Backups – eines der wichtigsten Dinge, um die man sich bei der Verwaltung von Datenbanken kümmern muss. Es wird gesagt, dass es zwei Arten von Menschen gibt – diejenigen, die ihre Daten sichern, und diejenigen, die ihre Daten sichern werden. In diesem Blog-Beitrag diskutieren wir bewährte Vorgehensweisen rund um Backups und zeigen Ihnen, wie Sie mit ClusterControl ein zuverlässiges Backup-System aufbauen können.
Wir werden sehen, wie ClusterControl Ihnen ein zentralisiertes Backup-Management für MySQL, MariaDB, MongoDB und PostgreSQL bietet. Es bietet Ihnen Hot-Backups großer Datensätze, Point-in-Time-Recovery, Verschlüsselung von Daten im Ruhezustand und während der Übertragung, Datenintegrität durch automatische Wiederherstellungsüberprüfung, Cloud-Backups (AWS, Google und Azure) für Disaster Recovery, Aufbewahrungsrichtlinien zur Gewährleistung der Compliance , und automatisierte Benachrichtigungen und Berichte.
Sicherungstypen
Es gibt zwei Haupttypen von Backups, die wir in ClusterControl durchführen können:
- Logisches Backup – Backup von Daten wird in einem für Menschen lesbaren Format wie SQL gespeichert
- Physisches Backup - Backup enthält binäre Daten
Beide ergänzen sich gegenseitig – die logische Sicherung ermöglicht es Ihnen, (mehr oder weniger einfach) bis zu einer einzelnen Datenzeile abzurufen. Physische Backups würden dazu mehr Zeit in Anspruch nehmen, aber auf der anderen Seite ermöglichen sie Ihnen, einen ganzen Host sehr schnell wiederherzustellen (etwas, das Stunden oder sogar Tage dauern kann, wenn Sie ein logisches Backup verwenden).
ClusterControl unterstützt Backups für MySQL/MariaDB/Percona Server, PostgreSQL und MongoDB.
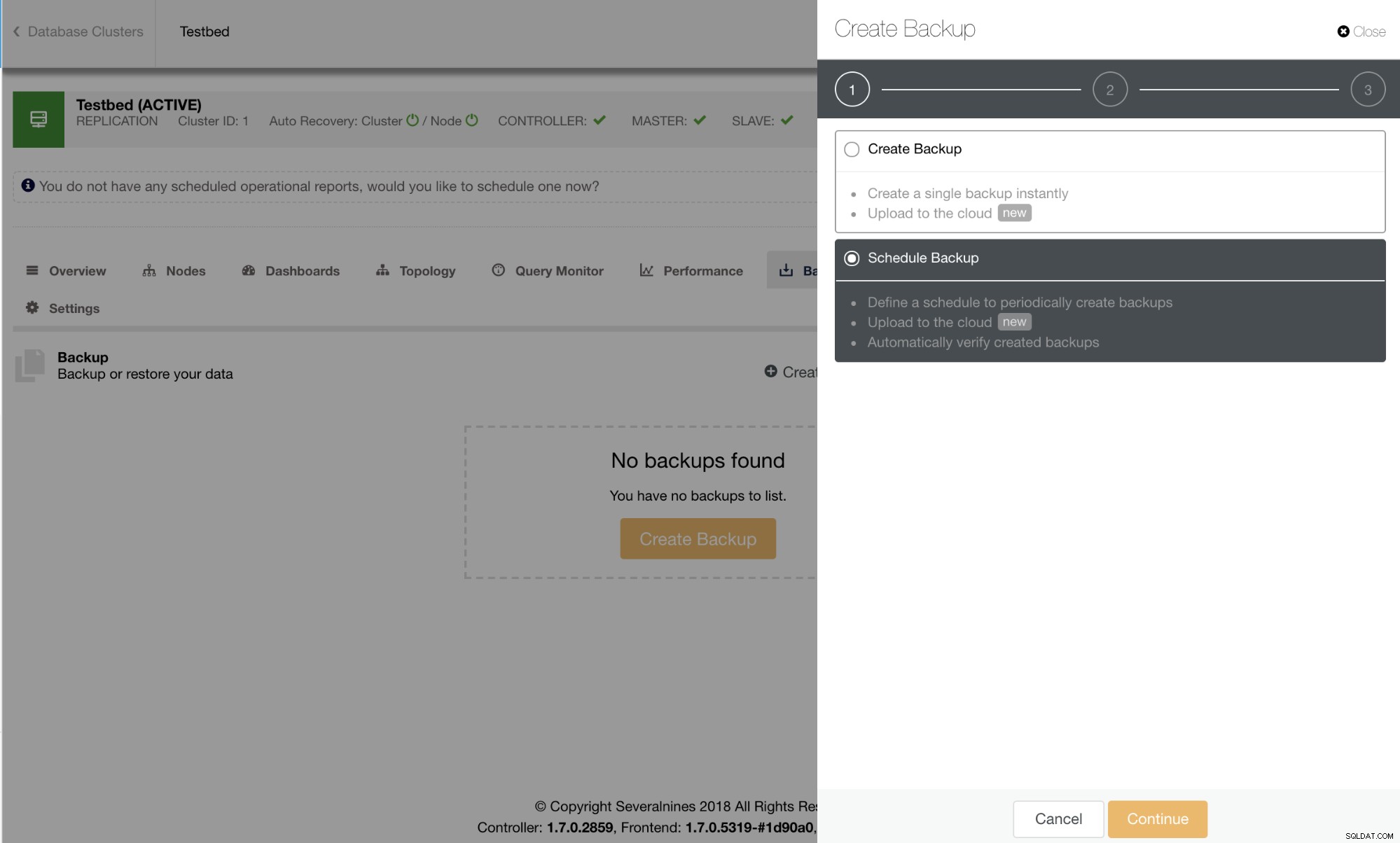
Sicherung planen
Das Starten eines Backups in ClusterControl erfolgt einfach und effizient über einen Assistenten. Das Planen eines Backups bietet Benutzerfreundlichkeit und Zugang zu anderen Funktionen wie Verschlüsselung, automatischem Test/Verifizierung des Backups oder Cloud-Archivierung.
