Wenn Sie alles über Hadoop MapReduce wissen wollen, müssen Sie an der richtigen Stelle gelandet. Dieses MapReduce Tutorial bietet Ihnen die komplette Führung über alles und jeden in Hadoop MapReduce.
In diesem MapReduce Einführung, erkunden Sie, was Hadoop MapReduce ist, wie die MapReduce Framework funktioniert. Der Artikel umfasst auch MapReduce Dataflow, Verschiedene Phasen in MapReduce, Mapper, Reducer, Partitioner, Cominer, Schlurfen, Sortierung, Daten Ort, und viele mehr.
Wir haben auch die Vorteile des MapReduce Framework eingetragen.
Lassen Sie uns zuerst untersuchen, warum wir Hadoop MapReduce benötigen.
Warum MapReduce?
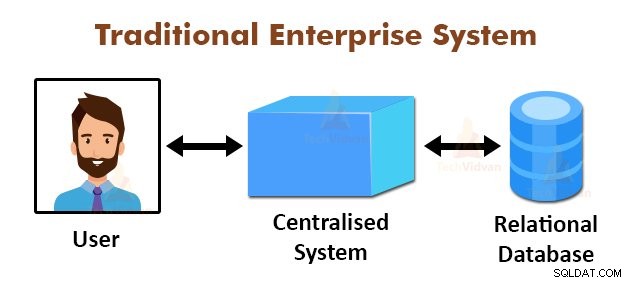
Die obige Abbildung zeigt die schematische Darstellung der traditionellen Unternehmenssysteme. Die traditionellen Systeme haben normalerweise einen zentralen Server zum Speichern und Verarbeiten von Daten. Dieses Modell ist nicht geeignet für die Verarbeitung von großen Mengen von skalierbaren Daten.
Auch könnte dieses Modell nicht durch die Standard-Datenbankserver untergebracht werden. Zusätzlich kann das zentrale System zu viel Engpass erzeugt, während mehrere Dateien gleichzeitig zu verarbeiten.
Durch die Verwendung des MapReduce-Algorithmus gelöst Google diesen Engpass Problem. Die MapReduce Framework teilt die Aufgabe in kleine Teile und Abtretungsempfänger Aufgaben zu vielen Computern.
Später werden die Ergebnisse bei einer alltäglich gesammelt und dann das Ergebnis-Datensatz integriert zu bilden.
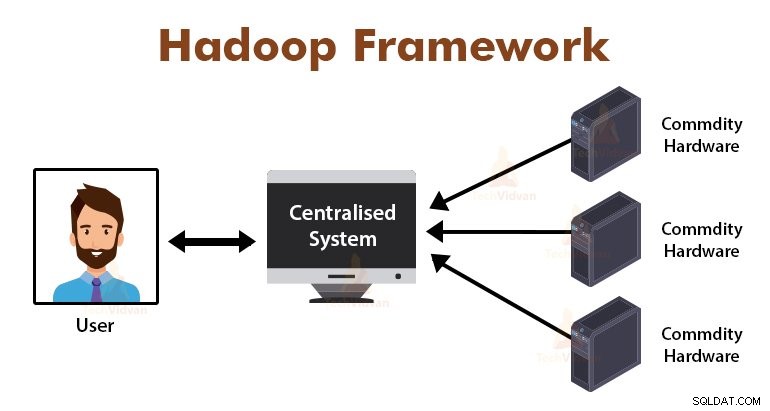
Einführung in MapReduce-Framework
MapReduce ist die Verarbeitungsschicht in Hadoop. Es ist eine Software-Framework für Verarbeitung von großen Datenmengen parallel durch die Aufgabe, in den Satz von unabhängigen Aufgaben geteilt wird.
Wir müssen nur die Business-Logik in den Weg legen die MapReduce funktioniert, und der Rahmen wird der Rest Dinge kümmern. Die MapReduce Framework funktioniert, indem die Arbeit in kleine Aufgaben und Abtretungsempfänger an die Slaves diese Aufgaben teilen.
Die MapReduce-Programme werden in einem bestimmten Stil durch die funktionalen Programmierkonstrukte, specifical Idiome für die Verarbeitung der Datenlisten beeinflusst geschrieben.
