Dieser Blogbeitrag präsentiert ein einfaches „Hallo Welt“-Beispiel, wie man Daten, die in S3 gespeichert sind, indiziert und von einem Apache Solr-Dienst bereitgestellt bekommt, der in einem Data Discovery and Exploration-Cluster in CDP gehostet wird. Für Neugierige:DDE ist eine vorgefertigte Solr-optimierte Cluster-Bereitstellungsoption in CDP und wurde kürzlich in der Tech Preview veröffentlicht . Wir werden in diesem Blog nur AWS- und S3-Umgebungen behandeln. Azure- und ADLS-Bereitstellungsoptionen sind auch in der technischen Vorschau verfügbar, werden aber in einem zukünftigen Blogbeitrag behandelt.
Wir werden das einfachste Szenario darstellen, um den Einstieg zu erleichtern. Natürlich sind fortgeschrittenere Datenpipeline-Setups und reichhaltigere Schemas möglich, aber dies ist ein guter Ausgangspunkt für Anfänger.
Annahmen:
- Sie haben bereits ein CDP-Konto und Power-User- oder Administratorrechte für die Umgebung, in der Sie diesen Dienst einrichten möchten.
Wenn Sie kein CDP-AWS-Konto haben, wenden Sie sich bitte an Ihren bevorzugten Cloudera-Vertreter oder melden Sie sich hier für eine CDP-Testversion an. - Sie haben Umgebungen und Identitäten abgebildet und konfiguriert. Genauer gesagt, alles, was Sie brauchen, ist die Zuordnung des CDP-Benutzers zu einer AWS-Rolle, die Zugriff auf den spezifischen s3-Bucket gewährt, aus dem Sie lesen (und in den Sie schreiben) möchten.
- Sie haben bereits ein Workload-Passwort (FreeIPA) festgelegt.
- Sie haben einen DDE-Cluster ausgeführt. Weitere Informationen zur Verwendung von Vorlagen in CDP Data Hub finden Sie auch hier.
- Sie haben CLI-Zugriff auf diesen Cluster.
- Der SSH-Port ist auf AWS wie für Ihre IP-Adresse geöffnet. Sie können die öffentliche IP-Adresse für einen der Solr-Knoten in den Datahub-Clusterdetails abrufen. Erfahren Sie hier, wie Sie eine SSH-Verbindung zu einem AWS-Cluster herstellen.
- Sie haben eine Protokolldatei in einem S3-Bucket, auf den Ihr Benutzer zugreifen kann (
/sample.log in diesem Beispiel). Wenn Sie keine haben, finden Sie hier einen Link zu der von uns verwendeten.
Arbeitsablauf
Die folgenden Abschnitte führen Sie durch die Schritte, um Daten mit dem Crunch Indexer Tool zu indizieren, das im Lieferumfang von DDE enthalten ist.

Erstellen Sie eine Sammlung für Ihren Index
In HUE gibt es einen Index-Designer; Solange sich DDE jedoch in der Tech Preview befindet, wird es etwas umgebaut und wird zu diesem Zeitpunkt nicht empfohlen. Aber versuchen Sie es bitte, nachdem DDE allgemein verfügbar ist, und teilen Sie uns Ihre Meinung mit.
Im Moment können Sie Ihr Solr-Schema und Ihre Konfigurationen mit dem CLI-Tool „solrctl“ erstellen. Erstellen Sie eine Konfiguration namens „my-own-logs-config“ und eine Sammlung namens „my-own-logs“. Dazu müssen Sie CLI-Zugriff haben.
1. Stellen Sie eine SSH-Verbindung zu einem der Worker-Knoten in Ihrem Cluster her.
2. kinit als Benutzer mit der Berechtigung zum Erstellen der Sammlungskonfiguration:
kinit
3. Stellen Sie sicher, dass die Umgebungsvariable SOLR_ZK_ENSEMBLE in /etc/solr/conf/solr-env.sh gesetzt ist. Speichern Sie den Wert, da dieser in weiteren Schritten benötigt wird.
Drücken Sie die Eingabetaste und geben Sie Ihr Workload-Passwort (FreeIPA) ein.
Zum Beispiel:
cat /etc/solr/conf/solr-env.sh
Erwartete Ausgabe:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Dies wird automatisch auf Hosts mit einer Solr-Server- oder Gateway-Rolle in Cloudera Manager festgelegt.
4. Um Konfigurationsdateien für die Sammlung zu generieren, führen Sie den folgenden Befehl aus:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate ist eine der Standardvorlagen, die mit Solr in CDP geliefert werden, aber da es sich um eine Vorlage handelt, ist sie unveränderlich. Für die Zwecke dieses Arbeitsablaufs müssen Sie es kopieren und somit ein neues veränderbares erstellen (das macht die Option immutable=false). Dies bietet Ihnen eine flexible, schemalose Konfiguration. Das Erstellen eines gut gestalteten Schemas ist etwas, in das es sich zu investieren lohnt, Entwurfszeit zu investieren, es ist jedoch für die explorative Verwendung nicht erforderlich. Aus diesem Grund würde es den Rahmen dieses Blogbeitrags sprengen. In einer tatsächlichen Produktionsumgebung empfehlen wir jedoch dringend die Verwendung gut gestalteter Schemas – und wir helfen Ihnen bei Bedarf gerne weiter!
5. Erstellen Sie mit dem folgenden Befehl eine neue Sammlung:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Dadurch wird die Sammlung „my-own-logs“ basierend auf der Sammlungskonfiguration „my-own-logs-config“ auf einem Shard erstellt.
6. Um zu überprüfen, ob die Sammlung erstellt wurde, können Sie zur Solr-Admin-Benutzeroberfläche navigieren. Die Sammlung für „Meine eigenen Protokolle“ wird über das Dropdown-Menü in der linken Navigation verfügbar sein.