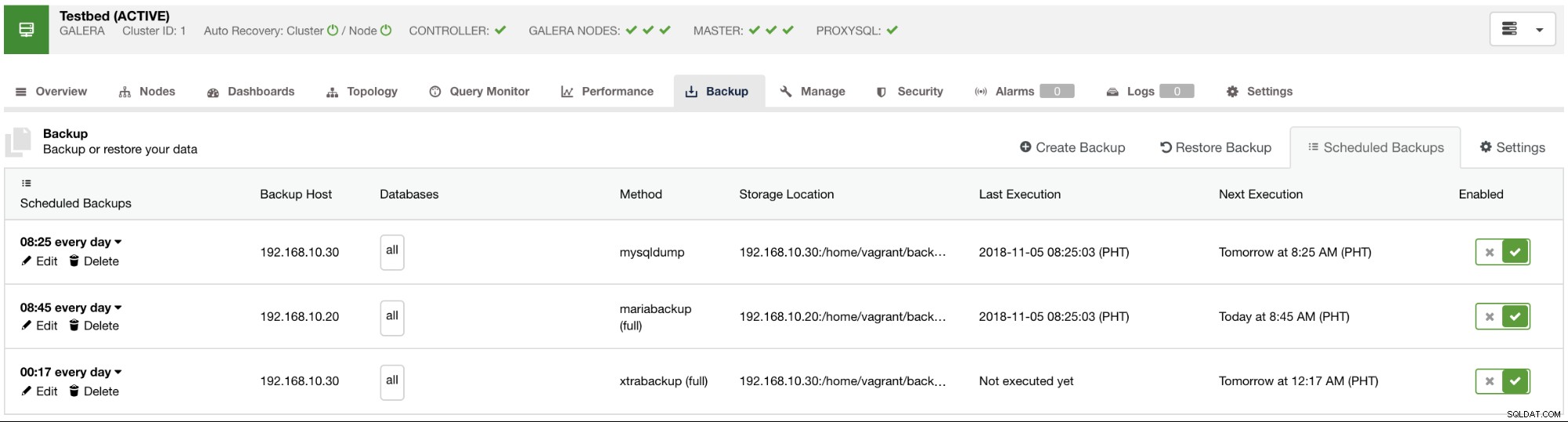
Verfügbare geplante Sicherungen werden auf der Registerkarte „Geplante Sicherungen“ aufgelistet, wie in der Abbildung unten zu sehen:
Als bewährtes Verfahren zum Planen eines Backups müssen Sie bereits über Ihre definierte Backup-Aufbewahrung verfügen, und ein tägliches Backup wird empfohlen. Es hängt jedoch auch von den Daten ab, die Sie benötigen, dem zu erwartenden Datenverkehr und der Verfügbarkeit der Daten, wann immer Sie sie benötigen, insbesondere während der Datenwiederherstellung, bei der Daten versehentlich gelöscht wurden, oder bei einer Festplattenbeschädigung - die unvermeidlich sind. Es gibt auch Situationen, in denen Datenverluste reproduzierbar sind oder manuell dupliziert werden können, wie z. B. Berichterstellung, Miniaturansichten oder zwischengespeicherte Daten. Die Frage hängt jedoch davon ab, wie schnell Sie sie benötigen, wenn eine Katastrophe eintritt. Wenn möglich, sollten Sie sowohl mysqldump- als auch xtrabackup-Backups täglich für MySQL erstellen, um die logische und physische Backup-Verfügbarkeit zu nutzen. Um noch mehr Basen abzudecken, können Sie mehrere inkrementelle xtrabackup-Läufe pro Tag planen. Dies könnte etwas Speicherplatz, Festplatten-I/O oder sogar CPU-I/O sparen, als eine vollständige Sicherung durchzuführen.
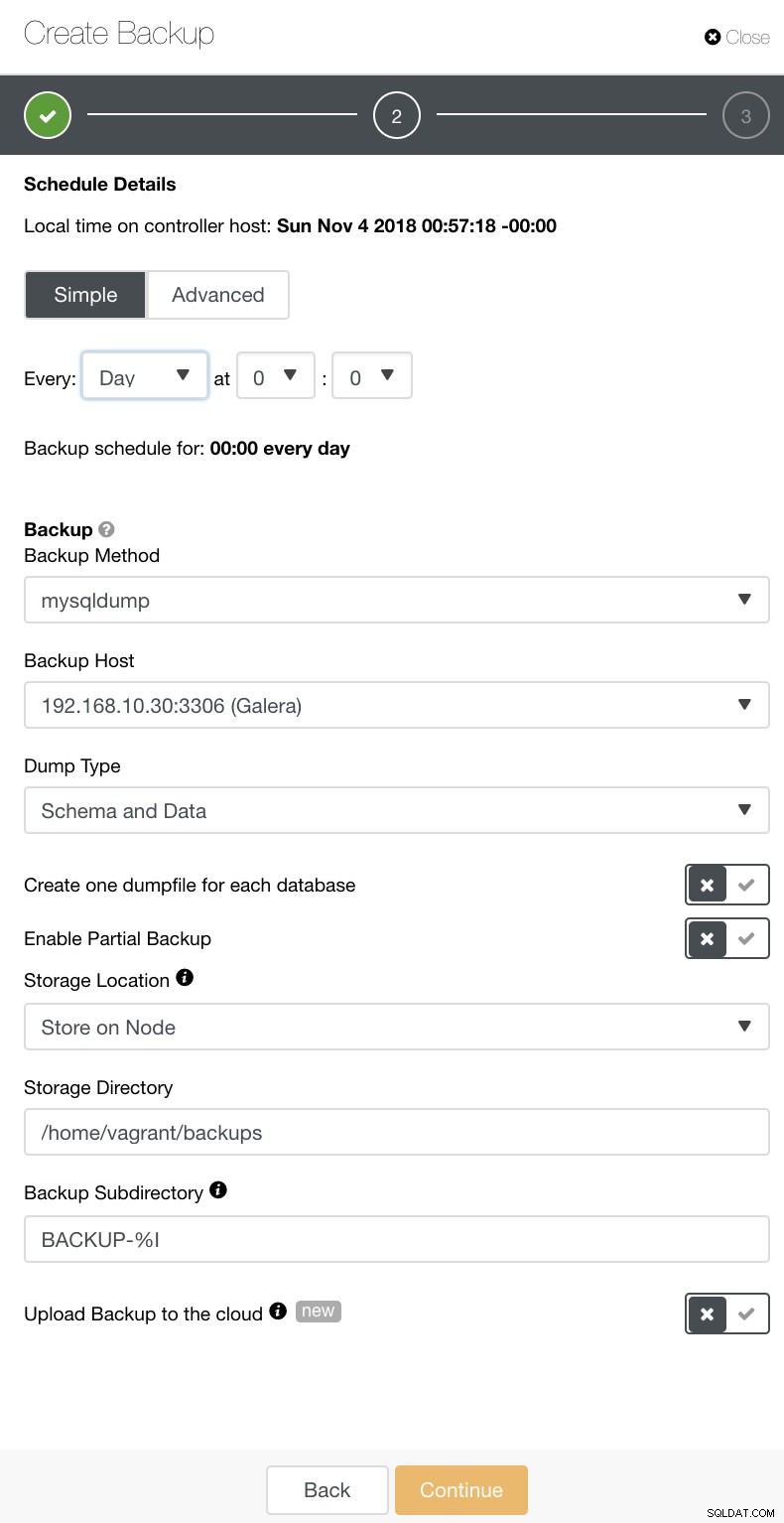
