In unserem vorherigen Blog haben wir uns mit der Hadoop-Einführung befasst und Features von Hadoop , In diesem Blog werden wir uns jetzt ausführlich mit der HDFS-NameNode-Hochverfügbarkeitsfunktion befassen.
Zunächst werden wir die HDFS NemNode Hochverfügbarkeitsarchitektur besprechen, als nächstes die Implementierung der Hadoop Hochverfügbarkeitsarchitektur unter Verwendung von Quorum Journal Nodes und Shared Storage.
HDFS-NameNode-Hochverfügbarkeit
In HDFS , Daten sind hochverfügbar und trotz Hardwarefehler zugänglich. HDFS ist das zuverlässigste Speichersystem zum Speichern sehr großer Dateien.
HDFS folgt der Master/Slave-Topologie. In welchem Master ist NameNode und Slaves ist DataNode . NameNode speichert Metadaten. Zu den Metadaten gehören die Anzahl der Blöcke, ihre Position, Replikate und andere Details. Zum schnelleren Auffinden von Daten stehen im Master Metadaten zur Verfügung. NameNode verwaltet und weist dem Slave-Knoten Aufgaben zu.
NameNode war der Single Point of Failure (SPOF) vor Hadoop 2.0. Der HDFS-Cluster hatte einen einzelnen NameNode. Wenn der NameNode fehlschlägt, fällt der gesamte Cluster aus.
Single Point of Failure schränkt Hochverfügbarkeit auf folgende Weise ein:
- Wenn ein ungeplantes Ereignis ausgelöst wird, wie z. B. ein Knotenabsturz, dann wäre der Cluster nicht verfügbar, es sei denn, ein Bediener hat den neuen Namensknoten neu gestartet.
- Auch geplante Wartungsaktivitäten wie Hardware-Upgrades auf dem NameNode führen zu Ausfallzeiten des Hadoop-Clusters.
HDFS-NameNode-Hochverfügbarkeitsarchitektur
Die Einführung von Hadoop 2.0 überwindet dieses SPOF durch die Bereitstellung von Unterstützung für mehrere NameNode. Die HDFS-NameNode-Hochverfügbarkeitsarchitektur bietet die Option, zwei redundante NameNodes im selben Cluster in einer Aktiv/Passiv-Konfiguration mit Hot-Standby auszuführen.
- Aktiver NameNode – Es verarbeitet alle HDFS-Client-Operationen im HDFS-Cluster.
- Passiver NameNode – Es ist ein Standby-Namenode. Es hat ähnliche Daten wie der aktive NameNode.
Wenn also der aktive NameNode ausfällt, übernimmt der passive NameNode die gesamte Verantwortung des aktiven Knotens. Somit funktioniert der HDFS-Cluster weiterhin.
Probleme bei der Aufrechterhaltung der Konsistenz im HDFS-High-Availability-Cluster sind wie folgt:
- Aktiver und Standby-NameNode sollten immer miteinander synchron sein, d. h. sie sollten dieselben Metadaten haben. Dadurch kann der Hadoop-Cluster in demselben Namespace-Zustand wiederhergestellt werden, in dem er abgestürzt ist. Und dies ermöglicht uns ein schnelles Failover.
- Es sollte immer nur ein NameNode aktiv sein. Andernfalls führen zwei NameNode zu einer Beschädigung der Daten. Wir nennen dieses Szenario ein „Split-Brain-Szenario“. “, wo ein Cluster in den kleineren Cluster unterteilt wird. Jeder glaubt, dass er der einzige aktive Cluster ist. „Fencing“ vermeidet ein solches Fencing ist ein Prozess, bei dem sichergestellt wird, dass zu einem bestimmten Zeitpunkt nur ein NameNode aktiv bleibt.
Implementierung der Hadoop-Hochverfügbarkeitsarchitektur
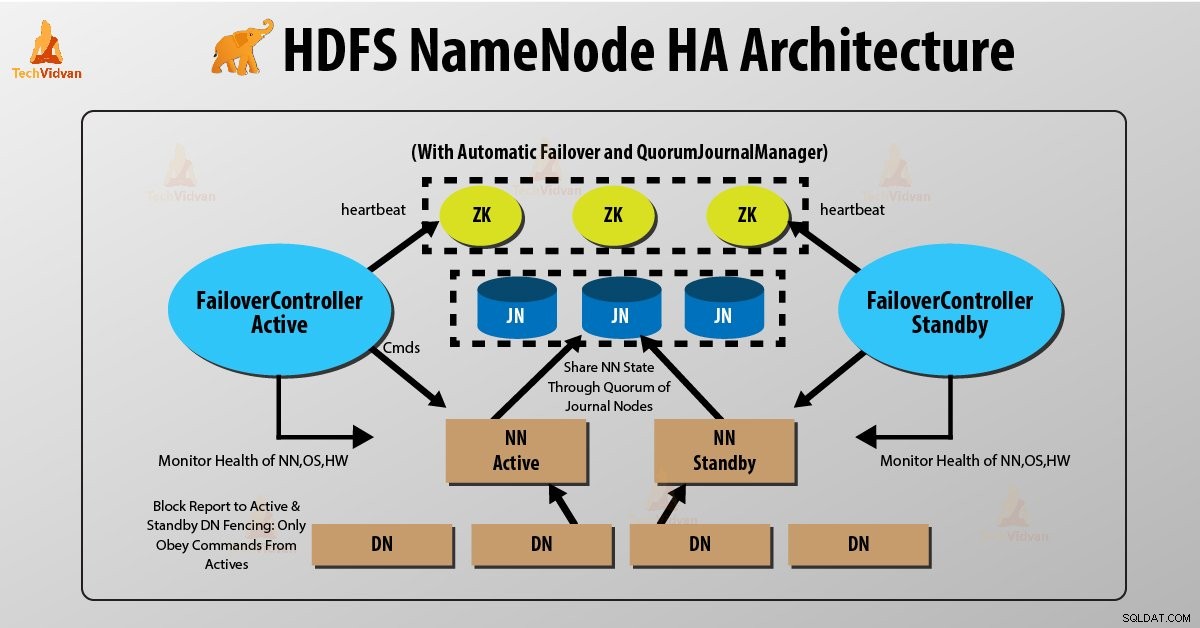
In der HDFS-NameNode-Hochverfügbarkeitsarchitektur werden zwei NameNodes gleichzeitig ausgeführt. Der HDFS-Client kann die Active- und Standby-NameNode-Konfiguration auf zwei Arten implementieren:
- Quorum-Journalknoten verwenden
- Gemeinsam genutzten Speicher verwenden
1. Verwenden von Quorum-Journalknoten
Quorum-Journalknoten ist eine HDFS-Implementierung. QJN stellt Bearbeitungsprotokolle bereit. Es ermöglicht die gemeinsame Nutzung dieser Bearbeitungsprotokolle zwischen dem aktiven und dem Standby-NameNode.