In MapReduce, sind die Eingaben in Form einer Liste aus, und die Ausgabe von dem Rahmen ist auch in Form einer Liste. MapReduce ist das Herz von Hadoop. Die Effizienz und die Mächtigkeit von Hadoop ist aufgrund der MapReduce Framework Parallelverarbeitung.
Lassen Sie uns nun untersuchen, wie Hadoop MapReduce funktioniert.
Wie Hadoop MapReduce funktioniert?
Die Hadoop MapReduce Framework arbeitet mit einem Job in unabhängige Aufgaben zu teilen und diese Aufgaben auf Slave-Maschinen ausgeführt werden. Der MapReduce Job wird in zwei Stufen durchgeführt, die Karte Phase sind und die Verringerung Phase.
Die Eingabe in und Ausgabe aus beiden Phasen sind Schlüssel, Wert-Paare. Die MapReduce Framework ist auf dem Datenlokalitätsprinzip basiert (später erörtert), das bedeutet, dass es um die Berechnung zu den Knoten, an denen Daten gespeichert sendet.
- Karte Phase - In der Map-Phase, die benutzerdefinierte Map-Funktion verarbeitet die Eingangsdaten. In der Map-Funktion, legt der Benutzer die Geschäftslogik. Die Ausgabe von der Karte Phase ist die Zwischenausgänge und wird auf der lokalen Festplatte gespeichert werden.
- Reduce Phase - Diese Phase ist die Kombination aus der Shuffle-Phase und die Verringerung Phase. In der Phase reduzieren, wird die Ausgabe von der Karte Stufe zur Reducer geleitet, wo sie aggregiert werden. Der Ausgang der Reduce-Phase ist die endgültige Ausgabe. In der Phase reduzieren, werden die Benutzer-definierte Funktion reduzieren verarbeitet die Mapper-Ausgang und erzeugt die endgültigen Ergebnisse.
Während des MapReduce Jobs sendet der Hadoop Rahmen die Karten Aufgaben und die Reduzierung der Aufgaben zu entsprechenden Maschinen im Cluster.
Der Rahmen selbst verwaltet alle Einzelheiten des Daten-Weitergabe, wie beispielsweise Aufgaben, die Ausgabe, die Erledigung der Aufgabe zu überprüfen, und das Kopieren von Daten zwischen den Knoten, um dem Cluster. Die Aufgaben finden an den Knoten, an denen Daten gespeichert sind, um den Netzwerkverkehr zu reduzieren.
MapReduce Datenfluss
Sie alle könnten wollen wissen, wie diese Schlüsselwertepaare generiert und wie MapReduce die Eingangsdaten verarbeitet. Dieser Abschnitt beantwortet alle diese Fragen.
Lassen Sie uns sehen, wie Daten aus verschiedenen Phasen in Hadoop MapReduce fließen muss anstehende Daten in einem parallelen und verteilten Art und Weise zu handhaben.
1. Eingabedateien
Der Eingabedatensatz, der durch das MapReduce Programm verarbeitet werden soll, wird in der Eingabedatei gespeichert. Die Eingabedatei wird in dem Hadoop Distributed File System gespeichert.
2. InputSplit
Der Datensatz in den Eingabedateien in das logische Modell aufgeteilt. Die geteilte Größe ist im allgemeinen gleich die HDFS Blockgrße. Jede Spaltung wird durch die einzelnen Mapper verarbeitet werden.
3. Inputformat
Inputformat gibt die Datei Eingangsspezifikation. Es definiert die Art und Weise an die RecordReader in dem der Datensatz aus der Eingabedatei in das Schlüssel umgewandelt wird, Wert-Paare.
4. RecordReader
RecordReader liest die Daten aus den InputSplit und wandelt Datensätze in den Schlüssel, Wert-Paare, und präsentiert sie dem Mapper.
5. Mapper
Mappers nehmen Schlüssel, Wert-Paare als Eingabe von der RecordReader und verarbeiten sie durch benutzerdefinierte Kartenfunktion zu implementieren. In jedem Mapper, zu einer Zeit, wird eine einzelne Split verarbeitet.