In ClusterControl können Sie diese verschiedenen Arten von Backups einfach planen. Es gibt ein paar Einstellungen zu entscheiden. Sie können eine Sicherung auf dem Controller oder lokal auf dem Datenbankknoten speichern, auf dem die Sicherung erstellt wird. Sie müssen entscheiden, an welchem Ort die Sicherung gespeichert werden soll und welche Datenbanken Sie sichern möchten – alle Datensätze oder separate Schemas? Siehe folgendes Bild:
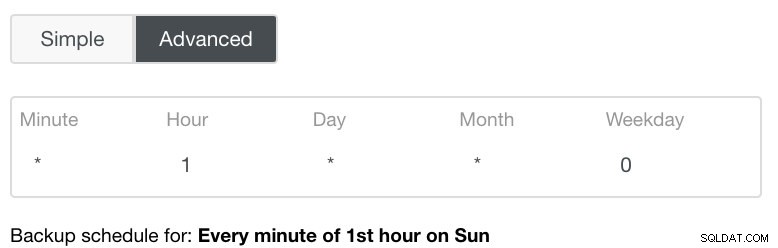
Die erweiterte Einstellung würde eine cron-ähnliche Konfiguration für mehr Granularität nutzen. Siehe Bild unten:
Wenn ein Fehler auftritt, behandelt ClusterControl diese Probleme effizient und erstellt Protokolle für die weitere Diagnose des Backup-Fehlers.
Je nach gewähltem Sicherungstyp müssen separate Einstellungen konfiguriert werden. Für Xtrabackup und Galera Cluster haben Sie möglicherweise die Möglichkeit, auszuwählen, welche Einstellungen Ihr physisches Backup beim Ausführen anwenden würde. Siehe unten:
- Komprimierung verwenden
- Komprimierungsstufe
- Knoten während der Sicherung desynchronisieren
- Sicherungssperren
- DDL pro Tabelle sperren
- Xtrabackup-Parallelkopie-Threads
- Netzwerk-Streaming-Drosselungsrate (MB/s)
- Verwenden Sie PIGZ für paralleles gzip
- Verschlüsselung aktivieren
- Aufbewahrung
In der Abbildung unten sehen Sie, wie Sie die Optionen entsprechend markieren können, und es gibt QuickInfo-Symbole, die weitere Informationen zu den Optionen liefern, die Sie für Ihre Backup-Richtlinie nutzen möchten.
