Wartung ist etwas, das ein Betriebsteam nicht vermeiden kann. Server müssen mit der neuesten Software, Hardware und Technologie Schritt halten, um sicherzustellen, dass die Systeme stabil sind und mit dem geringstmöglichen Risiko laufen, während sie gleichzeitig neuere Funktionen nutzen, um die Gesamtleistung zu verbessern.
Zweifellos gibt es eine lange Liste von Wartungsaufgaben, die von Systemadministratoren durchgeführt werden müssen, insbesondere wenn es sich um kritische Systeme handelt. Einige der Aufgaben müssen in regelmäßigen Abständen durchgeführt werden, z. B. täglich, wöchentlich, monatlich und jährlich. Manches muss sofort erledigt werden, dringend. Dennoch sollte jede Wartungsmaßnahme nicht zu einem weiteren größeren Problem führen, und jede Wartung muss mit besonderer Sorgfalt durchgeführt werden, um eine Unterbrechung des Geschäftsbetriebs zu vermeiden.
Fragwürdige Zustände und Fehlalarme sind während der Wartungsarbeiten üblich. Dies ist zu erwarten, da der Server während des Wartungszeitraums nicht ordnungsgemäß funktioniert, bis die Wartungsaufgabe abgeschlossen ist. ClusterControl, die allumfassende Verwaltungs- und Überwachungsplattform für Ihre Open-Source-Datenbanken, kann so konfiguriert werden, dass sie diese Umstände versteht, um Ihre Wartungsroutinen zu vereinfachen, ohne die angebotenen Überwachungs- und Automatisierungsfunktionen zu opfern.
Wartungsmodus
ClusterControl hat den Wartungsmodus in Version 1.4.0 eingeführt, in dem Sie einen einzelnen Knoten in den Wartungsmodus versetzen können, der ClusterControl daran hindert, Alarme auszulösen und Benachrichtigungen für die angegebene Dauer zu senden. Der Wartungsmodus kann über die ClusterControl-Benutzeroberfläche und auch mit dem ClusterControl-CLI-Tool namens „s9s“ konfiguriert werden. Gehen Sie auf der Benutzeroberfläche einfach zu Knoten -> Knoten auswählen -> Knotenaktionen -> Wartungsmodus planen :
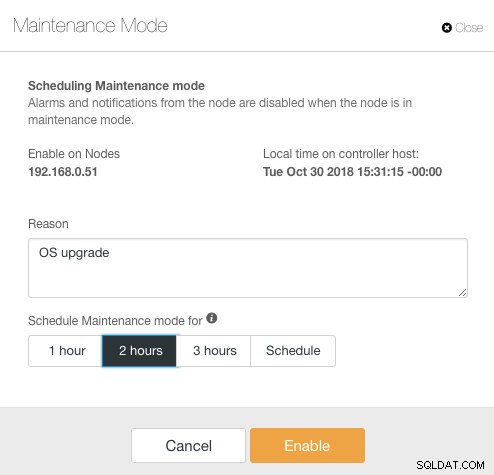
Hier kann man den Wartungszeitraum auf eine vordefinierte Zeit einstellen oder entsprechend planen. Sie können auch den Grund für die Planung des Upgrades aufschreiben, was für Auditzwecke nützlich ist. Sie sollten die folgende Benachrichtigung sehen, wenn der Wartungsmodus aktiv ist:
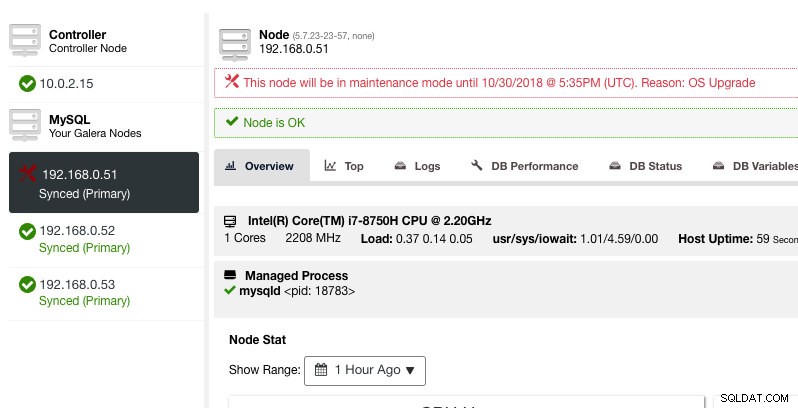
ClusterControl wird den Knoten nicht herabsetzen, daher bleibt der Zustand des Knotens unverändert, es sei denn, Sie führen eine Aktion durch, die den Zustand ändert. Alarme und Benachrichtigungen für diesen Knoten werden reaktiviert, sobald der Wartungszeitraum abgelaufen ist oder der Bediener ihn explizit deaktiviert, indem er zu Knotenaktionen -> Wartungsmodus deaktivieren geht .
