Das automatische Failover für die MySQL-Replikation wird seit vielen Jahren diskutiert.
Ist es eine gute Sache oder eine schlechte Sache?
Diejenigen mit langem Gedächtnis in der MySQL-Welt erinnern sich vielleicht an den GitHub-Ausfall im Jahr 2012, der hauptsächlich durch Software verursacht wurde, die die falschen Entscheidungen traf.
GitHub war damals gerade auf eine Kombination aus MySQL Replication, Corosync, Pacemaker und Percona Replication Manager umgestiegen. PRM entschied sich für ein Failover, nachdem Zustandsprüfungen auf dem Master fehlgeschlagen waren, der während einer Schemamigration überlastet war. Es wurde ein neuer Master ausgewählt, der jedoch aufgrund von Cold-Caches schlecht abschnitt. Die hohe Abfragelast von der ausgelasteten Site führte dazu, dass PRM-Heartbeats auf dem kalten Master erneut fehlschlugen, und PRM löste dann ein weiteres Failover zum ursprünglichen Master aus. Und die Probleme gingen einfach weiter, wie unten zusammengefasst.
 Quelle:Henrik Ingo &Massimo Brignoli bei Percona Live 2013
Quelle:Henrik Ingo &Massimo Brignoli bei Percona Live 2013 Spulen Sie ein paar Jahre vor und GitHub ist zurück mit einem ziemlich ausgeklügelten Framework für die Verwaltung der MySQL-Replikation und des automatisierten Failover! Wie Shlomi Noach es ausdrückt:
„Zu diesem Zweck setzen wir automatisierte Master-Failover ein. Die Zeit, die ein Mensch benötigen würde, um einen ausgefallenen Master aufzuwecken und zu reparieren, übersteigt unsere Erwartungen an die Verfügbarkeit, und der Betrieb eines solchen Failovers ist manchmal nicht trivial. Wir gehen davon aus, dass Master-Fehler automatisch innerhalb von 30 Sekunden oder weniger erkannt und wiederhergestellt werden, und wir erwarten, dass ein Failover zu einem minimalen Verlust verfügbarer Hosts führt.“
Die meisten Unternehmen sind nicht GitHub, aber man könnte argumentieren, dass kein Unternehmen Ausfälle mag. Ausfälle stören jedes Unternehmen und kosten Geld. Meine Vermutung ist, dass sich die meisten Unternehmen da draußen wahrscheinlich eine Art automatisiertes Failover gewünscht haben, und die Gründe, es nicht zu implementieren, sind wahrscheinlich die Komplexität der bestehenden Lösungen, mangelnde Kompetenz bei der Implementierung solcher Lösungen oder mangelndes Vertrauen in die Software eine so wichtige Entscheidung.
Es gibt eine Reihe von automatisierten Failover-Lösungen, einschließlich (und nicht beschränkt auf) MHA, MMM, MRM, mysqlfailover, Orchestrator und ClusterControl. Einige von ihnen sind seit einigen Jahren auf dem Markt, andere sind jüngeren Datums. Das ist ein gutes Zeichen, mehrere Lösungen bedeuten, dass der Markt vorhanden ist und die Leute versuchen, das Problem anzugehen.
Als wir das automatische Failover in ClusterControl entworfen haben, haben wir uns an ein paar Leitprinzipien gehalten:
-
Stellen Sie sicher, dass der Master wirklich tot ist, bevor Sie ein Failover durchführen
Im Falle einer Netzwerkpartition, bei der die Failover-Software den Kontakt zum Master verliert, wird sie ihn nicht mehr sehen. Aber der Master funktioniert möglicherweise gut und kann vom Rest der Replikationstopologie gesehen werden.
ClusterControl sammelt Informationen von allen Datenbankknoten sowie allen verwendeten Datenbank-Proxys/Load-Balancern und erstellt dann eine Darstellung der Topologie. Es wird kein Failover versucht, wenn die Slaves den Master sehen können, noch wenn ClusterControl sich über den Zustand des Masters nicht 100 % sicher ist.
ClusterControl macht es auch einfach, die Topologie des Setups sowie den Status der verschiedenen Knoten zu visualisieren (dies ist das Verständnis von ClusterControl für den Zustand des Systems, basierend auf den gesammelten Informationen).
