Da Sie den Frühling verwenden. Sie können MultipartFile verwenden um die Datei in Ihren Controller zu bekommen und verwenden Sie dann Binary von org.bson um die Datei in MongoDB zu speichern, wenn Ihre Bildgröße <16 MB ist (wenn die Bildgröße> 16 MB ist, können Sie GridFs
).
Sie müssen Ihrem Projekt nur eine Abhängigkeit hinzufügen – spring-data-mongoDB
Nehmen wir ein Beispiel für eine Benutzersammlung, die wie folgt aussieht:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Hier sehen Sie Binary image die Ihre Bilddatei darstellt.
Erstellen Sie nun mit MongoRepository ein Repository für diese Benutzersammlung
public interface UserRepository extends MongoRepository<User, String>{
}
Erstellen Sie einen Controller für Demozwecke. Verwenden Sie @RequestParam MultipartFile file Um eine Datei auf Ihren Controller zu bekommen, holen Sie sich Bytes aus der Datei und setzen Sie es auf das Benutzerobjekt user.setImage(new Binary(file.getBytes())); vollständiges Beispiel ist unten:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Starten Sie den Server und erreichen Sie den Endpunkt, wie im folgenden Postman-Screenshot gezeigt
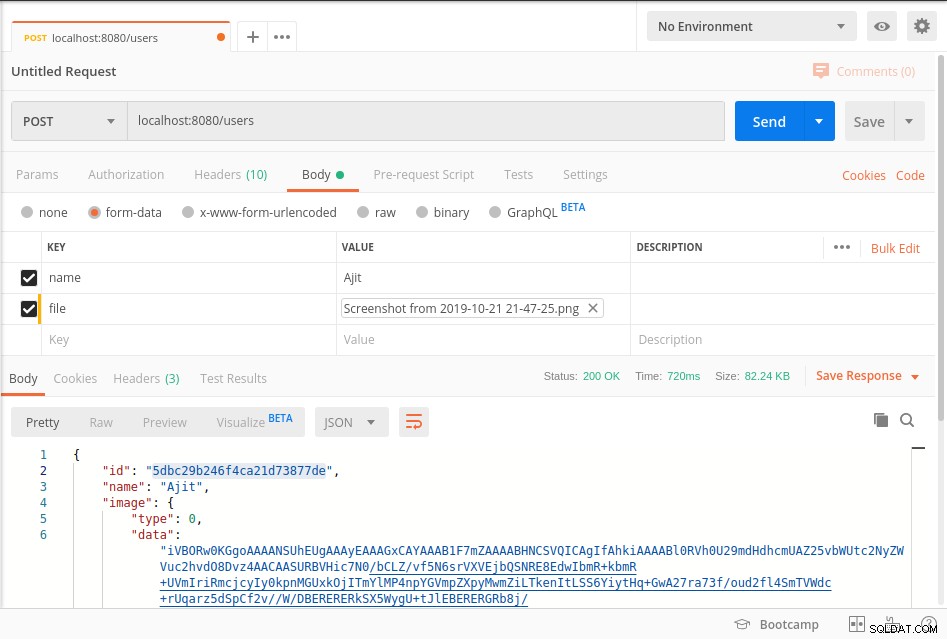
Ihre Daten werden in mongoDb in BinData gespeichert Format und um die Daten aus der Datenbank zu bekommen, lesen Sie bitte getImage Methode des obigen Codes.
BEARBEITEN:
Der Fragesteller verwendet tess4j Bibliothek zum Extrahieren von Text aus Bildern und doOCR ist eine Methode in dieser Bibliothek. Ich habe diese Schritte befolgt, um Text aus dem Bild in meiner Spring-Boot-Anwendung zu extrahieren.
-
Installieren Sie
tesseract-ocrin Ihr System:sudo apt-get install tesseract-ocr -
Laden Sie
eng.traineddataherunter Trainingsdaten von https://github.com/tesseract-ocr/tessdata und verschieben Sie es in den Projektstammordner. -
Fügen Sie Ihrem Projekt die folgende Abhängigkeit hinzu:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Fügen Sie den folgenden Code zu einem bestehenden Projekt hinzu:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}