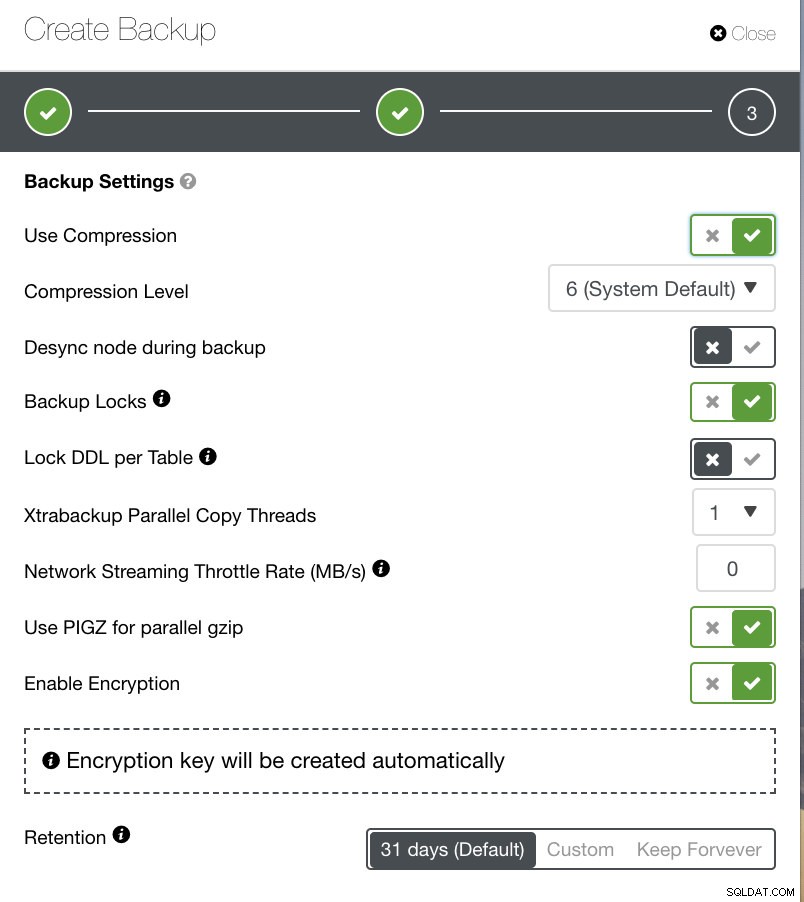
Abhängig von Ihrer Sicherungsrichtlinie kann ClusterControl gemäß den Best Practices zur Aktualisierung Ihrer verfügbaren Sicherungen angepasst werden. Beim Definieren Ihrer Sicherungsrichtlinie wird davon ausgegangen, dass Sie Ihr erforderliches Setup von Hardware über Software bis hin zu Cloud, Haltbarkeit, Hochverfügbarkeit oder Skalierbarkeit zur Verfügung haben müssen.
Wenn Sie Backups auf einem Galera-Cluster erstellen, empfiehlt es sich, den Galera-Knoten wsrep_desync=ON zu setzen, während das Backup läuft. Dadurch wird der Knoten von der Teilnahme an der Flusskontrolle ausgeschlossen und der gesamte Cluster vor Replikationsverzögerungen geschützt, insbesondere wenn Ihre zu sichernden Daten umfangreich sind. Bitte beachten Sie bei ClusterControl, dass dadurch auch Ihr Ziel-Backup-Node aus dem Load-Balancing-Set entfernt werden kann. Dies gilt insbesondere, wenn Sie HAProxy-, ProxySQL- oder MaxScale-Proxys verwenden. Wenn Sie den Alarmmanager eingerichtet haben, falls der Knoten desynchronisiert wird, können Sie ihn während des Zeitraums deaktivieren, in dem die Sicherung ausgelöst wurde.
