Das Hauptziel diesesHadoop-Tutorials ist es, Ihnen eine detaillierte Beschreibung jeder Komponente bereitzustellen, die bei der Arbeit mit Hadoop verwendet wird. In diesem Tutorial behandeln wir den Partitioner in Hadoop.
Was ist Hadoop Partitioner, was braucht der Partitioner in Hadoop, was ist der Standard-Partitioner in MapReduce, wie viele MapReduce-Partitioner werden in Hadoop verwendet?
Wir werden all diese Fragen in diesem MapReduce-Tutorial beantworten.
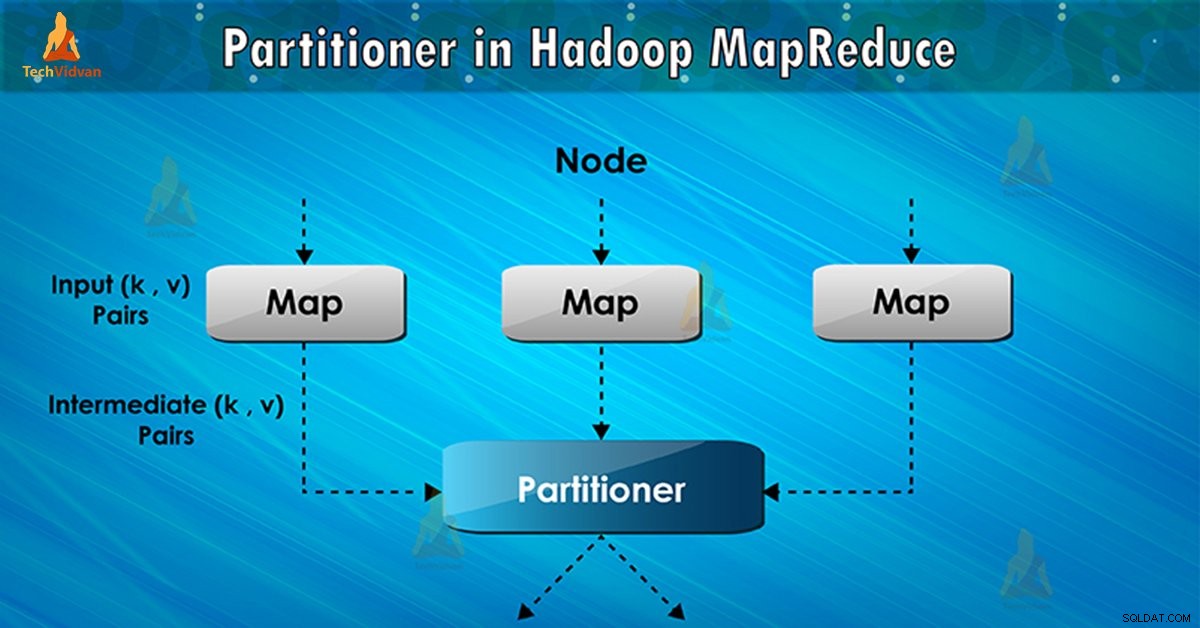
Was ist Hadoop Partitioner?
Der Partitionierer in der MapReduce-Jobausführung steuert die Partitionierung der Schlüssel der Zwischenkartenausgaben. Mit Hilfe der Hash-Funktion leitet der Schlüssel (oder eine Teilmenge des Schlüssels) die Partition ab. Die Gesamtzahl der Partitionen entspricht der Anzahl der Reduzierungsaufgaben.
Auf Basis des Schlüsselwerts , Framework-Partitionen, jeder Mapper Ausgang. Datensätze mit demselben Schlüsselwert gehen in dieselbe Partition (innerhalb jedes Mappers). Dann wird jede Partition an einen Reduzierer gesendet .
Die Partitionsklasse entscheidet, in welche Partition ein bestimmtes Paar (Schlüssel, Wert) gehen soll. Die Partitionsphase im MapReduce-Datenfluss findet nach der Map-Phase und vor der Reduce-Phase statt.
