Bis jetzt haben wir die Hadoop-Einführung behandelt und Hadoop HDFS im Detail. In diesem Tutorial stellen wir Ihnen eine detaillierte Beschreibung von Hadoop Reducer zur Verfügung.
Hier wird erläutert, was Reducer in MapReduce ist, wie Reducer in Hadoop MapReduce funktioniert, verschiedene Phasen von Hadoop Reducer, wie wir die Anzahl von Reducer in Hadoop MapReduce ändern können.
Was ist Hadoop Reducer?
Reduzierer in Hadoop MapReduce reduziert einen Satz von Zwischenwerten, die einen Schlüssel teilen, auf einen kleineren Satz von Werten.
Im MapReduce-Auftragsausführungsablauf nimmt Reducer einen Satz eines Zwischen-Schlüssel-Wert-Paares vom Mapper erzeugt als Eingang. Dann aggregiert, filtert und kombiniert Reducer Schlüssel-Wert-Paare, und dies erfordert ein breites Spektrum an Verarbeitung.
Eine Eins-Eins-Zuordnung findet zwischen Schlüsseln und Reduzierern bei der Ausführung von MapReduce-Aufträgen statt. Sie laufen parallel, da sie unabhängig voneinander sind. Der Benutzer entscheidet über die Anzahl der Reducer in MapReduce.
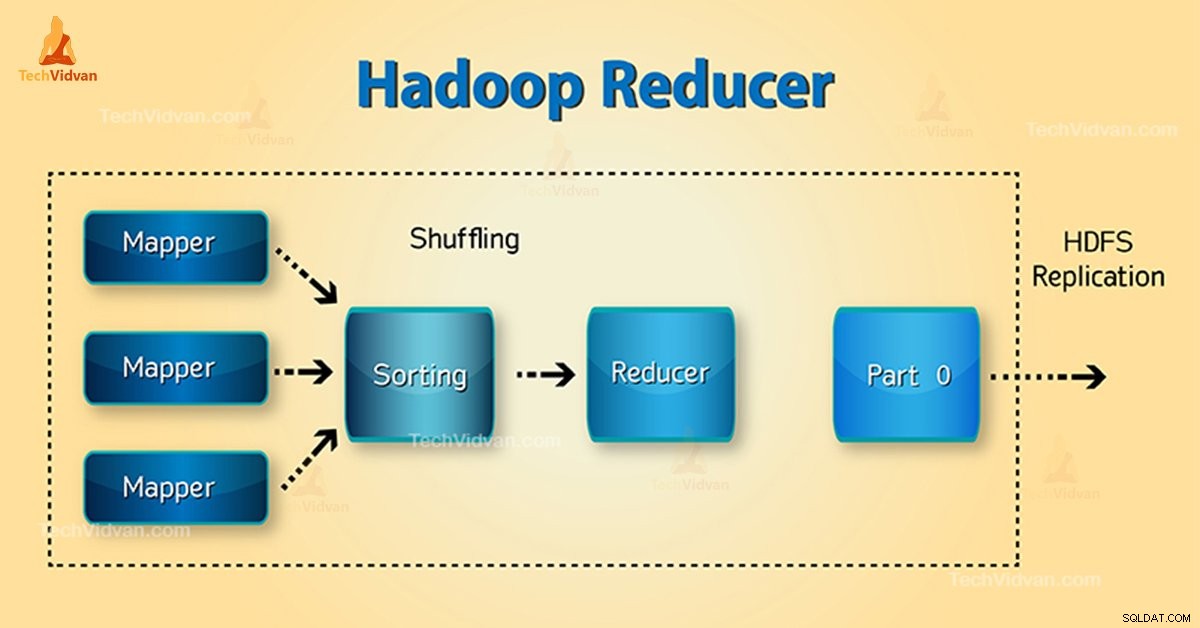
Phasen von Hadoop Reducer
Drei Phasen von Reducer sind wie folgt:
1. Shuffle-Phase
Dies ist die Phase, in der die sortierte Ausgabe des Mappers die Eingabe für den Reduzierer ist. Das Framework holt sich in dieser Phase mit Hilfe von HTTP die relevante Partition der Ausgabe aller Mapper. Phase sortieren
2. Sortierphase
Dies ist die Phase, in der die Eingaben von verschiedenen Mappern erneut basierend auf den ähnlichen Schlüsseln in verschiedenen Mappern sortiert werden.
Shuffle und Sort treten gleichzeitig auf.
3. Phase reduzieren
Diese Phase tritt nach dem Mischen und Sortieren auf. Die Aufgabe „Reduzieren“ aggregiert die Schlüssel-Wert-Paare. Mit OutputCollector.collect() -Eigenschaft wird die Ausgabe der Reduce-Aufgabe in das Dateisystem geschrieben. Reducer-Ausgang ist nicht sortiert.
Anzahl der Reducer in Hadoop MapReduce
Der Benutzer legt die Anzahl der Reduzierungen mit Hilfe von Job.setNumreduceTasks(int) fest Eigentum. Also die richtige Anzahl von Reduzierstücken nach der Formel:
0,95 oder 1,75 multipliziert mit (
Mit 0,95 starten also alle Reduzierer sofort. Beginnen Sie dann mit der Übertragung der Kartenausgaben, sobald die Karten fertig sind.
Faster node beendet die erste Runde der Reducer mit 1,75. Dann wird die zweite Welle des Reduzierers gestartet, der den Lastausgleich viel besser macht.
Mit der Erhöhung der Anzahl der Reduzierstücke:
- Framework-Overhead steigt.
- Load-Balancing erhöht.
- Die Ausfallkosten sinken.
Schlussfolgerung
Daher nimmt Reducer die Ausgabe des Mappers als Eingabe. Verarbeiten Sie dann die Schlüssel-Wert-Paare und erzeugen Sie die Ausgabe. Der Ausgang des Reduzierers ist der endgültige Ausgang. Wenn Ihnen dieser Blog gefällt oder Sie Fragen zu Hadoop Reducer haben, teilen Sie uns dies bitte mit, indem Sie einen Kommentar hinterlassen.
Ich hoffe, wir helfen Ihnen weiter.