Eine weitere beliebte Möglichkeit, die Auswirkungen eines Backups auf einen Galera-Cluster oder einen Replikations-Master zu minimieren, besteht darin, einen Replikations-Slave einzusetzen und ihn dann als Quelle für Backups zu verwenden – auf diese Weise wird Galera Cluster zu keinem Zeitpunkt als Backup auf dem Galera-Cluster beeinträchtigt Slave ist vom Cluster entkoppelt.
Mit ClusterControl können Sie einen solchen Slave mit nur wenigen Klicks bereitstellen. Siehe Bild unten:
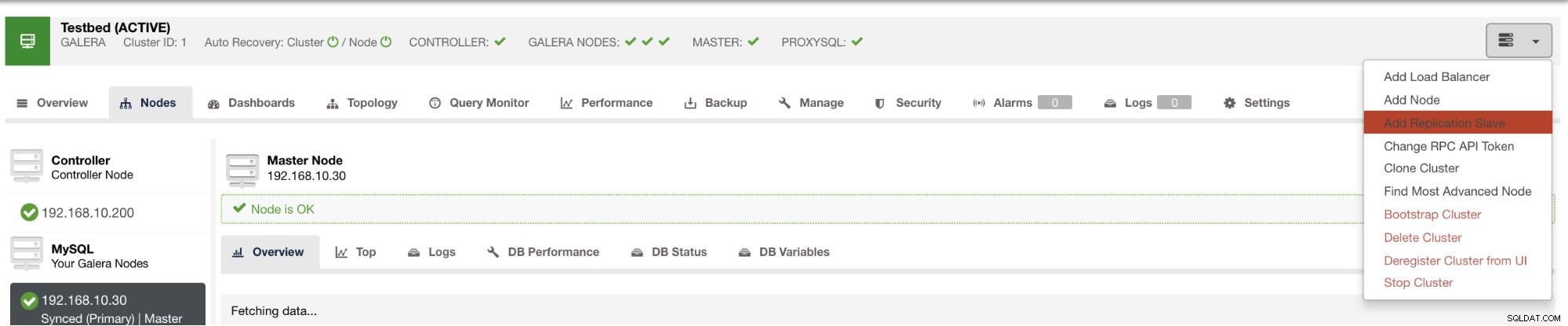
und sobald Sie auf diese Schaltfläche klicken, können Sie auswählen, auf welchen Knoten ein Slave eingerichtet werden soll. Stellen Sie sicher, dass die binäre Protokollierung der Knoten aktiviert ist. Das Aktivieren des Binärprotokolls kann auch über ClusterControl erfolgen, was die Verwaltung Ihres gewünschten Masters vereinfacht. Siehe Bild unten:
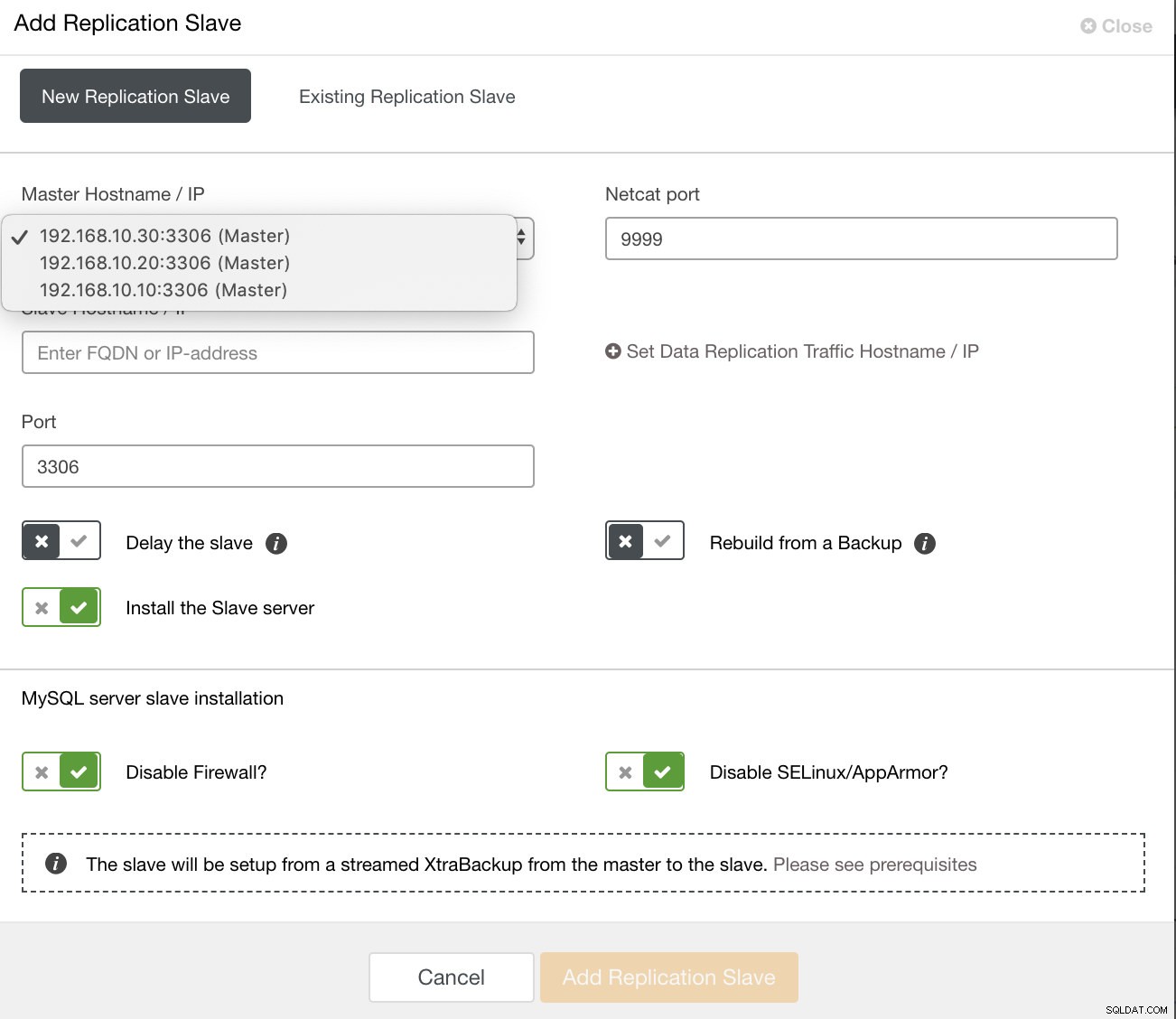
und Sie können auch einen vorhandenen Replikations-Slave einrichten,
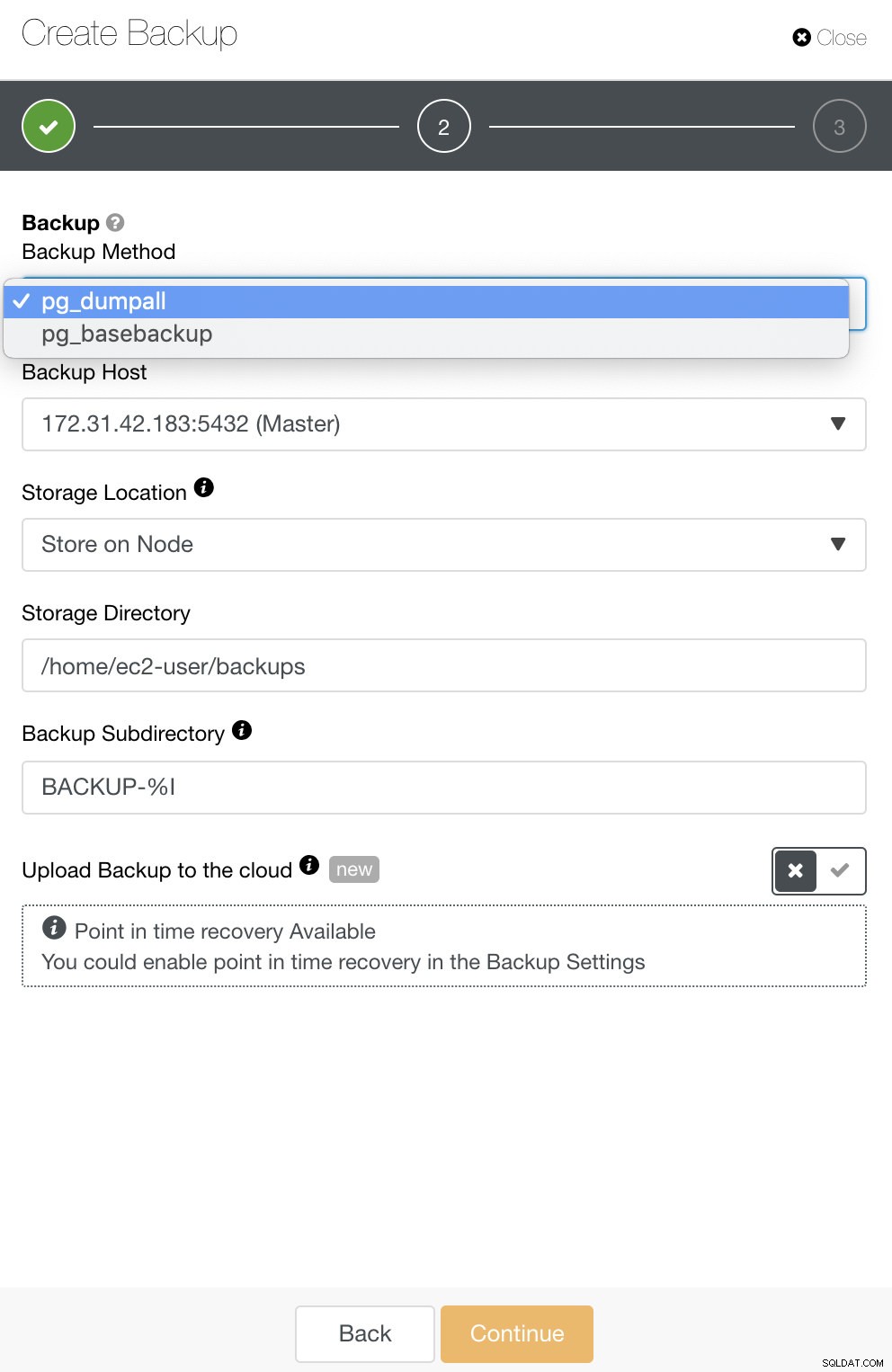
Für PostgreSQL haben Sie die Möglichkeit, entweder logische oder physische Sicherungen zu sichern. In ClusterControl können Sie Ihre PostgreSQL-Sicherungen nutzen, indem Sie pg_dump oder pg_basebackup auswählen. pg_basebackup funktioniert nicht für ältere Versionen als 9.3.