Beachten Sie, dass ClusterControl bei aktivierter automatischer Knotenwiederherstellung immer einen Knoten wiederherstellt, unabhängig vom Status des Wartungsmodus. Vergessen Sie nicht, die Knotenwiederherstellung zu deaktivieren, um zu vermeiden, dass ClusterControl Ihre Wartungsaufgaben stört. Dies kann über die obere Zusammenfassungsleiste erfolgen.
Der Wartungsmodus kann auch per ClusterControl CLI oder „s9s“ konfiguriert werden. Mit dem Befehl „s9s maintenance“ können Sie die Wartungszeiträume auflisten und manipulieren. Die folgende Befehlszeile plant morgen ein einstündiges Wartungsfenster für den Knoten 192.168.1.121:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Weitere Details und Beispiele finden Sie in der s9s-Wartungsdokumentation.
Clusterweiter Wartungsmodus
Zum Zeitpunkt der Erstellung dieses Artikels muss die Konfiguration des Wartungsmodus pro verwaltetem Knoten konfiguriert werden. Für eine clusterweite Wartung muss man den Scheduling-Prozess für jeden verwalteten Knoten des Clusters wiederholen. Dies kann unpraktisch sein, wenn Sie eine große Anzahl von Knoten in Ihrem Cluster haben oder wenn das Wartungsintervall zwischen zwei Aufgaben sehr kurz ist.
Glücklicherweise kann ClusterControl CLI (alias s9s) als Problemumgehung verwendet werden, um diese Einschränkung zu überwinden. Sie können "s9s-Knoten" verwenden, um die verwalteten Knoten in einem Cluster aufzulisten und zu manipulieren. Diese Liste kann iteriert werden, um mit dem Befehl „s9s maintenance“ zu einem bestimmten Zeitpunkt einen clusterweiten Wartungsmodus zu planen.
Schauen wir uns ein Beispiel an, um dies besser zu verstehen. Betrachten Sie den folgenden Percona XtraDB-Cluster mit drei Knoten, den wir haben:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Der Cluster hat insgesamt 4 Knoten – 3 Datenbankknoten mit einem ClusterControl-Knoten. Die erste Spalte, STAT, zeigt die Rolle und den Status des Knotens. Das erste Zeichen ist die Rolle des Knotens – „c“ bedeutet Controller und „g“ bedeutet Galera-Datenbankknoten. Angenommen, wir möchten nur die Datenbankknoten für die Wartung planen, können wir die Ausgabe herausfiltern, um den Hostnamen oder die IP-Adresse zu erhalten, wobei der gemeldete STAT ein „g“ am Anfang hat:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Mit einer einfachen Iteration können wir dann ein clusterweites Wartungsfenster für jeden Knoten im Cluster planen. Der folgende Befehl iteriert die Wartungserstellung basierend auf allen im Cluster gefundenen IP-Adressen mithilfe einer for-Schleife, wobei wir planen, den Wartungsvorgang morgen zur gleichen Zeit zu starten und eine Stunde später abzuschließen:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bSie sollten einen Ausdruck von 3 UUIDs sehen, der eindeutigen Zeichenfolge, die jeden Wartungszeitraum identifiziert. Wir können dies dann mit dem folgenden Befehl überprüfen:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Aus der obigen Ausgabe haben wir eine Liste der geplanten Wartungszeiten für jeden Datenbankknoten erhalten. Während der geplanten Zeit wird ClusterControl weder Alarm auslösen noch eine Benachrichtigung senden, wenn es Unregelmäßigkeiten im Cluster feststellt.
