Dieses Hadoop-Tutorial dreht sich alles um MapReduce Shuffling und Sorting. Hier stellen wir Ihnen eine detaillierte Beschreibung der Hadoop-Misch- und Sortierphase zur Verfügung.
Zuerst werden wir diskutieren, was MapReduce Shuffling ist, als nächstes mit MapReduce Sortierung, dann werden wir die sekundäre MapReduce-Sortierungsphase im Detail behandeln.
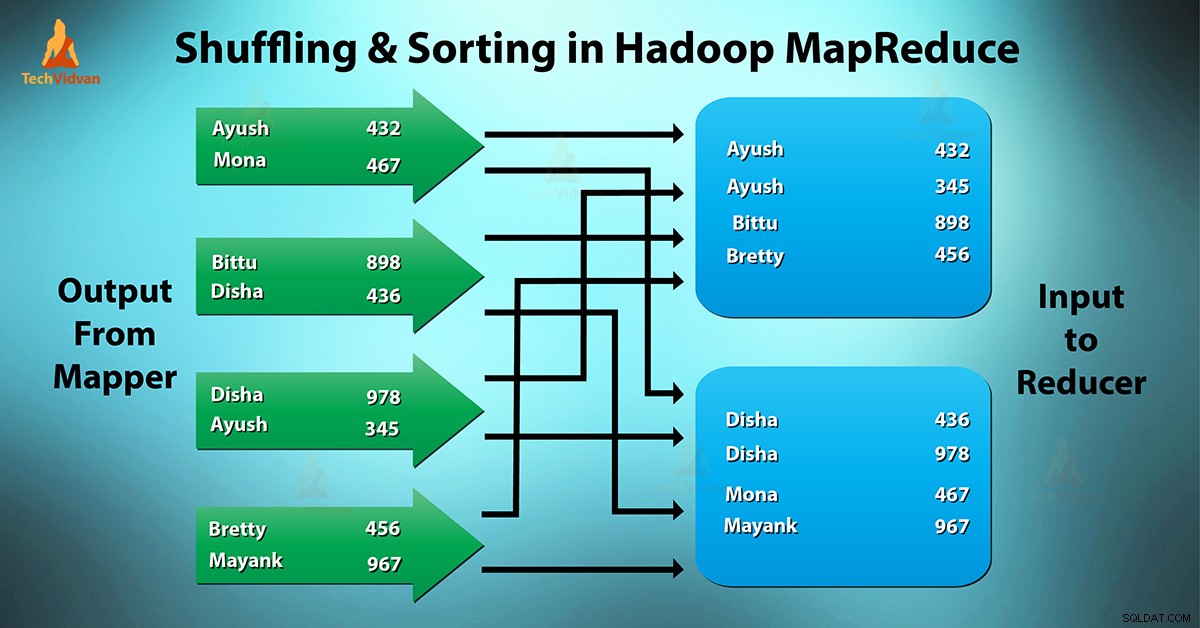
Was ist MapReduce Shuffling und Sortierung?
Mischen ist der Prozess, durch den Mapper übertragen werden Zwischenausgang zum Reducer. Reducer erhält 1 oder mehrere Schlüssel und zugehörige Werte auf der Basis von Reducern.
Der vom Mapper generierte Zwischenschlüssel – Wert wird automatisch nach Schlüssel sortiert. In der Sortierphase findet das Zusammenführen und Sortieren der Kartenausgabe statt.
Mischen und Sortieren in Hadoop erfolgen gleichzeitig.
Shuffling in MapReduce
Der Prozess des Übertragens von Daten von den Mappern zu den Reducern mischt sich. Es ist auch der Prozess, durch den das System die Sortierung durchführt. Dann überträgt es die Kartenausgabe als Eingabe an den Reduzierer. Aus diesem Grund ist für die Reduzierer eine Shuffle-Phase erforderlich.
Andernfalls hätten sie keine Eingabe (oder Eingabe von jedem Mapper). Da das Mischen bereits beginnen kann, bevor die Kartenphase beendet ist. Das spart also etwas Zeit und erledigt die Aufgaben in kürzerer Zeit.
Sortierung in MapReduce
MapReduce Framework sortiert automatisch die vom Mapper generierten Schlüssel. Daher werden vor dem Start des Reducers alle dazwischen liegenden Schlüssel-Wert-Paare nach Schlüssel und nicht nach Wert sortiert. Es sortiert keine Werte, die an jeden Reduzierer übergeben werden. Sie können in beliebiger Reihenfolge sein.
Das Sortieren in einem MapReduce-Job hilft dem Reducer, leicht zu erkennen, wann ein neuer Reduce-Task beginnen sollte.
Das spart Zeit für den Reduzierer. Reducer in MapReduce startet eine neue Reduce-Aufgabe, wenn der nächste Schlüssel in den sortierten Eingabedaten anders ist als der vorherige. Jede Reduzierungsaufgabe nimmt Schlüsselwertpaare als Eingabe und generiert Schlüsselwertpaare als Ausgabe.
Es ist wichtig zu beachten, dass das Mischen und Sortieren in Hadoop MapReduce überhaupt nicht stattfindet, wenn Sie Zero Reducer angeben (setNumReduceTasks(0)).
Wenn Reducer Null ist, stoppt der MapReduce-Job in der Map-Phase. Und die Map-Phase beinhaltet keinerlei Sortierung (selbst die Map-Phase ist schneller).
Sekundäre Sortierung in MapReduce
Wenn wir Reduzierwerte sortieren wollen, verwenden wir eine sekundäre Sortiertechnik. Diese Technik ermöglicht es uns, die Werte (in aufsteigender oder absteigender Reihenfolge) zu sortieren, die an jeden Reduzierer übergeben werden.
Schlussfolgerung
Zusammenfassend findet MapReduce Shuffling und Sorting gleichzeitig statt, um die Mapper-Zwischenausgabe zusammenzufassen. Hadoop-Shuffling-Sorting findet nicht statt, wenn Sie null Reducer angeben (setNumReduceTasks (0)).
Framework sortiert alle Zwischenschlüssel-Wert-Paare nach Schlüssel, nicht nach Wert. Es verwendet eine sekundäre Sortierung zum Sortieren nach Wert. Wenn Sie Vorschläge oder Fragen zur Shuffling- und Sortierphase von MapReduce haben, hinterlassen Sie bitte einen Kommentar in einem Kommentarfeld.
Wir lösen sie gerne.



