Einführung
Es kann eine schwierige Aufgabe sein, herauszufinden, welche Art von Datenbankinfrastruktur Sie benötigen, um die Leistungs-, Zuverlässigkeits- und Skalierungsanforderungen Ihrer Anwendungen zu erfüllen. Die Entscheidungen, die Sie für Ihre Datenbanktopologie treffen, können sich darauf auswirken, wie Ihr gesamter Anwendungsstapel auf verschiedene Nutzungsarten reagiert und welche Ausfallszenarien er berücksichtigen kann. Aus diesem Grund ist es wichtig, Ihre Optionen zu verstehen und eine fundierte Entscheidung zu treffen, die Ihren Zielen entspricht.
Es gibt viele verschiedene Möglichkeiten, von einer einzigen Datenbank, die alle Ihre Infrastrukturanforderungen verwaltet, zu komplexeren Systemen überzugehen. Außerdem sind viele Kompromisse zu berücksichtigen.
In diesem Leitfaden stellen wir einige der gängigsten Muster für die Infrastruktur relationaler Datenbanken vor und erläutern, wie sie sich an verschiedenen Nutzungsmustern ausrichten. Wir gehen durch die Vorteile, die jede Konfiguration bietet, sowie einige der Mängel, die Sie berücksichtigen müssen. Wir werden auch über die Auswirkungen verschiedener Entscheidungen auf Ihre gesamte Betriebskomplexität sprechen. Sobald Sie fertig sind, sollten Sie in der Lage sein, eine bessere Entscheidung darüber zu treffen, welche Designs für Ihre aktuellen Anforderungen am besten geeignet sind und mit welchen Optionen Sie möglicherweise experimentieren möchten, wenn sich Ihre Anforderungen ändern.
Vertikale Skalierung
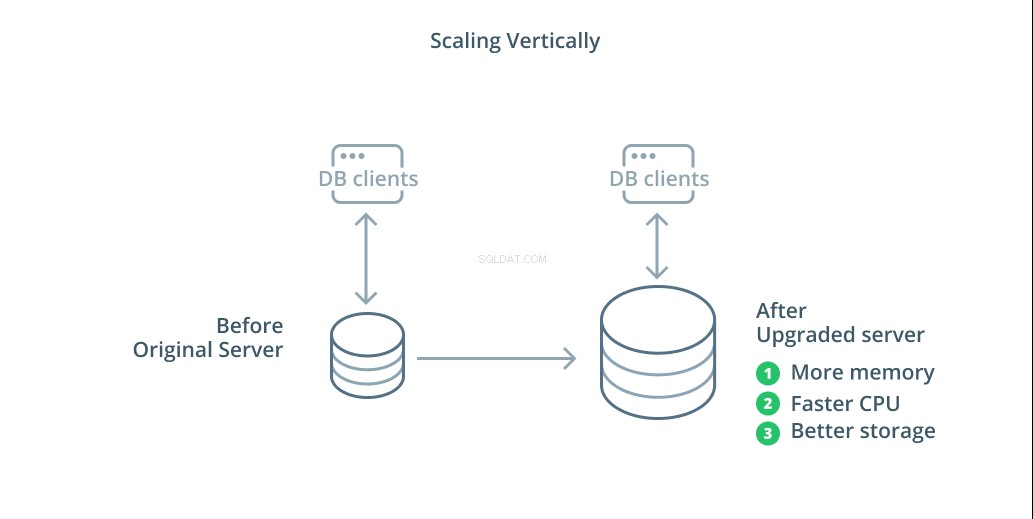
Die einfachste Möglichkeit, ein Datenbanksystem zu skalieren, ist die vertikale Skalierung. Vertikal skalieren , auch Hochskalieren genannt , bedeutet das Hinzufügen von Kapazität zum Server, der Ihre Datenbank verwaltet. Durch Erhöhen der Verarbeitungsleistung, Speicherzuweisung oder Speicherkapazität können Sie die Leistung und das Volumen erhöhen, die ein Datenbanksystem verarbeiten kann, ohne die Komplexität des Systems als Ganzes zu erhöhen.
In der Regel ist das Hochskalieren Ihrer Datenbank ein guter erster Schritt, da es die Fähigkeiten Ihrer Datenbank erweitert, ohne Ihre Infrastrukturtopologie zu beeinträchtigen. Das Hochskalieren ist normalerweise auch ziemlich einfach, da ein Rechner mit größerer Kapazität als Replikationsfolger konfiguriert werden kann, bis er synchronisiert ist, und dann ein Failover ausgelöst werden kann, um ihn zum neuen primären Server zu machen.
