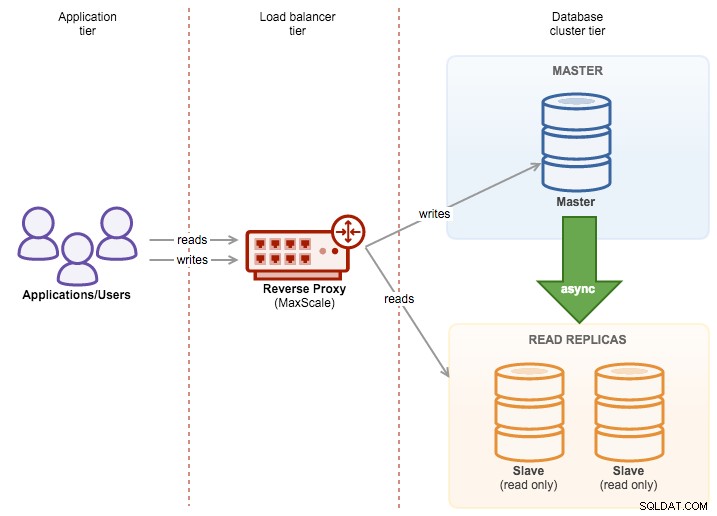
ClusterControl ist ein großartiges Tool zum Bereitstellen und Verwalten von Datenbank-Clustern – wenn Sie sich für MySQL interessieren, können Sie problemlos Cluster bereitstellen, die sowohl auf der traditionellen MySQL-Master-Slave-Replikation als auch auf Galera-Clustern oder MySQL-NDB-Clustern basieren. Um eine hohe Verfügbarkeit zu erreichen, reicht die Bereitstellung eines Clusters jedoch nicht aus. Knoten können (und werden höchstwahrscheinlich) ausfallen, und Ihr System muss in der Lage sein, sich an diese Änderungen anzupassen.
Diese Anpassung kann auf verschiedenen Ebenen erfolgen. Sie können eine Art Logik innerhalb der Anwendung implementieren – sie würde den Status von Cluster-Knoten überprüfen und den Datenverkehr zu denen leiten, die im gegebenen Moment erreichbar sind. Sie können auch eine Proxy-Schicht aufbauen, die Hochverfügbarkeit in Ihrem System implementiert. In diesem Blogbeitrag möchten wir Ihnen einige Tipps geben, wie Sie dies mit ClusterControl erreichen können.
Bereitstellen von HAProxy mit ClusterControl
HAProxy ist der Standard - einer der beliebtesten Proxys im Zusammenhang mit MySQL (aber natürlich nicht nur). ClusterControl unterstützt die Bereitstellung und Überwachung von HAProxy-Knoten. Es hilft auch, eine hohe Verfügbarkeit des Proxys selbst mit Keepalive zu implementieren.
Die Bereitstellung ist ziemlich einfach – Sie müssen die IP-Adresse eines Hosts auswählen oder eingeben, auf dem HAProxy installiert wird, den Port auswählen, die Lastausgleichsrichtlinie auswählen und entscheiden, ob ClusterControl das vorhandene Repository oder den neuesten Quellcode verwenden soll, um HAProxy bereitzustellen. Sie können auch auswählen, welche Backend-Knoten Sie in die Proxy-Konfiguration aufnehmen möchten und ob sie aktiv oder Backup sein sollen.
