In diesem Blog stellen wir Ihnen die vollständige Einführung in Hadoop Mapper zur Verfügung . Ich
In diesem Blog werden wir beantworten, was Mapper in Hadoop MapReduce ist, wie Hadoop-Mapper funktionieren, wie der Mapper in Mapreduce abläuft und wie Hadoop Schlüssel-Wert-Paare in MapReduce generiert.
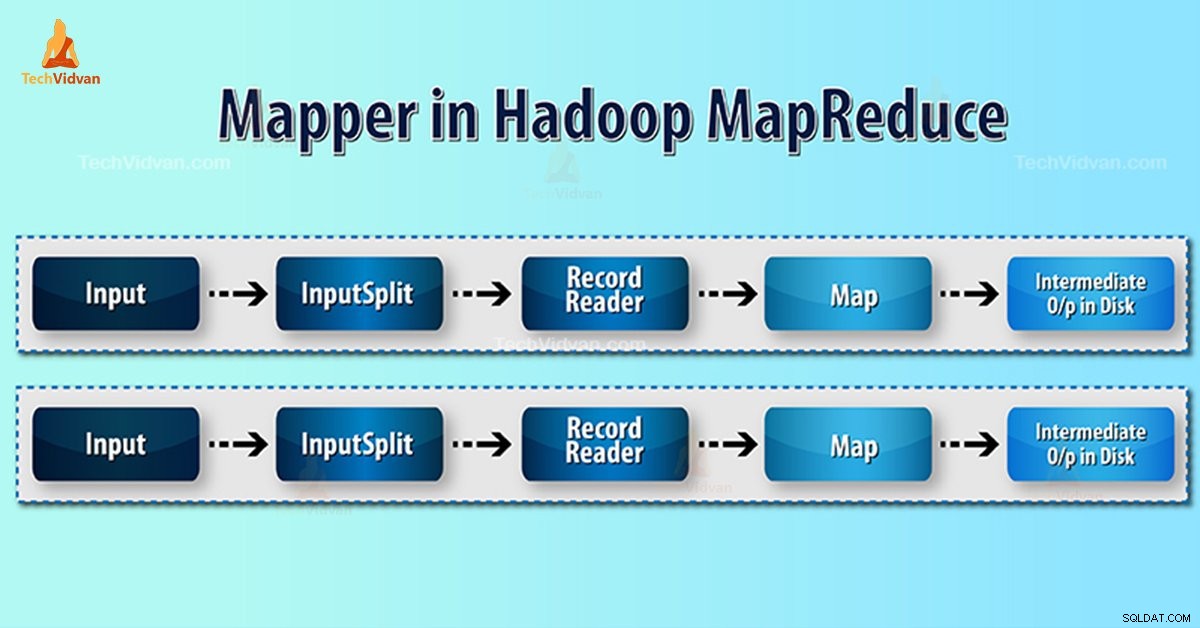
Einführung in Hadoop Mapper
Hadoop-Mapper verarbeitet den vom RecordReader erzeugten Eingabedatensatz und generiert Zwischenschlüssel-Wert-Paare. Der Zwischenausgang unterscheidet sich vollständig vom Eingangspaar.
Die Ausgabe des Mappers ist die vollständige Sammlung von Schlüssel-Wert-Paaren. Vor dem Schreiben der Ausgabe für jede Mapper-Aufgabe findet eine Partitionierung der Ausgabe auf der Grundlage des Schlüssels statt. Die Partitionierung spezifiziert also, dass alle Werte für jeden Schlüssel zusammen gruppiert werden.
Hadoop MapReduce generiert eine Zuordnungsaufgabe für jeden InputSplit.
Hadoop MapReduce versteht nur Schlüssel-Wert-Paare von Daten. Bevor also Daten an den Mapper gesendet werden, sollte das Hadoop-Framework Daten in das Schlüssel-Wert-Paar umwandeln.
Wie wird ein Schlüssel-Wert-Paar in Hadoop generiert?
Nachdem wir verstanden haben, was ein Mapper in Hadoop ist, werden wir nun diskutieren, wie Hadoop Schlüssel-Wert-Paare generiert?
- InputSplit – Es ist die logische Darstellung der vom InputFormat. generierten Daten Im MapReduce-Programm beschreibt es eine Arbeitseinheit, die eine einzelne Kartenaufgabe enthält.
- RecordReader- Er kommuniziert mit dem inputSplit. Und wandelt die Daten dann in Schlüssel-Wert-Paare um, die zum Lesen durch den Mapper geeignet sind. RecordReader verwendet standardmäßig TextInputFormat, um Daten in das Schlüssel-Wert-Paar zu konvertieren.
Mapper-Prozess in Hadoop MapReduce
InputSplit wandelt die physische Darstellung der Blöcke in eine logische für den Mapper um. Um beispielsweise die 100-MB-Datei zu lesen, sind 2 InputSplit erforderlich. Für jeden Block erstellt das Framework einen InputSplit. Jeder InputSplit erstellt einen Mapper.
MapReduce InputSplit hängt nicht immer von der Anzahl der Datenblöcke ab . Wir können die Nummer eines Splits ändern, indem wir mapred.max.split.size property setzen während der Auftragsausführung.
MapReduce RecordReader ist für das Lesen/Konvertieren von Daten in Schlüssel-Wert-Paare bis zum Ende der Datei verantwortlich. RecordReader weist jeder in der Datei vorhandenen Zeile einen Byte-Offset zu.
Dann erhält Mapper dieses Schlüsselpaar. Mapper erzeugt die Zwischenausgabe (Schlüssel-Wert-Paare, die verständlich reduziert werden können).
Wie viele Kartenaufgaben in Hadoop?
Die Anzahl der Zuordnungsaufgaben hängt von der Gesamtzahl der Blöcke der Eingabedateien ab. In der MapReduce-Karte scheint das richtige Maß an Parallelität bei etwa 10-100 Karten/Knoten zu liegen. Aber es gibt 300 Karten für CPU-leichte Kartenaufgaben.
Beispielsweise haben wir eine Blockgröße von 128 MB. Und wir erwarten 10 TB an Eingabedaten. Somit produziert es 82.000 Karten. Daher hängt die Anzahl der Maps vom InputFormat ab.
Mapper =(Gesamtdatengröße)/ (Eingabeaufteilungsgröße)
Beispiel – Die Datengröße beträgt 1 TB. Die Eingabeaufteilungsgröße beträgt 100 MB.
Mapper =(1000*1000)/100 =10.000
Schlussfolgerung
Daher nimmt Mapper in Hadoop einen Datensatz und wandelt ihn in einen anderen Datensatz um. Daher zerlegt es einzelne Elemente in Tupel (Schlüssel/Wert-Paare).
Ich hoffe, Ihnen gefällt dieser Block, wenn Sie Fragen zum Hadoop-Mapper haben, hinterlassen Sie bitte einen Kommentar in einem der unten angegebenen Abschnitte. Wir lösen sie gerne.