Das Hochskalieren hat jedoch seine Grenzen, da die Menge an Ressourcen, die vernünftigerweise einem Computer zugewiesen werden kann, begrenzt ist. Es stellt auch einen Single Point of Failure dar, wenn keine Replikationsfolger so konfiguriert sind, dass sie übernehmen, wenn Probleme auftreten. Diese Bedenken werden durch einige der anderen Skalierungsoptionen angegangen.
Befehlsabfrage-Verantwortungstrennung (CQRS) und schreibgeschützte Replikate
Die andere primäre Methode zur Skalierung Ihrer Datenbankinfrastruktur ist die horizontale Skalierung. Aufskalieren bedeutet, dass Sie, anstatt die Kapazität eines einzelnen Servers zu erhöhen, die Anzahl der Server erhöhen, die einem bestimmten Bedarf dienen. Sie erhöhen also die Kapazität, indem Sie Ihrer Infrastruktur zusätzliche Maschinen hinzufügen.
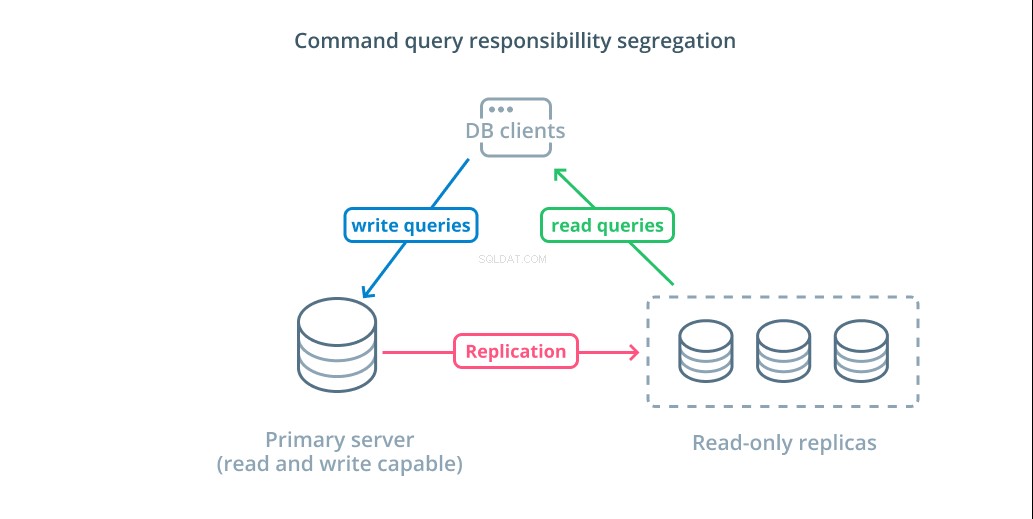
Verantwortungstrennung für Befehlsabfrage (CQRS) ist ein Begriff, der verwendet wird, um das Hinzufügen von Logik zu beschreiben, um Abfragen, die Daten verändern (Schreibabfragen), von solchen zu trennen, die dies nicht tun (Leseabfragen). Auf diese Weise können Sie diese verschiedenen Kategorien von Anfragen an verschiedene Hosts weiterleiten, um die Last zu verteilen.
Die grundlegendste Infrastruktur, um dieses Design zu nutzen, ist ein primärer Server, der Lese- und Schreibabfragen akzeptieren kann, kombiniert mit einem oder mehreren Replikatservern, die dem primären Server folgen, der Leseabfragen akzeptieren kann. Dieses Design eignet sich für leselastige Anwendungsnutzungsmuster, da Lesevorgänge von jedem der Datenbankserver verarbeitet werden können.
Darüber hinaus bietet dieses System eine gewisse Redundanz für Ihre Architektur, da das System auch dann noch funktioniert, wenn einer der Server ausfällt. Wenn ein Follower ausfällt, können Leseanforderungen an die anderen Server weitergeleitet werden. Wenn der primäre Server ausfällt, kann einer der Replikat-Follower dazu befördert werden, Schreibanfragen zu akzeptieren.