Notwendigkeit von MapReduce Partitioner in Hadoop
Bei der Ausführung des MapReduce-Jobs wird ein Eingabedatensatz verwendet und die Liste der Schlüssel/Wert-Paare erstellt. Dieses Schlüssel-Wert-Paar ist das Ergebnis der Zuordnungsphase. In dem Eingabedaten aufgeteilt werden und jede Aufgabe die Aufteilung verarbeitet und jede Karte die Liste der Schlüsselwertpaare ausgibt.
Dann sendet Framework die Kartenausgabe, um die Aufgabe zu reduzieren. Reduce verarbeitet die benutzerdefinierte Reduce-Funktion auf Kartenausgaben. Vor der Reduce-Phase erfolgt die Partitionierung der Kartenausgabe anhand des Schlüssels.
Hadoop-Partitionierung gibt an, dass alle Werte für jeden Schlüssel zusammen gruppiert werden. Es stellt auch sicher, dass alle Werte eines einzelnen Schlüssels an denselben Reducer gehen. Dies ermöglicht eine gleichmäßige Verteilung der Kartenausgabe über den Reducer.
Der Partitioner in einem MapReduce-Job leitet die Mapper-Ausgabe an den Reducer um, indem er bestimmt, welcher Reducer den jeweiligen Schlüssel handhabt.
Hadoop-Standardpartitionierer
Hash-Partitionierer ist der Standardpartitionierer. Es berechnet einen Hash-Wert für den Schlüssel. Es weist auch die Partition basierend auf diesem Ergebnis zu.
Wie viele Partitionierer in Hadoop?
Die Gesamtzahl der Partitioner hängt von der Anzahl der Reducer ab. Hadoop Partitioner teilt die Daten entsprechend der Anzahl der Reducer auf. Es wird von JobConf.setNumReduceTasks() gesetzt Methode.
Somit verarbeitet der einzelne Reducer die Daten vom einzelnen Partitionierer. Es ist wichtig zu beachten, dass das Framework nur dann einen Partitionierer erstellt, wenn viele Reducer vorhanden sind.
Schlechte Partitionierung in Hadoop MapReduce
Wenn bei der Dateneingabe im MapReduce-Job eine Taste häufiger vorkommt als jede andere Taste. In einem solchen Fall verwenden wir zum Senden von Daten an die Partition zwei Mechanismen, die wie folgt sind:
- Der öfter erscheinende Schlüssel wird an eine Partition gesendet.
- Alle anderen Schlüssel werden auf Basis ihreshashCode() an die Partitionen gesendet .
Wenn hashCode() -Methode verteilt keine anderen Schlüsseldaten über den Partitionsbereich. Dann werden keine Daten an die Reducer gesendet.
Eine schlechte Partitionierung von Daten bedeutet, dass einige Reduzierer im Vergleich zu anderen mehr Dateneingabe haben. Sie haben mehr Arbeit zu tun als andere Reduzierer. Somit muss der gesamte Job darauf warten, dass ein Reduzierer seinen extra großen Teil der Last beendet.
Wie überwindet man schlechte Partitionierung in MapReduce?
Um einen schlechten Partitionierer in Hadoop MapReduce zu überwinden, können wir einen benutzerdefinierten Partitionierer erstellen. Dies ermöglicht die Aufteilung der Arbeitslast auf verschiedene Reduzierer.
Schlussfolgerung
Zusammenfassend ermöglicht Partitioner eine gleichmäßige Verteilung der Kartenausgabe über den Reducer. Im MapReducer Partitioner erfolgt die Partitionierung der Kartenausgabe auf Basis von Schlüssel und Wert.
Daher haben wir in diesem Blog die vollständige Übersicht über Partitioner behandelt. Hoffe es hat euch gefallen. Wenn Sie Zweifel an Hadoop Partitioner haben, vergessen Sie nicht, uns dies mitzuteilen.