Der Entwickler setzte die Business-Logik in der Map-Funktion. Die Ausgabe von allen Mapper wird die Zwischenausgabe, die auch in Form eines Schlüssels, Wert-Paaren.
6. Shuffle und Sortieren
Die Zwischenausgabe durch Mappers erzeugt wird sortiert vor, um das Passieren Reducer Netzwerküberlastung zu verringern. Die sortierte Zwischenergebnisse werden dann an den Reducer über das Netzwerk neu gemischt.
7. Reducer
Das Reduktionsprozess und aggregiert die Mapper-Ausgänge von benutzerdefinierten Implementierung reduzieren Funktion. Die Reduzierungen Ausgabe ist die letzte Ausgabe und ist im Hadoop Distributed File System (HDFS).
gespeichertLassen Sie uns nun einige Terminologien und Konzepte voraus des Hadoop MapReduce Framework studieren.
Key-Wert-Paare in MapReduce
Die MapReduce Framework arbeitet auf dem Schlüssel, Wert-Paare, weil es mit dem nicht-statischen Schema behandelt. Es nimmt Daten in Form von Schlüsseln, Wert-Paar, und erzeugen Ausgang ist auch in der Form eines Schlüssel, Wert-Paare.
Das MapReduce Schlüsselwertpaar ist eine Aufzeichnung Einheit, die durch den MapReduce Job für die Ausführung empfangen wird. In einem Schlüssel-Wert-Paar:
- Key ist die Linie vom Anfang der Zeile in der Datei versetzt.
- Wert ist die Linie, Inhalt, mit Ausnahme der Linie Terminator.
MapReduce-Partitionierungsprogramm
Die Hadoop MapReduce Partitioner partitioniert den Schlüsselraum. Partitionieren Schlüsselraum in MapReduce gibt an, dass alle die Werte der einzelnen Tasten zusammen gruppiert wurden, und es wird sichergestellt, dass alle die Werte der einzelnen Schlüssel zur gleichen Reducer gehen müssen.
Diese Aufteilung ermöglicht eine gleichmäßige Verteilung des Mapper der Ausgabe über Reducer, indem sichergestellt wird, dass die rechte Taste rechts Reducer geht.
Der Standard MapReducer Partitionierungs ist die Hash-Partitionierung, welche Partitionen die keyspaces auf der Basis des Hash-Wertes.
MapReduce Combiner
Die MapReduce Combiner ist auch bekannt als die „Semi-Reducer“. Es spielt eine wichtige Rolle bei der Verringerung der Netzwerküberlastung. Die MapReduce Framework stellt die Funktionalität der Kombinator zu definieren, der das Zwischenausgangssignal von Mappers kombiniert, bevor sie an Reducer geben.
Die Aggregation von Mapper Ausgaben vor dem Reducer vorbei hilft den Rahmen kleine Datenmengen zu mischen, zu niedrige Netzüberlastung führen.
Die Hauptfunktion des Kombinators ist, um die Ausgabe des Mappers mit dem gleichen Schlüssel zusammenzufassen und geben es an die Reducer. Die Combiner Klasse ist zwischen der Mapper-Klasse und der Reducer-Klasse verwendet.
Daten Ort in MapReduce
Datenlokalität bezieht sich auf „Moving Berechnung näher an den Daten keine Daten, sondern auf die Berechnung zu bewegen.“ Es ist viel effizienter, wenn die von der Anwendung angefordert Berechnung auf der Maschine ausgeführt wird, in dem die Daten gespeichert ist angefordert.
Das ist sehr wahr in dem Fall, in dem die Datengröße ist riesig. Es ist, weil es die Netzwerküberlastungen minimiert und erhöht den Gesamtdurchsatz des Systems.
Die einzige Voraussetzung dafür ist, dass es besser ist, Berechnung näher an die Maschine zu bewegen, wo Daten vorhanden statt, Daten an die Maschine zu bewegen, wo die Anwendung ausgeführt wird.