Wartungsmodus-Iteration
Einige Wartungsroutinen müssen in regelmäßigen Abständen durchgeführt werden, z. B. Backups, Reinigungs- und Reinigungsaufgaben. Während der Wartungszeit würden wir erwarten, dass sich der Server anders verhält. Allerdings würde jeder Dienstausfall, vorübergehende Unerreichbarkeit oder hohe Last sicherlich Chaos in unserem Überwachungssystem verursachen. Bei häufigen und kurzen Wartungsintervallen kann sich dies als sehr ärgerlich herausstellen und das Überspringen der ausgelösten Fehlalarme kann Ihnen einen besseren Schlaf während der Nacht geben.
Die Aktivierung des Wartungsmodus kann den Server jedoch auch einem größeren Risiko aussetzen, da die strenge Überwachung für diesen Zeitraum ignoriert wird. Daher ist es wahrscheinlich eine gute Idee, die Art des Wartungsvorgangs zu verstehen, den wir durchführen möchten, bevor Sie den Wartungsmodus aktivieren. Die folgende Checkliste soll uns dabei helfen, unsere Richtlinien für den Wartungsmodus festzulegen:
- Betroffene Knoten - Welche Knoten sind an der Wartung beteiligt?
- Konsequenzen – Was passiert mit dem Knoten, wenn der Wartungsvorgang läuft? Wird es unzugänglich, hochgeladen oder neu gestartet?
- Dauer – Wie lange dauert der Wartungsvorgang?
- Häufigkeit – Wie oft sollte der Wartungsvorgang ausgeführt werden?
Lassen Sie es uns in einen Anwendungsfall bringen. Stellen Sie sich vor, wir haben einen Percona XtraDB-Cluster mit drei Knoten und einem ClusterControl-Knoten. Angenommen, unsere Server laufen alle auf virtuellen Maschinen und die VM-Sicherungsrichtlinie erfordert, dass alle VMs jeden Tag ab 1:00 Uhr gesichert werden, jeweils ein Knoten. Während dieses Sicherungsvorgangs wird der Knoten für maximal 10 Minuten eingefroren und der Knoten, der von ClusterControl verwaltet und überwacht wird, ist unzugänglich, bis die Sicherung abgeschlossen ist. Aus Galera-Cluster-Perspektive bringt dieser Vorgang nicht den gesamten Cluster zum Absturz, da der Cluster im Quorum bleibt und die primäre Komponente nicht betroffen ist.
Basierend auf der Art der Wartungsaufgabe können wir sie wie folgt zusammenfassen:
- Betroffene Knoten – Alle Knoten für Cluster-ID 1 (3 Datenbankknoten und 1 ClusterControl-Knoten).
- Folge – Auf die VM, die gesichert wird, kann bis zum Abschluss nicht zugegriffen werden.
- Dauer – Jeder VM-Sicherungsvorgang dauert etwa 5 bis 10 Minuten.
- Häufigkeit – Die VM-Sicherung soll täglich ab 1:00 Uhr auf dem ersten Knoten ausgeführt werden.
