartenkauf zu erfassen, umzuwandeln, anzureichern, zu zählen und zu speichern. Das System empfängt die Transaktionen der Privatkundenkarte der Bank und berechnet die zugehörigen Trendinformationen aggregiert nach Kontoinhabern und über eine Reihe von Dimensionen und Taxonomien. Diese Informationen werden dann sicher an die „Spendlytics“-App von Santander (siehe unten) übermittelt, damit Kunden ihre neuesten Ausgabenmuster analysieren können.
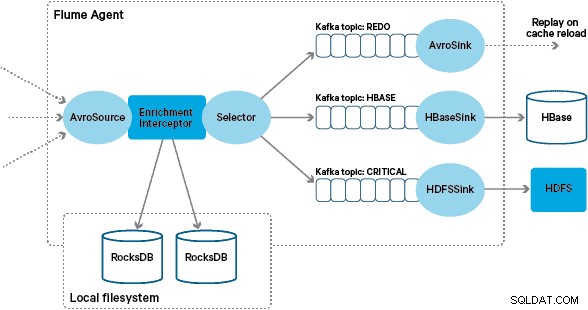
Apache HBase wurde als zugrunde liegende Speicherlösung gewählt, da es in der Lage ist, zufällige Schreibvorgänge mit hohem Durchsatz und zufällige Lesevorgänge mit geringer Latenz zu unterstützen. Die NRT-Anforderung schloss jedoch die Durchführung von Transformationen und Anreicherungen der Transaktionen im Batch aus, sodass diese durchgeführt werden müssen, während die Transaktionen in HBase gestreamt werden. Dazu gehört die Umwandlung von Nachrichten von XML in Avro und die Anreicherung mit trendfähigen Informationen wie Marken- und Händlerinformationen.
Dieser Beitrag beschreibt, wie Santander Apache Flume, Apache Kafka und RocksDB verwendet, um Transaktionen in HBase zu transformieren, anzureichern und zu streamen. Dies ist eine Implementierung der NRT-Ereignisverarbeitung mit externem Kontext Streaming-Muster, das von Ted Malaska in diesem Beitrag beschrieben wird.
Flafka
Die erste Entscheidung, die Santander treffen musste, war, wie Daten am besten in HBase gestreamt werden können. Flume ist fast immer die beste Wahl für die Streaming-Aufnahme in Hadoop, da es einfach, zuverlässig, reich an Quellen und Senken und inhärenter Skalierbarkeit ist.
Kürzlich wurde eine hervorragende Integration in Kafka hinzugefügt, was zu dem unweigerlich benannten Flafka führte. Flume kann nativ eine garantierte Ereignisbereitstellung über seinen Dateikanal bereitstellen, aber die Möglichkeit, Ereignisse wiederzugeben, und die zusätzliche Flexibilität und Zukunftssicherheit, die Kafka mit sich bringt, waren die Hauptgründe für die Integration.
In dieser Architektur verwendet Santander Kafka-Kanäle, um einen zuverlässigen, selbstausgleichenden und skalierbaren Aufnahmepuffer bereitzustellen, in dem alle Transformationen und Verarbeitungen in verketteten Kafka-Themen dargestellt werden. Insbesondere nutzen wir ausgiebig Flafkas Quelle und Senke sowie die Fähigkeit von Flume, die Verarbeitung während des Fluges mit Abfangjägern durchzuführen. Dadurch mussten wir keinen eigenen Kafka-Producer und -Consumer codieren, und Santander konnte Cloudera Manager optimal nutzen, um die Agenten und Broker zu konfigurieren, bereitzustellen und zu überwachen.
Verwandlung
Von den Core-Banking-Systemen erfasste Transaktionen werden als XML-Nachrichten an Flume geliefert, nachdem sie per Protokollreplikation aus der Quelldatenbank gelesen wurden. (Das Tailing eines Datenbankprotokolls in Kafka-Themen auf diese Weise ist ein immer häufigeres Muster und kann in Kombination mit der Protokollkomprimierung eine „neueste Ansicht“ der Datenbank für Anwendungsfälle zur Erfassung von Änderungsdaten liefern.)
Flume speichert diese XML-Nachrichten in einem „rohen“ Kafka-Thema. Von hier aus und als Vorläufer aller anderen Verarbeitungen wurde entschieden, das halbstrukturierte XML in strukturierte Binärdatensätze umzuwandeln, um eine standardisierte nachgelagerte Verarbeitung zu erleichtern. Diese Verarbeitung wird von einem benutzerdefinierten Flume Interceptor durchgeführt, der die XML-Nachrichten in eine generische Avro-Darstellung umwandelt, wobei er gegebenenfalls bestimmte Typen anwendet und auf eine Zeichenfolgendarstellung zurückgreift, wo dies nicht der Fall ist. Die gesamte nachfolgende NRT-Verarbeitung speichert dann abgeleitete Ergebnisse in Avro in dedizierten Kafka-Themen, wodurch es einfach ist, den Stream anzuzapfen und an jedem Punkt der Verarbeitungskette einen Ereignis-Feed zu erhalten.