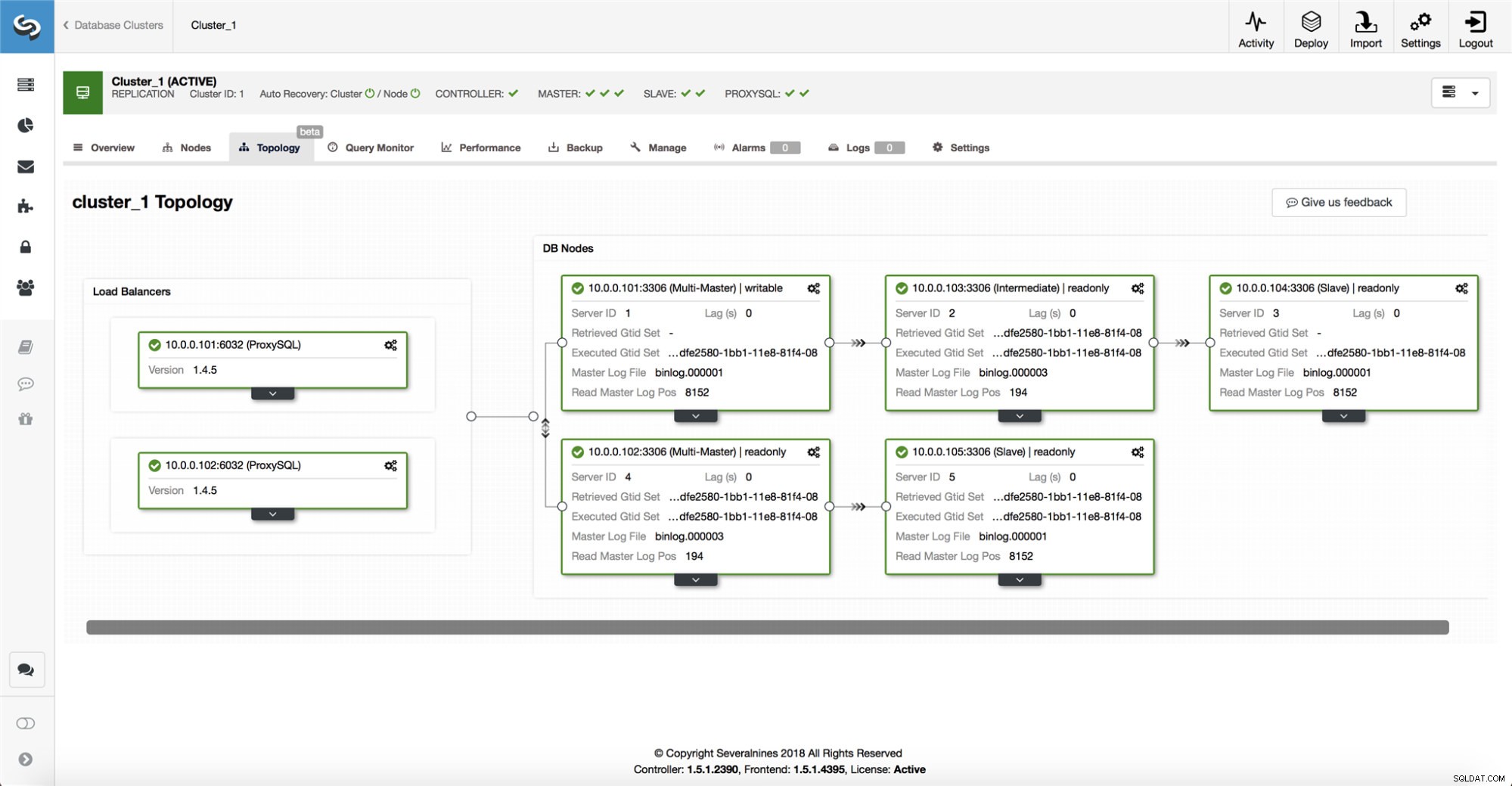
-
Failover nur einmal
Über das Flattern ist schon viel geschrieben worden. Es kann sehr chaotisch werden, wenn das Verfügbarkeitstool beschließt, mehrere Failover durchzuführen. Das ist eine gefährliche Situation. Jeder gewählte Master, egal wie kurz der Zeitraum, in dem er die Master-Rolle innehatte, könnte seine eigenen Änderungssätze haben, die nie auf einen Server repliziert wurden. Es kann also zu Unstimmigkeiten bei allen gewählten Meistern kommen.