Multi-primäre Replikation
Während die Verwendung von CQRS mit schreibgeschützten Replikaten Ihnen hilft, eine höhere Anzahl von Leseanforderungen zu bewältigen, wirkt sich dies nicht wesentlich auf die Schreibleistung Ihrer Infrastruktur aus. Um die Anzahl der Schreibvorgänge zu erhöhen, die Ihre Architektur handhaben kann, müssen Sie überlegen, ob Sie ein Replikationsdesign mit mehreren primären Komponenten übernehmen können.
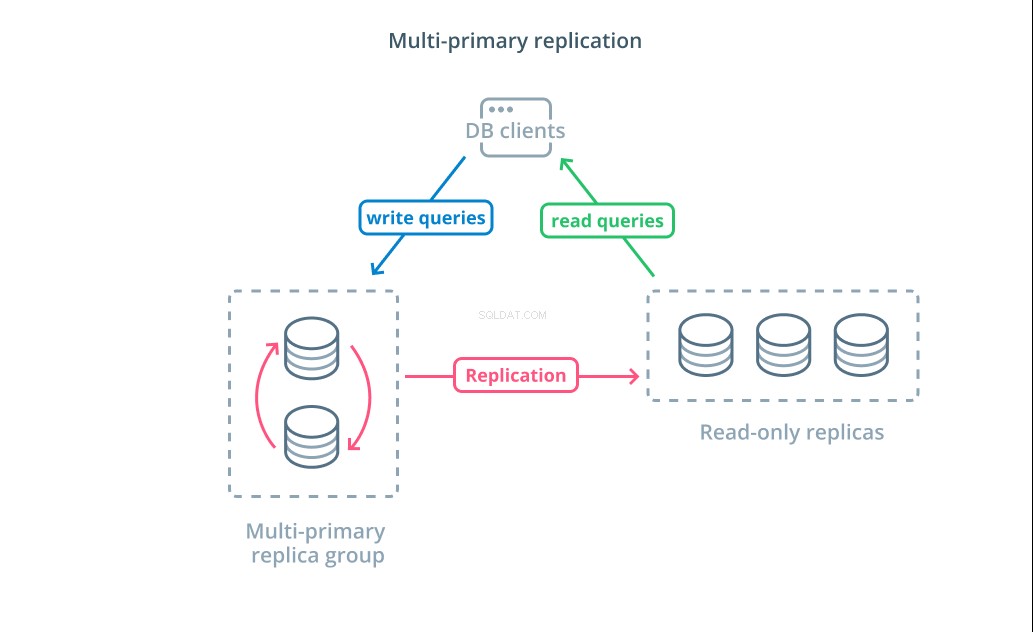
Multiprimäre Replikation ist eine Form der Replikation, bei der mehrere Server Schreibanforderungen annehmen können. Einige Systeme sind so konfiguriert, dass jeder Server Schreibanforderungen verarbeiten kann, während andere so konzipiert sind, dass eine Kerngruppe von Primärservern Schreibvorgänge mit einer größeren Anzahl von Nur-Lese-Followern verarbeitet. Unabhängig von der Implementierung erhöht die Multi-Primary-Replikation die Anzahl der Server, die für Schreibabfragen verantwortlich sind.
Während dieses Design zunächst ideal klingt, gibt es einige große Herausforderungen, die verhindern, dass dies ein weit verbreitetes Muster wird. Obwohl mehrere Server Schreibanforderungen verarbeiten können, müssen sie sich dennoch koordinieren, um Änderungen zwischen ihren Servern zu replizieren und Konflikte bei Datenänderungen zu lösen. Dies kann entweder zu langen Reaktionszeiten führen, wenn Konflikte ausgehandelt werden, oder zu inkonsistenten Daten.
Jedes System wählt seinen eigenen Ansatz, um diese Herausforderungen zu bewältigen. Dies ist eine Demonstration des CAP-Theorems – eine Aussage, die das Zusammenspiel zwischen Konsistenz, Verfügbarkeit und Partitionstoleranz in verteilten Systemen beschreibt – in Aktion. Einige Systeme bieten schwächere Konsistenzgarantien, um die Verfügbarkeit aufrechtzuerhalten, während andere Datenbanken Änderungen ablehnen, wenn ihre Peers die Transaktion zum Zeitpunkt des Schreibens nicht koordinieren können. Die Wahl des Ansatzes, der Ihren Anforderungen am besten entspricht, ist ein wichtiger Faktor bei der Entscheidung zwischen verschiedenen Implementierungen.