Apache Hadoop arbeitet auf einem sehr großen Datenvolumen, so dass es nicht effizient ist, so große Daten über das Netzwerk zu bewegen. Daher kam der Rahmen mit dem innovativsten Prinzip bis der Datenlokalität ist, die Datenberechnungslogik bewegt anstelle von Daten zu Berechnungsalgorithmen zu bewegen. Dies wird Datenlokalität genannt.
Vorteile von MapReduce
1. Skalierbarkeit: Der MapReduce-Framework ist hoch skalierbar. Es ermöglicht es Unternehmen, Anwendungen von großen Gruppen von Maschinen ausgeführt werden, die der Einsatz von Tausenden von Terabytes von Daten beinhalten kann.
2. Flexibilität Der MapReduce-Framework bietet Flexibilität für die Organisation von Prozessdaten von jeder Größe und jedes Format, entweder strukturiert, semi-strukturiert oder unstrukturiert.
3. Sicherheit und Authentifizierung: MapReduce-Programmiermodell bietet hohe Sicherheit. Es schützt unberechtigten Zugriff auf die Daten und verbessert die Cluster-Sicherheit.
4. Kostengünstig: Das Framework verarbeitete Daten über den Cluster von Standardhardware, die in teueren Maschinen sind. Daher ist es sehr kostengünstig.
5. Schnell: MapReduce verarbeitet Daten parallel, aufgrund derer es sehr schnell ist. Es dauert nur wenige Minuten zum Prozess Terabyte Daten.
6. Ein einfaches Modell für die Programmierung: Die MapReduce-Programme können in jeder beliebigen Sprache wie Java, Python, Perl, R, etc. So geschrieben werden, kann jeder leicht erlernen und Schreib MapReduce-Programme und erfüllt ihre Datenanforderungen zu verarbeiten.
Verwendung von MapReduce
1. Log-Analyse: MapReduce ist im Grunde für die Analyse von Protokolldateien verwendet. Der Rahmen bricht die großen Protokolldateien in die Spalte und eine Mapper Suche nach den verschiedenen Web-Seiten, auf die zugegriffen wurde.
Jedes Mal, wenn eine Web-Seite im Protokoll gefunden wird, dann wird ein Schlüssel, Wert Paar des Minderer geleitet, wo der Schlüssel ist die Webseite ist, und der Wert „1“. Nach dem Aussenden eines Schlüssel, Wert-Paar Reducer aggregieren die Reduzierungen, die Anzahl der für bestimmte Web-Seiten.
Das Endergebnis wird die Gesamtzahl der Treffer für jede Webseite sein.
2. Volltextindizierung: MapReduce ist auch für die Durchführung der Volltextindizierung verwendet. Der Mapper in MapReduce wird jede Phrase oder ein Wort in einem Dokument in die Dokumentstruktur. Die Reducer wird diese Zuordnungen auf einen Index schreiben.
3. Google verwendet MapReduce für die Berechnung ihrer Pagerank.
4. Reverse-Web-Link-Graph: MapReduce ist auch in umge Web-Link-Grafik verwendet. Die Map-Funktion gibt das URL-Ziel und Quelle unter Eingabe von der Webseite (Quelle).
Die verringern Funktion verkettet dann die Liste aller Quell-URLs, die mit dem angegebenen Ziel-URL zugeordnet sind, und es gibt die Ziel- und Quellenverzeichnis.
5. Wortanzahl in einem Dokument: MapReduce Framework kann zum Zählen der Anzahl, wie oft das Wort erscheint in einem Dokument verwendet werden.
Zusammenfassung
Das ist alles über die Hadoop MapReduce Tutorial. Das Framework verarbeitet große Datenmengen parallel über den Cluster von Standardhardware. Er teilt den Job in unabhängige Aufgaben und führt sie parallel auf verschiedenen Knoten im Cluster.
MapReduce windet den Engpass des traditionellen Enterprise-System. Das Framework arbeitet auf dem Schlüssel, Wert-Paare. Der Benutzer definiert die beiden Funktionen, die Kartenfunktion und die Funktion zu reduzieren.
Die Business-Logik wird in die Kartenfunktion setzen. Der Artikel hatte verschiedene fortschrittliche Konzepte des MapReduce Framework erläutert.