Indizieren Sie Ihre Daten
Hier beschreiben wir anhand eines einfachen Beispiels, wie das integrierte Crunch Indexer Tool konfiguriert und ausgeführt wird, um Daten in S3 schnell zu indizieren und über Solr in DDE bereitzustellen. Da die Sicherung des Clusters CM Auto TLS, Knox, Kerberos und Ranger verwenden kann, kann „Spark Submit“ von Aspekten abhängen, die in diesem Beitrag nicht behandelt werden.
Das Indizieren von Daten aus S3 ist genauso wie das Indizieren aus HDFS.
Führen Sie diese Schritte auf dem Yarn-Worker-Knoten aus (auf der WebUI der Verwaltungskonsole als „Yarnworker“ bezeichnet).
1. Stellen Sie als Solr-Admin-Benutzer eine SSH-Verbindung zum dedizierten Yarn-Worker-Knoten des DDE-Clusters her.
Um die IP-Adresse des Yarn-Worker-Knotens herauszufinden, klicken Sie auf Hardware auf der Cluster-Detailseite und scrollen Sie dann zum Knoten „Yarnworker“.

2. Gehen Sie zu Ihrem Ressourcenverzeichnis (oder erstellen Sie eines, falls Sie es noch nicht haben:
cd
Verwenden Sie den Home-Ordner des Admin-Benutzers als Ressourcenverzeichnis (
3. Kinit Ihres Benutzers :
kinit
Drücken Sie die Eingabetaste und geben Sie Ihr Workload-Passwort (FreeIPA) ein.
4. Führen Sie den folgenden Curl-Befehl aus und ersetzen Sie dabei
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Erstellen Sie eine Morphline-Konfigurationsdatei für das Crunch Indexer Tool, in diesem Beispiel read-log-morphline.conf. Ersetzen Sie
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Diese Morphline liest die Stack-Traces aus der angegebenen Protokolldatei, schreibt dann ein Debug-Eintragsprotokoll und lädt es in das angegebene Solr.
6. Erstellen Sie eine log4j.properties-Datei für die Protokollkonfiguration:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Überprüfen Sie, ob die Datei, die Sie lesen möchten, auf S3 existiert (falls Sie keine haben, finden Sie hier einen Link zu der Datei, die wir für dieses einfache Beispiel verwendet haben:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Führen Sie den spark-submit-Befehl aus:
Ersetzen Sie Platzhalter in
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Wenn Sie auf eine ähnliche Nachricht stoßen, können Sie sie ignorieren:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
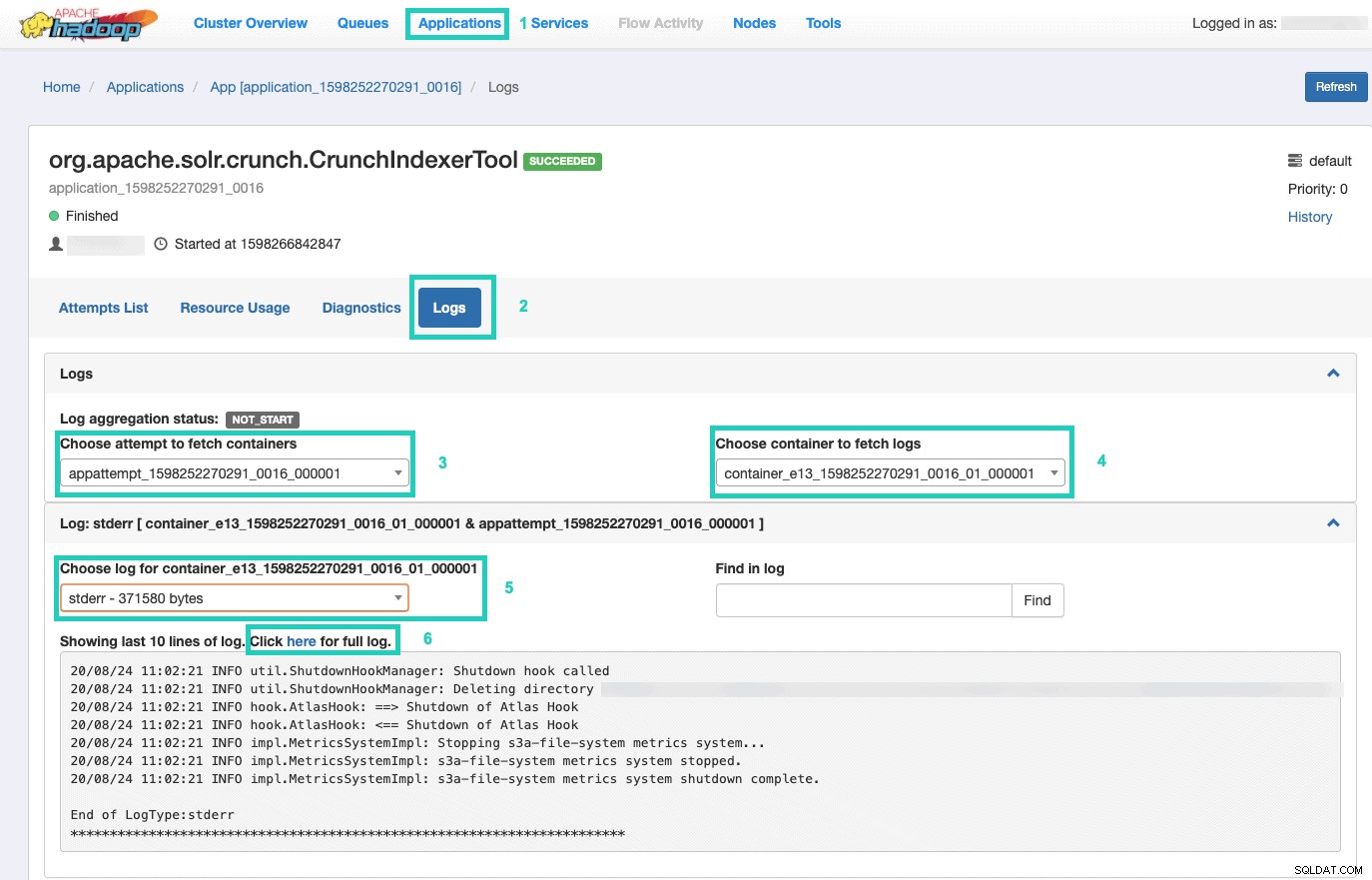
9. Um die Ausführung des Befehls zu überwachen, gehen Sie zu Resource Manager.