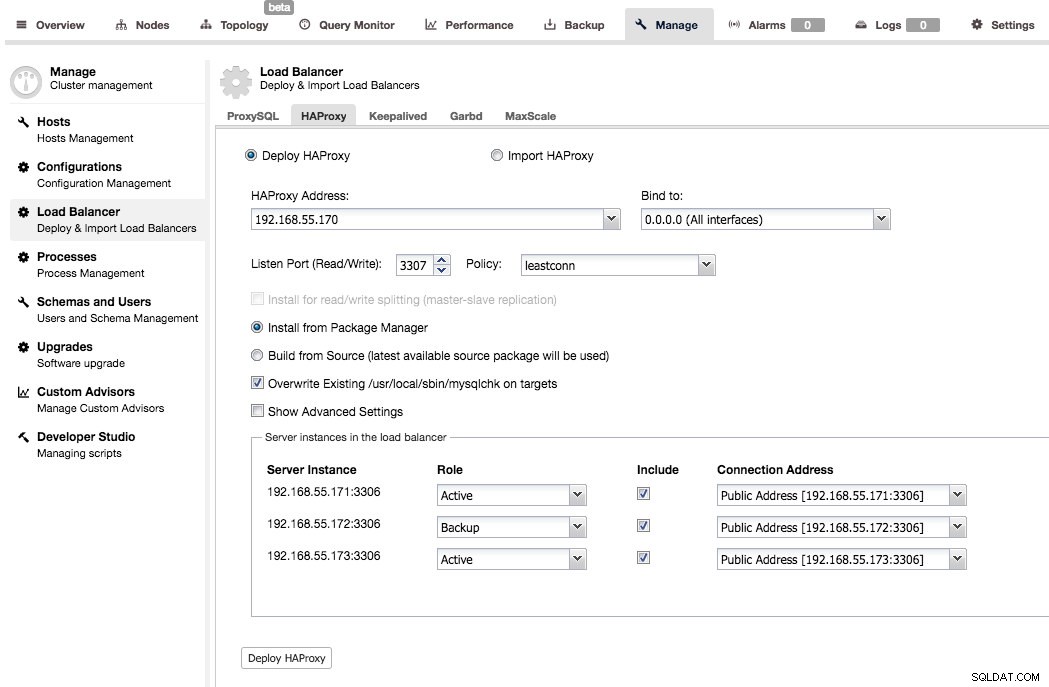
Standardmäßig funktioniert die von ClusterControl bereitgestellte HAProxy-Instanz auf MySQL Cluster (NDB), Galera Cluster, PostgreSQL-Streaming-Replikation und MySQL-Replikation. Für die Master-Slave-Replikation kann ClusterControl zwei Listener konfigurieren, einen für Read-Only und einen für Read-Write. Anwendungen müssen dann Lese- und Schreibvorgänge an die entsprechenden Ports senden. Für die Multi-Master-Replikation richtet ClusterControl den Standard-TCP-Lastenausgleich basierend auf dem Ausgleichsalgorithmus der kleinsten Verbindung ein (z. B. für Galera-Cluster, bei denen alle Knoten beschreibbar sind).
Keepalived wird verwendet, um der Proxy-Schicht Hochverfügbarkeit hinzuzufügen. Wenn Sie mindestens zwei HAProxy-Knoten in Ihrem System haben, können Sie Keepalived über die ClusterControl-Benutzeroberfläche installieren.
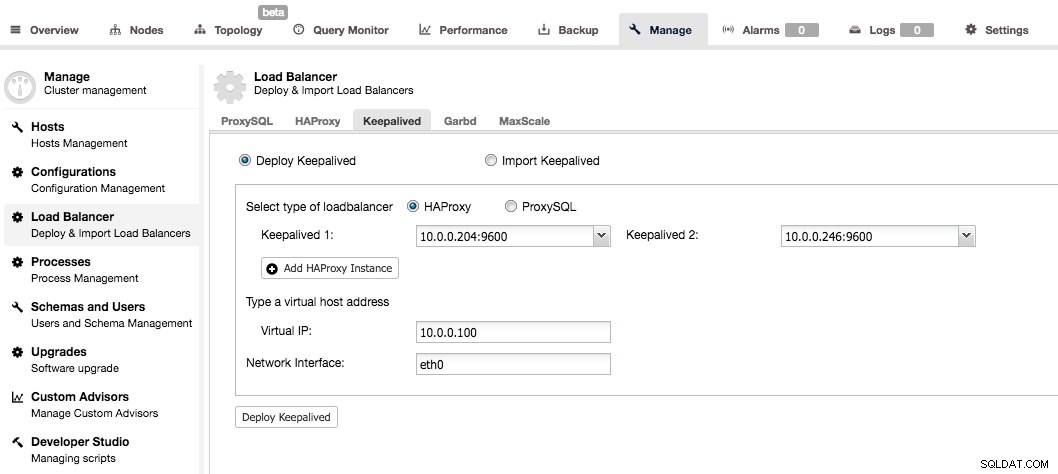
Sie müssen zwei HAProxy-Knoten auswählen und sie werden als Aktiv-Standby-Paar konfiguriert. Dem aktiven Server wird eine virtuelle IP zugewiesen, die bei einem Ausfall dem Standby-Proxy neu zugewiesen wird. Auf diese Weise können Sie sich einfach mit dem VIP verbinden und alle Ihre Anfragen werden an den derzeit aktiven und funktionierenden HAProxy-Knoten weitergeleitet.