Wenn eine komplexere Ereignisverarbeitung erforderlich wäre – beispielsweise Aggregationen mit Spark Streaming – wäre es eine triviale Angelegenheit, eines oder mehrere dieser Themen zu verwenden und in neu abgeleiteten Themen zu veröffentlichen. (Apache Avro ist eine natürliche Wahl für dieses Format:Es ist ein kompaktes Binärprotokoll, das die Schemaentwicklung unterstützt, eine flexible Schemadefinition hat und im gesamten Hadoop-Stack unterstützt wird. Avro entwickelt sich schnell zu einem De-facto-Standard für die Zwischenspeicherung und allgemeine Datenspeicherung in ein Enterprise Data Hub und ist perfekt für die Umwandlung in Apache Parquet für Analyse-Workloads geeignet.)
Bereicherung
Die Inspiration für das Design der Streaming-Anreicherungslösung kam von einem von Jay Kreps verfassten O’Reilly Radar-Beitrag. In seinem Beitrag beschreibt Jay die Vorteile der Verwendung eines lokalen Speichers, um es einem Stream-Prozessor zu ermöglichen, einen lokalen Status als Reaktion auf seine Eingabe abzufragen oder zu ändern, im Gegensatz zu Remote-Aufrufen an eine verteilte Datenbank.
Bei Santander haben wir dieses Muster angepasst, um lokale Referenzspeicher bereitzustellen, die zum Abfragen und Anreichern von Transaktionen verwendet werden, während sie durch Flume strömen. Warum nicht einfach HBase als Referenzspeicher verwenden? Nun, ein typisches Muster für diese Art von Problem besteht darin, den Status einfach in HBase zu speichern und den Anreicherungsmechanismus direkt abzufragen. Wir haben uns aus mehreren Gründen gegen diesen Ansatz entschieden. Erstens sind die Referenzdaten relativ klein und würden in eine einzelne HBase-Region passen, was wahrscheinlich einen Region-Hotspot verursacht. Zweitens bedient HBase die kundenorientierte Spendlytics-App, und Santander wollte nicht, dass die zusätzliche Last die Latenz der App beeinträchtigt oder umgekehrt. Dies ist auch der Grund, warum wir uns entschieden haben, HBase nicht einmal zum Bootstrap der lokalen Stores beim Start zu verwenden.
Indem jedem Flume-Agenten ein schneller lokaler Shop zur Bereicherung von Inflight-Events zur Verfügung gestellt wird, ist Santander in der Lage, bessere Leistungsgarantien sowohl für die Inflight-Anreicherung als auch für die Spendlytics-App zu geben. Wir haben uns für die Verwendung von RocksDB entschieden, um die lokalen Speicher zu implementieren, da es einen schnellen Zugriff auf große Mengen von Off-Heap-Daten bieten kann (wodurch die Belastung für GC entfällt) und weil es über eine Java-API verfügt, um die Verwendung zu vereinfachen ein benutzerdefinierter Flume Interceptor. Dieser Ansatz erspart uns die Programmierung unseres eigenen Off-Heap-Stores. RocksDB kann problemlos gegen eine andere lokale Store-Implementierung ausgetauscht werden, aber in diesem Fall passte es perfekt zum Anwendungsfall von Santander.
Die benutzerdefinierte Flume-Anreicherungs-Interceptor-Implementierung verarbeitet Ereignisse aus dem vorgelagerten „transformierten“ Thema, fragt ihren lokalen Speicher ab, um sie anzureichern, und schreibt die Ergebnisse je nach Ergebnis in nachgelagerte Kafka-Themen. Dieser Vorgang wird weiter unten ausführlicher dargestellt.
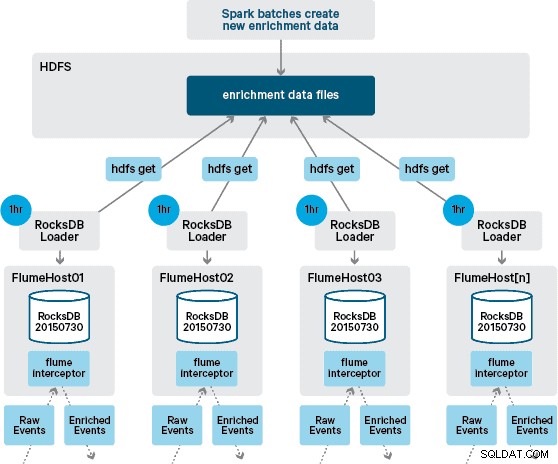
An dieser Stelle fragen Sie sich vielleicht:Wie werden lokale Speicher ohne von HBase bereitgestellte Persistenz generiert? Die Referenzdaten umfassen eine Reihe unterschiedlicher Datensätze, die zusammengeführt werden müssen. Diese Datensätze werden täglich in HDFS aktualisiert und bilden die Eingabe für eine geplante Apache Spark-Anwendung, die die RocksDB-Speicher generiert. Neu generierte RocksDB-Speicher werden in HDFS bereitgestellt, bis sie von den Flume-Agenten heruntergeladen werden, um sicherzustellen, dass der Ereignisstrom mit den neuesten Informationen angereichert wird.