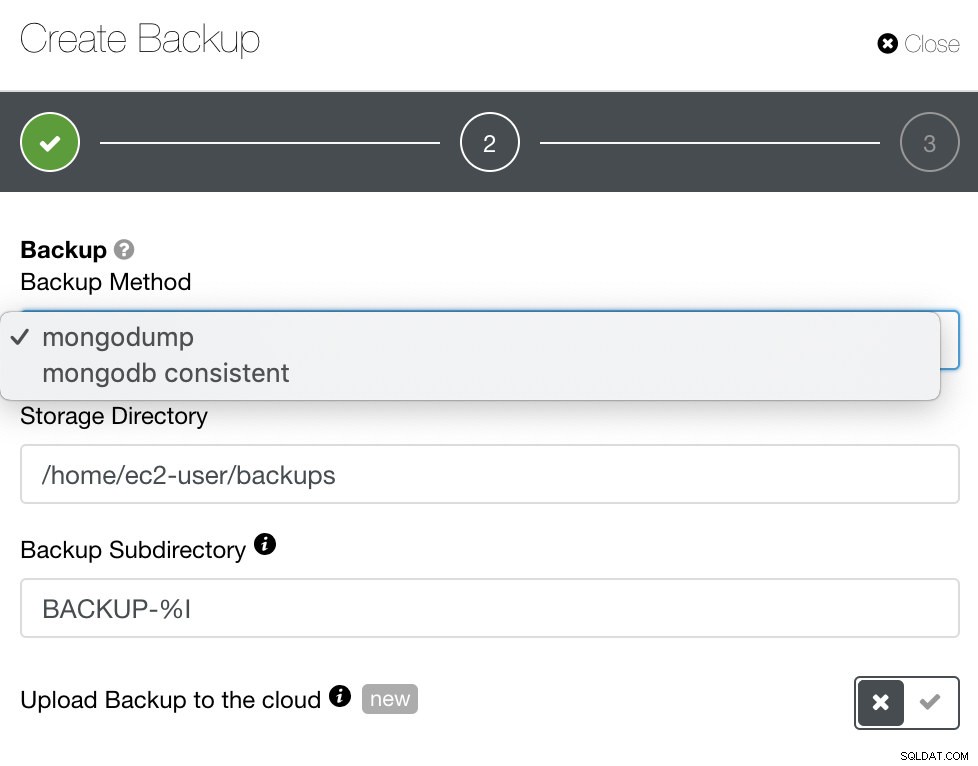
Für MongoDB bietet ClusterControl Mongodump oder Mongodb Consistent an. Möglicherweise müssen Sie beachten, dass mongodb konsistent RHEL 7 nicht unterstützt, aber Sie können es möglicherweise manuell installieren.
