In diesem Hadoop-Tutorial , stellen wir Ihnen eine detaillierte Beschreibung von Hadoop Combiner zur Verfügung. Zuerst werden wir sehen, was MapReduce Combiner ist, was die Schlüsselrolle von Combiner in MapReduce ist.
Dann besprechen wir das Beispiel des MapReduce-Programms mit und ohne Combiner in Hadoop. Zuletzt werden wir auch einige Vor- und Nachteile von Combiner in MapReduce sehen.
Was ist Hadoop Combiner?
Kombinator wird auch als „Mini-Reducer“ bezeichnet “, das den Mapper zusammenfasst Datensatz mit demselben Schlüssel ausgeben, bevor er an den Reducer übergeben wird .
Bei einem großen Dataset, wenn wir den MapReduce-Job ausführen. Mapper generiert also große Mengen an Zwischendaten. Anschließend übergibt das Framework diese Zwischendaten an den Reducer zur weiteren Verarbeitung.
Dies führt zu einer enormen Netzwerküberlastung. Das Hadoop-Framework bietet eine Funktion namens Combiner das spielt eine Schlüsselrolle bei der Verringerung der Netzwerküberlastung.
Die Hauptaufgabe von Combiner, einem „Mini-Reducer“, besteht darin, die Ausgabedaten des Mappers zu verarbeiten, bevor sie an den Reducer weitergeleitet werden. Es läuft nach dem Mapper und vor dem Reducer. Seine Verwendung ist optional.
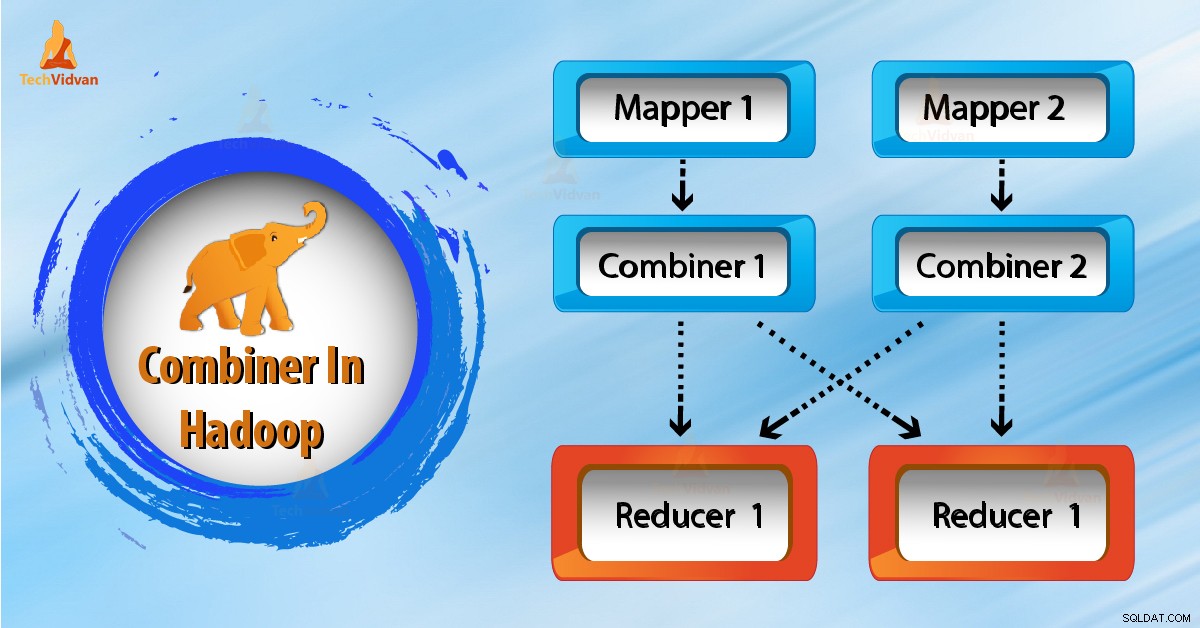
Wie funktioniert Combiner in Hadoop?
Lassen Sie uns nun lernen, wie sich die Dinge ändern, wenn wir den Combiner in MapReduce verwenden?

Wie wir im obigen Diagramm sehen, ist kein Combiner vorhanden. Die Eingabe wird in zwei Mapper aufgeteilt. Das Framework generiert 9 Schlüssel von den Mappern.
Jetzt haben wir also (9 Schlüssel/Wert) Zwischendaten. Ein weiterer Mapper sendet diesen Schlüsselwert direkt zum Reduzierstück. Beim Senden von Daten an den Reducer wird etwas Netzwerkbandbreite verbraucht. Es dauert länger, Daten an den Reducer zu übertragen, wenn die Datenmenge groß ist.

Nun aus dem obigen Diagramm, wenn wir einen Combiner zwischen Mapper und Reducer verwenden. Dann mischt der Kombinierer 9 Schlüssel/Wert, bevor er sie an den Reduzierer sendet. Und generiert dann 4 Schlüssel/Wert-Paare als Ausgabe.
Jetzt muss Reducer nur noch 4 Schlüssel/Wert-Paardaten verarbeiten, die von 2 Combinern generiert werden. Daher wird Reducer nur 4 Mal ausgeführt, um die endgültige Ausgabe zu erzeugen. Dadurch wird die Gesamtleistung gesteigert.
Vorteile von Combiner in MapReduce
Lassen Sie uns nun die Vorteile von Hadoop Combiner in MapReduce besprechen.
- Die Verwendung von Combiner reduziert die Zeit, die für die Datenübertragung zwischen Mapper und Reducer benötigt wird.
- Combiner verbessert die Gesamtleistung des Reducers.
- Es verringert die Datenmenge, die der Reducer verarbeiten muss.
Nachteile von Combiner in MapReduce
Es gibt auch einige Nachteile von Hadoop Combiner. Lassen Sie uns jetzt dasselbe besprechen.
- Wenn Hadoop im lokalen Dateisystem die Schlüssel-Wert-Paare speichert und den Combiner später ausführt, führt dies zu teuren Festplatten-E/A.
- MapReduce-Jobs können sich nicht auf die Combiner-Ausführung verlassen, da es keine Garantie für ihre Ausführung gibt.
Schlussfolgerung
Daher spielt Hadoop Combiner eine Schlüsselrolle bei der Reduzierung von Netzwerküberlastungen. Es verbessert die Gesamtleistung des Reducers, indem es die Ausgabe von Mapper zusammenfasst.
Ich hoffe, Sie haben jetzt ein klares Verständnis von Hadoop Combiner. Wenn Sie noch Fragen haben, teilen Sie uns dies bitte mit, indem Sie einen Kommentar in einem Abschnitt unten hinterlassen.