Weitere Details zur Konfiguration der Interna finden Sie in unserem HAProxy-Tutorial.
Bereitstellen von ProxySQL mit ClusterControl
Während HAProxy ein absolut solider Proxy und eine sehr beliebte Wahl ist, fehlt es ihm an Datenbankbewusstsein, z. B. Read-Write-Split. Die einzige Möglichkeit, dies in HAProxy zu tun, besteht darin, zwei Backends zu erstellen und auf zwei Ports zu lauschen - einen für Lesevorgänge und einen für Schreibvorgänge. Dies ist normalerweise in Ordnung, erfordert jedoch, dass Sie Änderungen in Ihrer Anwendung implementieren. Die Anwendung muss verstehen, was ein Lese- und was ein Schreibvorgang ist, und diese Abfragen dann an den richtigen Port weiterleiten. Es wäre viel einfacher, sich nur mit einem einzelnen Port zu verbinden und den Proxy entscheiden zu lassen, was als nächstes zu tun ist - das kann HAProxy nicht, da es nur Pakete weiterleitet - es wird keine Paketprüfung durchgeführt und vor allem hat es keine Verständnis des MySQL-Protokolls.
ProxySQL löst dieses Problem - es spricht das MySQL-Protokoll und kann (unter anderem) eine Lese-Schreib-Aufteilung durch seine leistungsstarken Abfrageregeln durchführen und den eingehenden MySQL-Verkehr nach verschiedenen Kriterien weiterleiten. Die Installation von ProxySQL von ClusterControl ist einfach – gehen Sie zum Abschnitt Verwalten -> Load Balancer und füllen Sie die Registerkarte „ProxySQL bereitstellen“ mit den erforderlichen Daten aus.
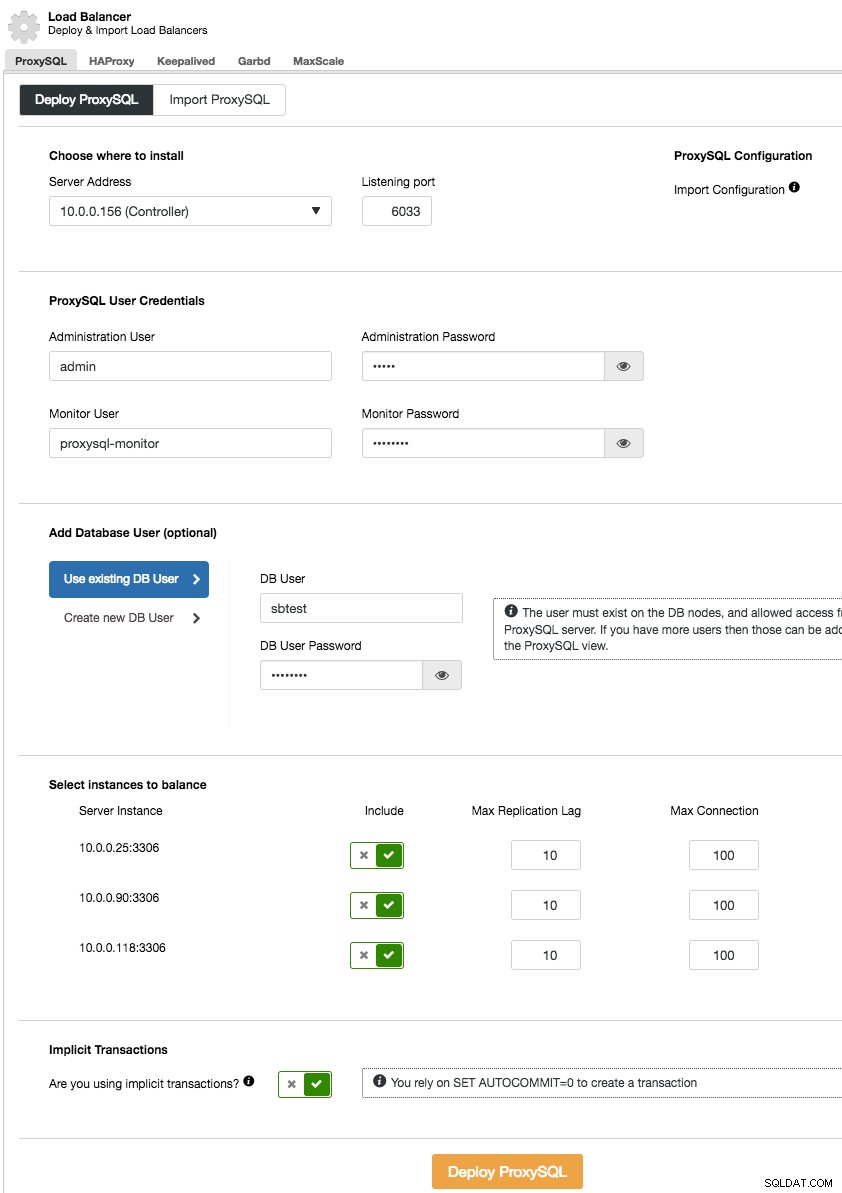
Kurz gesagt, wir müssen auswählen, wo ProxySQL installiert werden soll, welchen Verwaltungsbenutzer und welches Passwort es haben soll, welchen Überwachungsbenutzer es verwenden soll, um eine Verbindung zu den MySQL-Back-Ends herzustellen und ihren Status zu überprüfen und den Status zu überwachen. Von ClusterControl aus können Sie entweder einen neuen Benutzer erstellen, der von der Anwendung