In unserem vorherigen Hadoop Blogs haben wir jede Komponente von Hadoop untersucht MapReduce-Prozess im Detail. Darin werden wir das sehr interessante Thema besprechen, d. h. Nur-Karten-Jobs in Hadoop.
Zuerst nehmen wir eine kurze Einführung in die Karte und Reduzieren Phase in Hadoop MapReduce, danach werden wir diskutieren, was ein Nur-Karten-Job in Hadoop MapReduce ist.
Schließlich werden wir in diesem Tutorial auch die Vor- und Nachteile des Hadoop Map Only-Jobs besprechen.
Was ist ein reiner Hadoop-Map-Job?
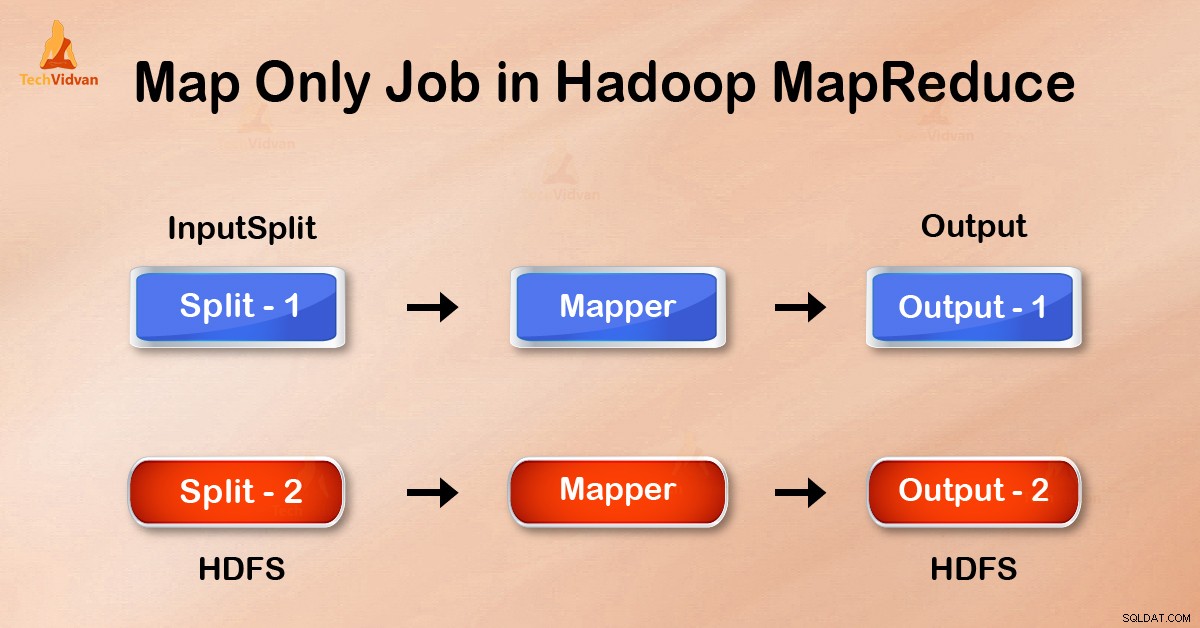
Nur-Karten-Job im Hadoop ist der Prozess, bei dem mapper erledigt alle Aufgaben. Der Reduzierer übernimmt keine Aufgabe . Die Ausgabe von Mapper ist die endgültige Ausgabe.
MapReduce ist die Datenverarbeitungsschicht von Hadoop. Es verarbeitet große strukturierte und unstrukturierte Daten, die in HDFS gespeichert sind . MapReduce verarbeitet auch eine riesige Datenmenge parallel.
Dies geschieht, indem der Job (vorgelegter Job) in eine Reihe unabhängiger Aufgaben (Sub-Job) aufgeteilt wird. In Hadoop funktioniert MapReduce, indem es die Verarbeitung in Phasen aufteilt:Map und Reduzieren .
- Karte: Es ist die erste Phase der Verarbeitung, in der wir den gesamten komplexen Logikcode spezifizieren. Es nimmt einen Datensatz und konvertiert ihn in einen anderen Datensatz. Es zerlegt jedes einzelne Element in Tupel (Schlüssel-Wert-Paare ).