-
Führen Sie kein Failover zu einem inkonsistenten Slave durch
Bei der Auswahl eines Sklaven, der zum Master befördert werden soll, stellen wir sicher, dass der Slave keine Inkonsistenzen aufweist, z. fehlerhafte Transaktionen, da dies sehr wohl die Replikation unterbrechen kann.
-
Nur an den Master schreiben
Die Replikation erfolgt vom Master zu den Slaves. Das direkte Schreiben an einen Slave würde einen abweichenden Datensatz erzeugen, und das kann eine potenzielle Problemquelle sein. Wir setzen die Slaves auf read_only und super_read_only in neueren Versionen von MySQL oder MariaDB. Wir empfehlen auch die Verwendung eines Load Balancers, z. B. ProxySQL oder MaxScale, um die Anwendungsschicht von der zugrunde liegenden Datenbanktopologie und allen Änderungen daran abzuschirmen. Der Load Balancer erzwingt auch Schreibvorgänge auf dem aktuellen Master.
-
Den ausgefallenen Master nicht automatisch wiederherstellen
Wenn der Master ausgefallen ist und ein neuer Master gewählt wurde, versucht ClusterControl nicht, den ausgefallenen Master wiederherzustellen. Wieso den? Dieser Server verfügt möglicherweise über Daten, die noch nicht repliziert wurden, und der Administrator müsste den Fehler untersuchen. Ok, Sie können ClusterControl immer noch so konfigurieren, dass die Daten auf dem ausgefallenen Master gelöscht und als Slave mit dem neuen Master verbunden werden - wenn Sie mit dem Verlust einiger Daten einverstanden sind. Aber standardmäßig lässt ClusterControl den ausgefallenen Master stehen, bis ihn jemand ansieht und entscheidet, ihn wieder in die Topologie einzuführen.
Sollten Sie also das Failover automatisieren? Dies hängt davon ab, wie Sie die Replikation konfiguriert haben. Zirkuläre Replikationskonfigurationen mit mehreren beschreibbaren Mastern oder komplexen Topologien sind wahrscheinlich keine guten Kandidaten für automatisches Failover. Wir würden uns beim Entwerfen einer Replikationslösung an die oben genannten Prinzipien halten.
Auf PostgreSQL
Bei der PostgreSQL-Streaming-Replikation verwendet ClusterControl ähnliche Prinzipien, um das Failover zu automatisieren. Für PostgreSQL unterstützt ClusterControl sowohl asynchrone als auch synchrone Replikationsmodelle zwischen dem Master und den Slaves. In beiden Fällen und im Fehlerfall wird der Slave mit den aktuellsten Daten zum neuen Master gewählt. Ausgefallene Master werden nicht automatisch wiederhergestellt/korrigiert, um dem Replikations-Setup wieder beizutreten.
Es werden einige Schutzmaßnahmen ergriffen, um sicherzustellen, dass der ausgefallene Master ausgefallen ist und ausgefallen bleibt, z. es wird aus dem Load-Balancing-Set im Proxy entfernt und es wird getötet, wenn z. der Benutzer würde es manuell neu starten. Dort ist es etwas schwieriger, Netzwerkaufspaltungen zwischen ClusterControl und dem Master zu erkennen, da die Slaves keine Informationen über den Status des Masters liefern, von dem sie replizieren. Daher ist ein Proxy vor dem Datenbank-Setup wichtig, da er einen weiteren Pfad zum Master bereitstellen kann.
Auf MongoDB
Die MongoDB-Replikation innerhalb eines Replikats über das Oplog ist der Binlog-Replikation sehr ähnlich. Wie kommt es also, dass MongoDB einen ausgefallenen Master automatisch wiederherstellt? Das Problem besteht immer noch, und MongoDB behebt das, indem es alle Änderungen rückgängig macht, die zum Zeitpunkt des Ausfalls nicht auf die Slaves repliziert wurden. Diese Daten werden entfernt und in einem „Rollback“-Ordner abgelegt, sodass es Sache des Administrators ist, sie wiederherzustellen.
Um mehr zu erfahren, schauen Sie sich ClusterControl an; und fühlen Sie sich frei, unten zu kommentieren oder Fragen zu stellen.