Wählen Sie dort die Anwendungen aus Registerkarte > Klicken Sie auf die Anwendungs-ID des Anwendungsversuchs, den Sie überwachen möchten > Wählen Sie Protokolle> Versuch zum Abrufen von Containern auswählen> Container zum Abrufen von Protokollen auswählen> Protokoll für Container auswählen> aus Wählen Sie stderr aus log> Klicken Sie auf Klicken Sie hier für das vollständige Protokoll .
Stellen Sie Ihren Index bereit
Sie haben viele Möglichkeiten, die durchsuchbaren indizierten Daten Endbenutzern bereitzustellen. Sie können Ihre eigene reichhaltige Anwendung basierend auf den reichhaltigen APIs von Solr erstellen (sehr verbreitet). Sie können Ihr bevorzugtes Drittanbieter-Tool wie Qlik, Tableau usw. über deren zertifizierte Solr-Verbindungen verbinden. Sie können das einfache Solr-Dashboard von Hue verwenden, um Prototypanwendungen zu erstellen.
Letzteres tun:
1. Gehen Sie zu Hue.

2. Navigieren Sie in der Dashboard-Ansicht zur Indexdatei Ihrer Wahl (z. B. die gerade erstellte).
3. Beginnen Sie mit dem Ziehen und Ablegen verschiedener Dashboard-Elemente und wählen Sie die Felder aus dem Index aus, um die Daten für das jeweilige Visual auszufüllen.
Ein kurzes Dashboard-Tutorial-Video aus der Vergangenheit finden Sie hier als Inspiration.
Wir werden einen tieferen Tauchgang für einen zukünftigen Blogbeitrag hinterlassen.
Zusammenfassung
Wir hoffen, dass Sie in diesem Blogbeitrag viel darüber gelernt haben, wie Sie Daten in S3 erhalten, die von Solr in einem DDE mit dem Crunch Indexer Tool indiziert werden. Natürlich gibt es viele andere Möglichkeiten (Spark in der Data Engineering-Erfahrung, Nifi in der Data Flow-Erfahrung, Kafka in der Stream Management-Erfahrung usw.), aber diese werden in zukünftigen Blog-Beiträgen behandelt. Wir hoffen, dass Sie auf Ihrem weiteren Weg zum Erstellen leistungsstarker Insight-Anwendungen mit Text und anderen unstrukturierten Daten sehr erfolgreich sind. Wenn Sie sich entscheiden, DDE in CDP auszuprobieren, teilen Sie uns bitte mit, wie alles gelaufen ist!