verwendet werden soll – Sie können über seinen Namen, sein Passwort, den Zugriff auf die Datenbanken und die MySQL-Berechtigungen dieses Benutzers entscheiden. Dieser Benutzer wird sowohl auf MySQL- als auch auf ProxySQL-Seite erstellt. Die zweite Option, die besser für bestehende Infrastrukturen geeignet ist, besteht darin, die vorhandenen Datenbankbenutzer zu verwenden. Sie müssen Benutzername und Passwort übergeben, und ein solcher Benutzer wird nur auf ProxySQL erstellt.
Abschließend müssen Sie eine Frage beantworten:Verwenden Sie implizite Transaktionen? Darunter verstehen wir Transaktionen, die durch Ausführen von SET autocommit=0 gestartet wurden; Wenn Sie es verwenden, konfiguriert ClusterControl ProxySQL so, dass der gesamte Datenverkehr an den Master gesendet wird. Dies ist erforderlich, um sicherzustellen, dass ProxySQL Transaktionen in ProxySQL 1.3.x und früher korrekt verarbeitet. Wenn Sie SET autocommit=0 nicht verwenden, um eine neue Transaktion zu erstellen, konfiguriert ClusterControl die Lese-/Schreibaufteilung.
ProxySQL kann, wie jeder Proxy, zu einem Single Point of Failure werden und muss redundant gemacht werden, um eine hohe Verfügbarkeit zu erreichen. Es gibt ein paar Methoden, um das zu tun. Eine davon ist die Kollokation von ProxySQL auf den Webknoten. Die Idee dabei ist, dass der ProxySQL-Prozess die meiste Zeit gut funktioniert und der Grund für seine Nichtverfügbarkeit darin besteht, dass der gesamte Knoten ausgefallen ist. Wenn in einem solchen Fall ProxySQL mit dem Webknoten zusammengelegt wird, ist nicht viel Schaden angerichtet worden, da dieser bestimmte Webknoten auch nicht verfügbar sein wird.
Eine andere Methode besteht darin, Keepalived auf ähnliche Weise zu verwenden, wie wir es im Fall von HAProxy getan haben.
Weitere Einzelheiten zur Konfiguration der Interna finden Sie in unserem ProxySQL-Tutorial.