Standardmäßig listet ClusterControl einen Bericht für alle Backups auf, die durchgeführt wurden, erfolgreiche oder fehlgeschlagene. Siehe unten:
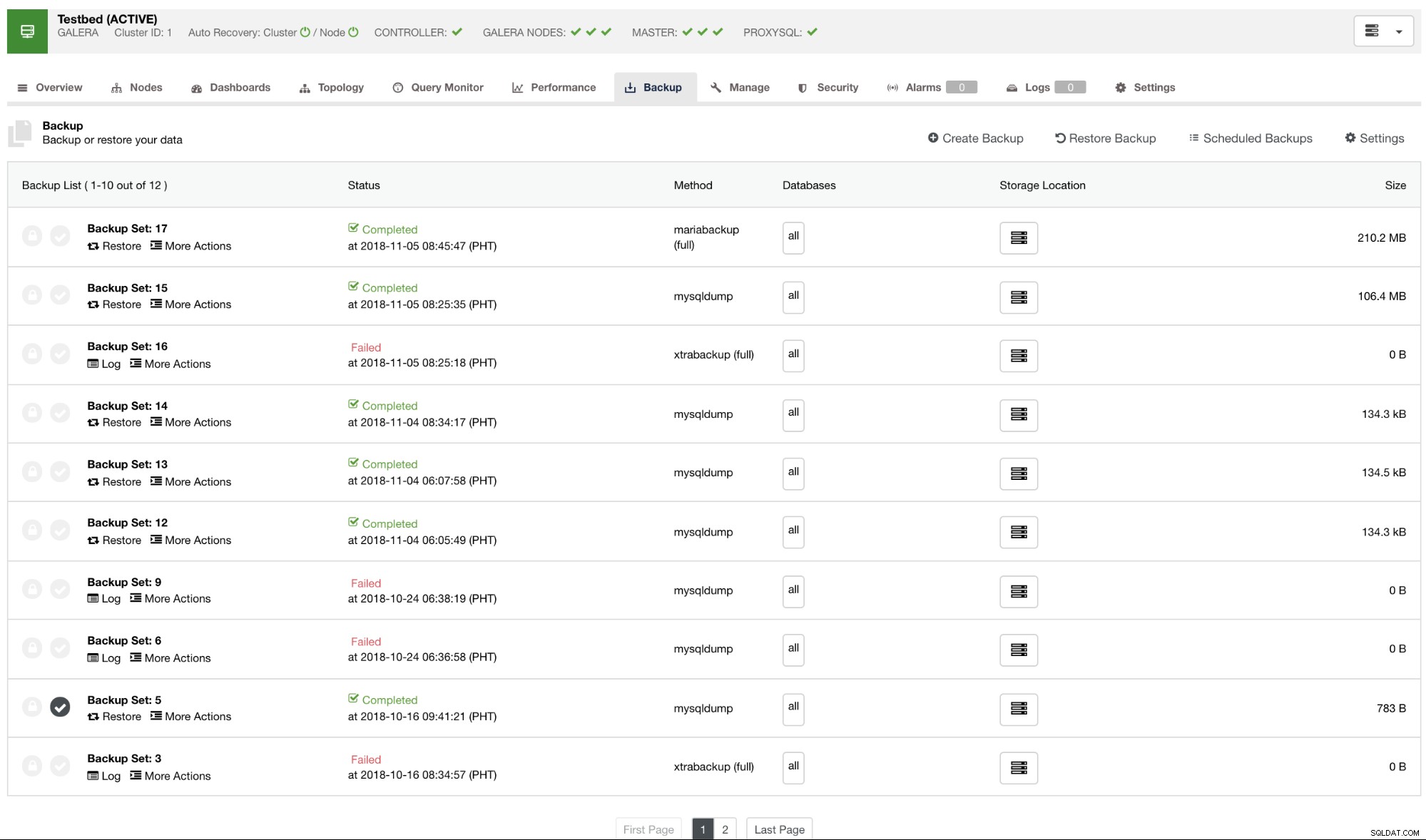
Sie können die Liste der Sicherungsberichte überprüfen, die mit ClusterControl erstellt oder geplant wurden. Innerhalb der Liste können Sie die Protokolle zur weiteren Untersuchung und Diagnose anzeigen. Zum Beispiel, ob die Sicherung gemäß Ihrer gewünschten Sicherungsrichtlinie korrekt abgeschlossen wurde, ob Komprimierung und Verschlüsselung richtig eingestellt sind oder ob die gewünschte Sicherungsdatengröße korrekt ist. Dies ist eine gute Möglichkeit, eine schnelle Plausibilitätsprüfung durchzuführen – wenn Ihr Datensatz etwa 1 GB groß ist, kann eine vollständige Sicherung auf keinen Fall nur 100 KB groß sein – irgendwann muss etwas schief gelaufen sein.
Notfallwiederherstellung
Das Speichern von Backups innerhalb des Clusters (entweder direkt auf einem Datenbankknoten oder auf dem ClusterControl-Host) ist praktisch, wenn Sie Ihre Daten schnell wiederherstellen möchten:Alle Backup-Dateien sind vorhanden und können sofort dekomprimiert und wiederhergestellt werden. Wenn es um Disaster Recovery (DR) geht, ist dies möglicherweise nicht die beste Option. Es können verschiedene Probleme auftreten – Server können abstürzen, das Netzwerk funktioniert möglicherweise nicht zuverlässig, sogar ganze Rechenzentren sind aufgrund irgendeiner Art von Ausfall möglicherweise nicht zugänglich. Dies kann vorkommen, unabhängig davon, ob Sie mit einem kleineren Dienstanbieter mit einem einzigen Rechenzentrum oder einem globalen Anbieter wie Amazon Web Services zusammenarbeiten. Es ist daher nicht sicher, alle Ihre Eier in einem einzigen Korb aufzubewahren – Sie sollten sicherstellen, dass Sie eine Kopie Ihres Backups an einem externen Ort aufbewahren. ClusterControl unterstützt Amazon S3, Google Storage und Azure Cloud Storage .