Im Idealfall müssten wir nicht warten, bis diese Datensätze alle in HDFS verfügbar sind, bevor sie verarbeitet werden können. Wenn dies der Fall wäre, könnten Referenzdatenaktualisierungen durch die Flafka-Pipeline gestreamt werden, um den lokalen Referenzdatenstatus kontinuierlich aufrechtzuerhalten.
In unserem ursprünglichen Design hatten wir geplant, per Cron ein Skript zu schreiben und zu planen, um HDFS abzufragen, um nach neuen Versionen der RocksDB-Speicher zu suchen, und sie von HDFS herunterzuladen, wenn sie verfügbar sind. Obwohl dieser Mechanismus aufgrund der internen Kontrollen und der Governance der Produktionsumgebungen von Santander in denselben Flume Interceptor integriert werden musste, der zur Durchführung der Anreicherung verwendet wird (er prüft einmal pro Stunde auf Aktualisierungen, ist also kein teurer Vorgang). Wenn eine neue Version des Stores verfügbar ist, wird eine Aufgabe an einen Worker-Thread gesendet, um den neuen Store von HDFS herunterzuladen und in RocksDB zu laden. Dieser Prozess findet im Hintergrund statt, während der Anreicherungs-Interceptor den Stream weiter verarbeitet. Sobald die neue Version des Stores in RocksDB geladen ist, wechselt der Interceptor zur neuesten Version und der abgelaufene Store wird gelöscht. Derselbe Mechanismus wird verwendet, um die RocksDB-Speicher von einem Kaltstart zu booten, bevor der Interceptor versucht, Ereignisse anzureichern.
Erfolgreich angereicherte Nachrichten werden in ein Kafka-Thema geschrieben, um mit dem HBaseEventSerializer idempotent in HBase geschrieben zu werden.
Während der Ereignisstrom kontinuierlich verarbeitet wird, können neue Versionen des lokalen Speichers nur täglich generiert werden. Unmittelbar nachdem eine neue Version des lokalen Speichers von Flume geladen wurde, wird sie als neu angesehen“, obwohl sie vor der Verfügbarkeit einer neuen Version zunehmend veraltet wird. Folglich steigt die Anzahl der „Cache-Misses“, bis eine neuere Version des lokalen Speichers verfügbar ist. Beispielsweise können neue und aktualisierte Marken- und Händlerinformationen zu den Referenzdaten hinzugefügt werden, aber bis sie für die Anreicherungs-Interceptor-Transaktionen von Flume verfügbar gemacht werden, können sie nicht angereichert werden oder mit veralteten Informationen angereichert werden, die später erforderlich sind abgeglichen, nachdem sie in HBase gespeichert wurde.
Um diesen Fall zu handhaben, werden Cache-Fehlschläge (Ereignisse, die nicht angereichert werden können) mithilfe eines Flume-Selektors in ein „Redo“-Kafka-Thema geschrieben. Das Redo-Thema wird dann in das Quellthema des Anreicherungs-Interceptors zurückgespielt, wenn ein neuer lokaler Store verfügbar ist.
Um „Poison Messages“ (Ereignisse, bei denen die Anreicherung kontinuierlich fehlschlägt) zu verhindern, haben wir uns entschieden, einen Zähler zum Header eines Ereignisses hinzuzufügen, bevor wir ihn zum Redo-Thema hinzufügen. Ereignisse, die wiederholt zu diesem Thema auftreten, werden schließlich zu einem „kritischen“ Thema umgeleitet, das zur späteren Überprüfung und Behebung in HDFS geschrieben wird. Dieser Ansatz wird im ersten Diagramm veranschaulicht.
Schlussfolgerung
Um die wichtigsten Erkenntnisse aus diesem Beitrag zusammenzufassen:
- Die Verwendung einer Kette von Kafka-Themen zum Speichern gemeinsam genutzter Zwischendaten als Teil Ihrer Aufnahmepipeline ist ein effektives Muster.
- Sie haben mehrere Optionen zum Persistieren und Abfragen von Zustands- oder Referenzdaten in Ihrer NRT-Ingest-Pipeline. Bevorzugen Sie für diesen Zweck HBase als allgemeines Muster, wenn die Zusatzdaten groß sind, ziehen Sie jedoch die Verwendung von eingebetteten lokalen Speichern (wie RocksDB) oder JVM-Speicher in Betracht, wenn die Verwendung von HBase nicht praktikabel ist.
- Fehlerbehandlung ist wichtig. (Siehe #1 für Hilfe dazu.)
In einem Folgebeitrag werden wir beschreiben, wie wir HBase-Coprozessoren verwenden, um kundenbezogene Aggregationen historischer Kauftrends bereitzustellen, und wie Offline-Transaktionen im Batch verarbeitet werden, indem (Cloudera Labs-Projekt) SparkOnHBase (das kürzlich in die HBase-Trunk). Wir werden auch beschreiben, wie die Lösung entwickelt wurde, um die rechenzentrumsübergreifenden Hochverfügbarkeitsanforderungen des Kunden zu erfüllen.
James Kinley, Ian Buss und Rob Siwicki sind Lösungsarchitekten bei Cloudera.