- Reduzieren: Es ist die zweite Phase der Verarbeitung. Hier spezifizieren wir leichte Verarbeitung wie Aggregation/Summierung. Es nimmt die Ausgabe der Karte als Eingabe. Dann kombiniert es diese Tupel basierend auf dem Schlüssel.
Anhand dieses Beispiels für die Wortzählung können wir sagen, dass es zwei Sätze paralleler Prozesse gibt, abbilden und reduzieren. Beim Kartenprozess wird die erste Eingabe aufgeteilt, um die Arbeit wie oben gezeigt auf alle Kartenknoten zu verteilen.
Dann identifiziert Framework jedes Wort und ordnet es der Zahl 1 zu. Somit erstellt es Paare, die Tupel (Schlüssel-Wert-Paare) genannt werden.
Im ersten Mapper-Knoten werden die drei Wörter „Lion“, „Tiger“ und „The River“ übergeben. Somit werden 3 Schlüssel-Wert-Paare als Ausgabe des Knotens erzeugt. Drei verschiedene Schlüssel und Werte auf 1 gesetzt und derselbe Vorgang wird für alle Knoten wiederholt.
Dann übergibt er diese Tupel an die Reduziererknoten. Der Partitionierer führt ein Shuffling durch damit alle Tupel mit dem gleichen Schlüssel zum gleichen Knoten gehen.
Beim Reduce-Prozess passiert im Grunde eine Aggregation von Werten oder besser gesagt eine Operation mit Werten, die denselben Schlüssel haben.
Betrachten wir nun ein Szenario, in dem wir nur die Operation ausführen müssen. Wir brauchen keine Aggregation, in diesem Fall bevorzugen wir den „Nur-Karten-Job“. ’.
Im Map-Only-Job erledigt die Map alle Aufgaben mit ihrem InputSplit . Reducer funktioniert nicht. Die Ausgabe des Mappers ist die endgültige Ausgabe.
Wie vermeide ich die Reduzierphase in MapReduce?
Durch Setzen von job.setNumreduceTasks(0) In der Konfiguration in einem Treiber können wir die Reduzierungsphase vermeiden. Dadurch wird eine Anzahl von Reduzierstücken zu 0 . Somit erledigt der einzige Mapper die komplette Aufgabe.
Vorteile des reinen Map-Jobs in Hadoop
Bei der Ausführung von MapReduce-Jobs gibt es zwischen den Map- und Reduce-Phasen eine Key-, Sort- und Shuffle-Phase. Mischen – Sortieren sind für die Sortierung der Schlüssel in aufsteigender Reihenfolge verantwortlich. Gruppieren Sie dann Werte basierend auf denselben Schlüsseln. Diese Phase ist sehr teuer.
Wenn eine Reduzierungsphase nicht erforderlich ist, sollten wir sie vermeiden. Da die Vermeidung der Reduzierphase auch die Sortier- und Mischphase eliminieren würde. Daher wird dies auch eine Netzwerküberlastung verhindern.
Der Grund dafür ist, dass beim Mischen eine Ausgabe des Mappers zum Reduzieren wandert. Und wenn die Datenmenge riesig ist, müssen große Daten zum Reducer transportiert werden.
Die Ausgabe des Mappers wird auf die lokale Festplatte geschrieben, bevor sie zum Reduzieren gesendet wird. Bei reinen Kartenjobs wird diese Ausgabe jedoch direkt in HDFS geschrieben. Dies spart zusätzlich Zeit und senkt die Kosten.
Schlussfolgerung
Daher haben wir gesehen, dass der Map-only-Job die Netzwerküberlastung reduziert, indem er die Shuffle-, Sort- und Reduce-Phase vermeidet. Map allein kümmert sich um die Gesamtverarbeitung und erzeugt die Ausgabe. INDEM Sie job.setNumreduceTasks(0) verwenden dies wird erreicht.
Ich hoffe, Sie haben den Job „Nur Karte“ in Hadoop und seine Bedeutung verstanden, denn wir haben alles über den Job „Nur Karte“ in Hadoop behandelt. Aber wenn Sie Fragen haben, können Sie uns diese im Kommentarbereich mitteilen.