Für diejenigen, die ihre eigenen DR-Richtlinien implementieren möchten, werden ClusterControl-Backups in einem schön strukturierten Verzeichnis gespeichert. Sie haben auch die Möglichkeit, Ihr Backup in die Cloud hochzuladen. Siehe Bild unten:
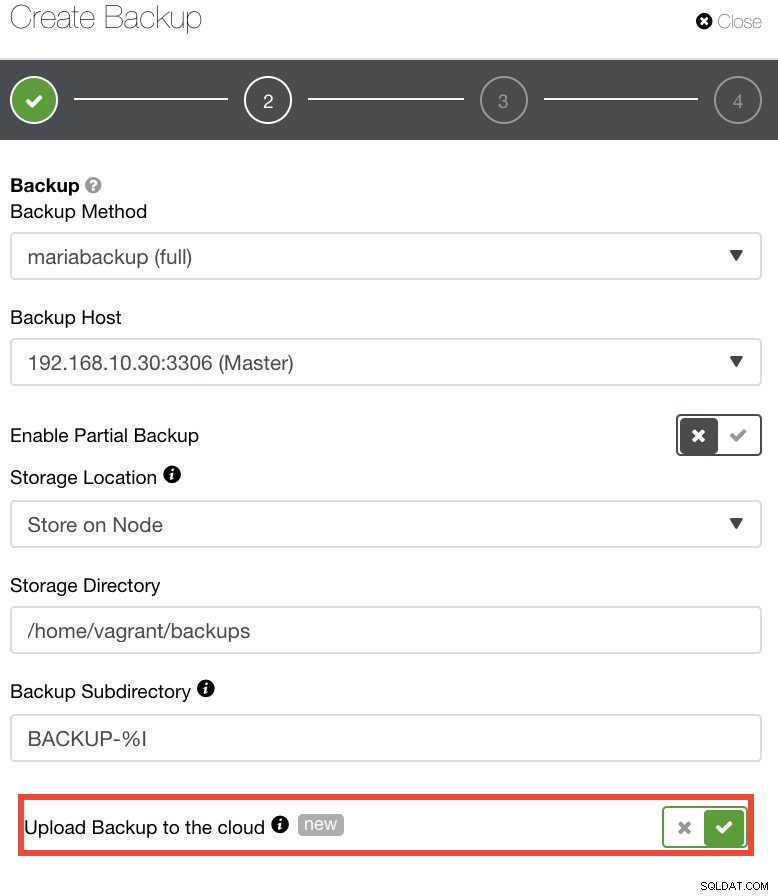
Sie können Amazon Web Services, Google Cloud und Microsoft Azure auswählen und hochladen. Siehe Bild unten:
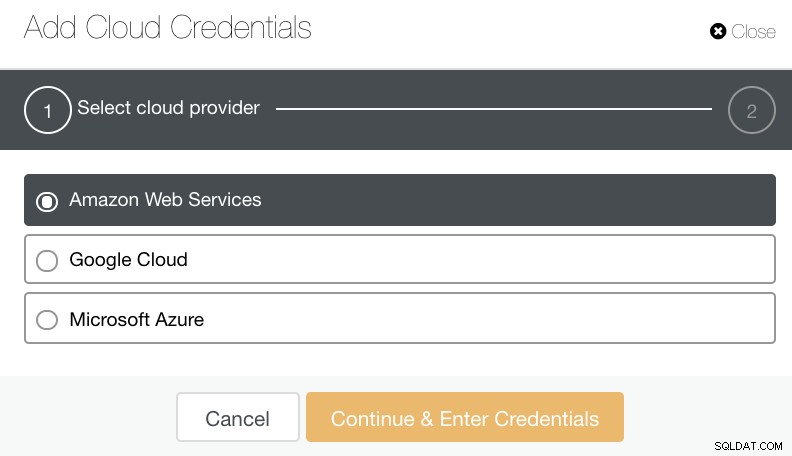
Stellen Sie als bewährte Methode beim Archivieren Ihrer Datenbanksicherungen sicher, dass Ihr Ziel-Cloud-Ziel auf derselben Region wie Ihre Datenbankserver basiert oder zumindest auf der nächstgelegenen. Stellen Sie sicher, dass es hohe Verfügbarkeit, Langlebigkeit und Skalierbarkeit bietet; da Sie überlegen müssen, wie oft und wie schnell Sie Ihre Daten benötigen.
Zusätzlich zum Erstellen eines logischen oder physischen Backups für Ihr DR kann das Erstellen eines vollständigen Snapshots Ihrer Daten (z. B. mithilfe von LVM-Snapshots, Amazon EBS-Snapshots oder Volume-Snapshots bei Verwendung des Veritas-Dateisystems) auf dem jeweiligen Knoten die Backup-Wiederherstellung verbessern. Sie können WAL (für Postgres) auch für Ihre Point-In-Time-Recovery (PITR) oder Ihre MySQL-Binärprotokolle für Ihre PITR verwenden. Daher müssen Sie bedenken, dass Sie ggf. eine eigene Archivierung für Ihr PITR erstellen müssen. Es ist also völlig in Ordnung, Ihre eigenen Skripts zu erstellen und bereitzustellen und DR genau nach Ihren Anforderungen zu handhaben.
Eine weitere großartige Möglichkeit zur Implementierung einer Notfallwiederherstellungsrichtlinie ist die Verwendung eines asynchronen Replikations-Slaves – etwas, das wir bereits in diesem Blogbeitrag erwähnt haben. Sie können einen solchen asynchronen Slave an einem entfernten Standort bereitstellen, vielleicht in einem anderen Rechenzentrum, und ihn dann verwenden, um Backups zu erstellen und sie lokal auf diesem Slave zu speichern. Natürlich möchten Sie ein lokales Backup Ihres Clusters erstellen, um es lokal verfügbar zu haben, wenn Sie den Cluster wiederherstellen müssen. Das Verschieben von Daten zwischen Rechenzentren kann lange dauern, sodass Sie Zeit sparen können, wenn Sie lokal verfügbare Sicherungsdateien haben. Falls Sie den Zugriff auf Ihren Hauptproduktionscluster verlieren, haben Sie möglicherweise immer noch Zugriff auf den Slave. Dieses Setup ist sehr flexibel – erstens haben Sie einen laufenden MySQL-Host mit Ihren Produktionsdaten, sodass es nicht zu schwierig sein sollte, Ihre vollständige Anwendung auf der DR-Site bereitzustellen. Außerdem verfügen Sie über Backups Ihrer Produktionsdaten, die Sie zum Aufskalieren Ihrer DR-Umgebung verwenden können.
Zu guter Letzt und am wichtigsten ist, dass ein nicht getestetes Backup ein ungeprüftes Backup, auch bekannt als Schroedinger Backup, bleibt. Um sicherzustellen, dass Sie über eine funktionierende Sicherung verfügen, müssen Sie einen Wiederherstellungstest durchführen. ClusterControl bietet eine Möglichkeit, Ihr Backup automatisch zu überprüfen und zu testen.
Wir hoffen, dass Ihnen dies genügend Informationen liefert, um ein sicheres und zuverlässiges Backup-Verfahren für Ihre Open-Source-Datenbanken aufzubauen.