Wir können dann einen Ausführungsplan herausbringen, um unseren Wartungsmodus zu planen:
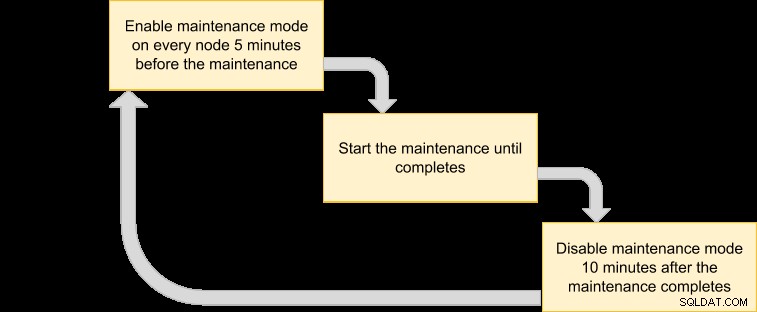
Da alle Knoten im Cluster vom VM-Manager gesichert werden sollen, listen Sie einfach die Knoten für die entsprechende Cluster-ID auf:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Die obige Ausgabe kann verwendet werden, um die Wartung im gesamten Cluster zu planen. Wenn Sie beispielsweise den folgenden Befehl ausführen, aktiviert ClusterControl den Wartungsmodus für alle Knoten unter der Cluster-ID 1 von jetzt an bis zu den nächsten 50 Minuten:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneMit dem obigen Befehl können wir es in eine Ausführungsdatei konvertieren, indem wir es in ein Skript einfügen. Erstellen Sie eine Datei:
$ vim /usr/local/bin/enable_maintenance_modeUnd fügen Sie die folgenden Zeilen hinzu:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSpeichern Sie es und stellen Sie sicher, dass die Dateiberechtigung ausführbar ist:
$ chmod 755 /usr/local/bin/enable_maintenance_modeVerwenden Sie dann cron, um das Skript so zu planen, dass es täglich um 5 Minuten vor 1:00 Uhr ausgeführt wird, kurz bevor der VM-Sicherungsvorgang um 1:00 Uhr beginnt:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeLaden Sie den Cron-Daemon neu, um sicherzustellen, dass unser Skript in die Warteschlange gestellt wird:
$ systemctl reload crond # or service crond reloadDas ist es. Wir können jetzt unsere täglichen Wartungsarbeiten durchführen, ohne von Fehlalarmen und E-Mail-Benachrichtigungen abgehört zu werden, bis die Wartung abgeschlossen ist.
Bonus-Wartungsfunktion - Knotenwiederherstellung überspringen
Wenn die automatische Wiederherstellung aktiviert ist, ist ClusterControl intelligent genug, um einen Knotenausfall zu erkennen, und versucht, einen ausgefallenen Knoten nach einer Karenzzeit von 30 Sekunden wiederherzustellen, unabhängig vom Status des Wartungsmodus. Wussten Sie, dass ClusterControl so konfiguriert werden kann, dass die Knotenwiederherstellung für einen bestimmten Knoten absichtlich übersprungen wird? Dies kann sehr hilfreich sein, wenn Sie eine dringende Wartung durchführen müssen, ohne den Zeitraum und das Ergebnis der Wartung zu kennen.
Stellen Sie sich zum Beispiel vor, dass ein Dateisystem beschädigt ist und das Dateisystem nach einem harten Neustart überprüft und repariert werden muss. Es ist schwierig, im Voraus zu bestimmen, wie viel Zeit für diesen Vorgang benötigt wird. Daher können wir einfach eine Flag-Datei verwenden, um ClusterControl zu signalisieren, die Wiederherstellung für den Knoten zu überspringen.
Fügen Sie zunächst die folgende Zeile in /etc/cmon.d/cmon_X.cnf (wobei X die Cluster-ID ist) auf dem ClusterControl-Knoten hinzu:
node_recovery_lock_file=/root/do_not_recoverStarten Sie dann den cmon-Dienst neu, um die Änderung zu laden:
$ systemctl restart cmon # service cmon restartStellen Sie schließlich sicher, dass die angegebene Datei auf dem Knoten vorhanden ist, den wir für die ClusterControl-Wiederherstellung überspringen möchten:
$ touch /root/do_not_recoverUnabhängig vom Status der automatischen Wiederherstellung und des Wartungsmodus stellt ClusterControl den Knoten nur wieder her, wenn diese Flag-Datei nicht vorhanden ist. Der Administrator ist dann dafür verantwortlich, die Datei auf dem Datenbankknoten zu erstellen und zu entfernen.
Das ist es, Leute. Viel Spaß bei der Wartung!