Standby-Namenode kommuniziert und synchronisiert mit dem aktiven NameNode für hohe Verfügbarkeit. Dies geschieht durch eine Gruppe von Daemons namens „Journal nodes“. Die Quorum-Journalknoten werden als Gruppe von Journalknoten ausgeführt. Es sollten mindestens drei Journalknoten vorhanden sein.
Für N Journalknoten kann das System höchstens (N-1)/2 Ausfälle tolerieren. Das System arbeitet also weiter. Bei drei Journalknoten kann das System also den Ausfall von einem {(3-1)/2} von ihnen tolerieren.
Jedes Mal, wenn ein aktiver Knoten eine Änderung durchführt, protokolliert er die Änderung an allen Journalknoten.
Der Standby-Knoten liest die Bearbeitungen aus den Journalknoten und wendet sie konstant auf seinen eigenen Namensraum an. Im Falle eines Failovers stellt der Standby-Server sicher, dass er alle Änderungen von den Journalknoten gelesen hat, bevor er sich selbst in den Status „Aktiv“ versetzt. Dadurch wird sichergestellt, dass der Namespace-Status vollständig synchronisiert ist, bevor ein Fehler auftritt.
Um ein schnelles Failover bereitzustellen, muss der Standby-Knoten über aktuelle Informationen zum Speicherort von Datenblöcken im Cluster verfügen. Damit dies geschieht, ist die IP-Adresse beider NameNode für alle Datenknoten verfügbar und sie senden Blockstandortinformationen und Heartbeats an beide NameNode.
Umzäunung von NameNode
Für den korrekten Betrieb eines HA-Clusters sollte immer nur einer der NameNodes aktiv sein. Andernfalls würde der Namespace-Zustand zwischen den beiden NameNodes abweichen. Fencing ist also ein Prozess, um diese Eigenschaft in einem Cluster sicherzustellen.
- Die Journalknoten führen dieses Fencing durch, indem sie jeweils nur einen Namensknoten als Schreiber zulassen.
- Der Standby-NameNode übernimmt die Verantwortung für das Schreiben in die Journalknoten und verhindert, dass andere NameNode aktiv bleiben.
- Schließlich kann der neue aktive NameNode seine Aktivitäten ausführen.
2. Shared Storage verwenden
Standby und aktiver NameNode synchronisieren sich über „Shared Storage Device“ miteinander. Für diese Implementierung müssen sowohl der aktive Namensknoten als auch der Standby-Namensknoten Zugriff auf das bestimmte Verzeichnis auf dem gemeinsam genutzten Speichergerät haben (d. h. Netzwerkdateisystem).
Wenn ein aktiver NameNode eine Namespace-Änderung durchführt, protokolliert er eine Aufzeichnung der Änderung in einer Bearbeitungsprotokolldatei, die im gemeinsam genutzten Verzeichnis gespeichert ist. Der Standby-NameNode überwacht dieses Verzeichnis auf Bearbeitungen, und wenn Bearbeitungen auftreten, wendet der Standby-NameNode sie auf seinen eigenen Namespace an. Im Falle eines Fehlers stellt der Standby-NameNode sicher, dass er alle Bearbeitungen aus dem gemeinsam genutzten Speicher gelesen hat, bevor er sich selbst in den aktiven Zustand befördert. Dadurch wird sichergestellt, dass der Namespace-Status vollständig synchronisiert ist, bevor ein Failover auftritt.
Um das „Split-Brain-Szenario“ zu verhindern, bei dem der Namespace-Status zwischen den beiden NameNode abweicht, muss ein Administrator mindestens eine Fencing-Methode für den gemeinsam genutzten Speicher konfigurieren.
Schlussfolgerung
Daher bietet Hadoop 2.0 HDFS HA einen einzelnen aktiven NameNode und einen einzelnen Standby-NameNode. Einige Bereitstellungen erfordern jedoch ein hohes Maß an Fehlertoleranz . Die neue Version 3.0 von Hadoop ermöglicht es dem Benutzer, viele Standby-NameNodes auszuführen.
Beispiel:Konfigurieren von fünf Journalnodes und drei NameNode. Infolgedessen ist der Hadoop-Cluster in der Lage, den Ausfall von zwei statt einem Knoten zu tolerieren.
Bitte teilen Sie Ihre Erfahrungen und Vorschläge in Bezug auf HDFS NameNode High Availability im Kommentarbereich unten.