Abfrage-Caching lesen
Die Verwendung von schreibgeschützten Replikaten ist zwar eine Möglichkeit, die verfügbaren Datenbanken zu erhöhen, die auf Leseanforderungen reagieren können, sie verbessert jedoch nicht die grundlegende Abfrageleistung komplexer Lesevorgänge. Von einem der Server wird weiterhin erwartet, dass er die Leseoperation jedes Mal ausführt, wenn eine Anfrage gestellt wird, selbst wenn die Ergebnisse mit der vorherigen Suche identisch sind.
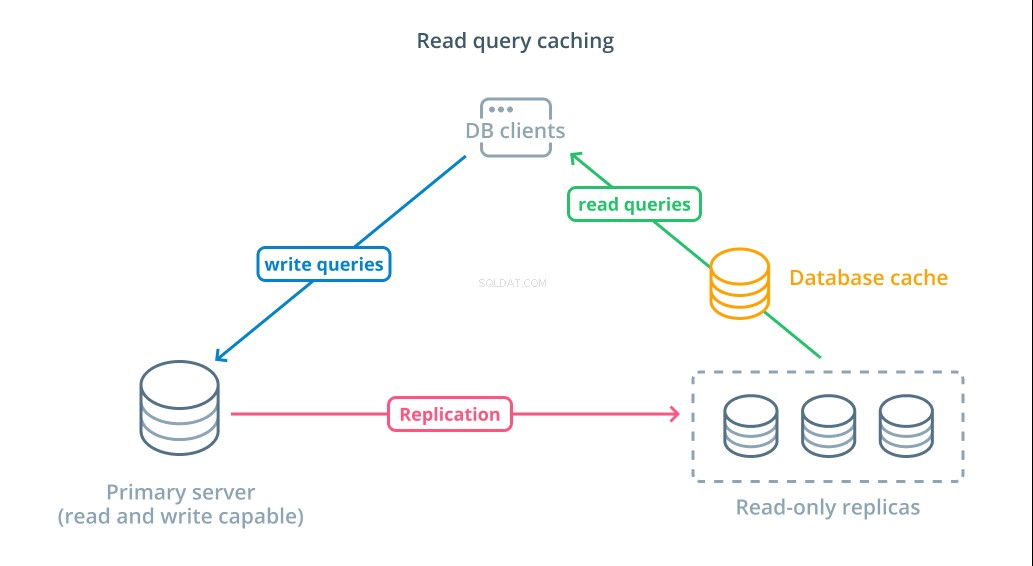
Um die Antwortzeiten zu verkürzen, ein Leseabfrage-Caching Schicht eingeführt werden kann. Das Hinzufügen eines Caches zwischen Ihren Datenbank-Clients und den Datenbanken selbst kann die Abfragezeit für häufige Anfragen erheblich verkürzen. Die Anwendung kann Leseergebnisse aus dem Cache anfordern und sie fast sofort erhalten, wenn sie verfügbar sind. Für Fälle, in denen die Ergebnisse nicht im Cache gefunden werden, werden sie aus der Datenbank selbst abgerufen und für das nächste Mal dem Cache hinzugefügt.
Das Konfigurieren des Caching auf diese Weise ist unglaublich effizient für Szenarien, in denen sich Daten wahrscheinlich nicht bei jeder Anforderung ändern. Dies ist besonders hilfreich für teure Leseabfragen, die mehrere Tabellen konsultieren und komplexe Join-Operationen beinhalten. Diese Ergebnisse können einmalig ausgeführt und dann für zukünftige Abfragen gespeichert werden.
In Fällen, in denen sich Daten schneller ändern, hilft ein Lese-Cache möglicherweise nicht annähernd so viel. Abhängig vom konfigurierten Verhalten besteht die Gefahr, dass Caches in diesen Situationen veraltete Daten zurückgeben, und es sollten durchdachte Strategien zur Cache-Invalidierung implementiert werden, um veraltete Daten aus dem Cache zu entfernen, wenn sie geändert werden.
Daten-Sharding
Bisher haben die von uns besprochenen Designs Datenbankkomponenten danach segmentiert, ob sie auf Schreibanforderungen reagieren oder nicht. Eine andere Möglichkeit, die Verantwortung aufzuteilen, besteht jedoch darin, den eigentlichen Datensatz in mehrere Teile aufzuteilen.
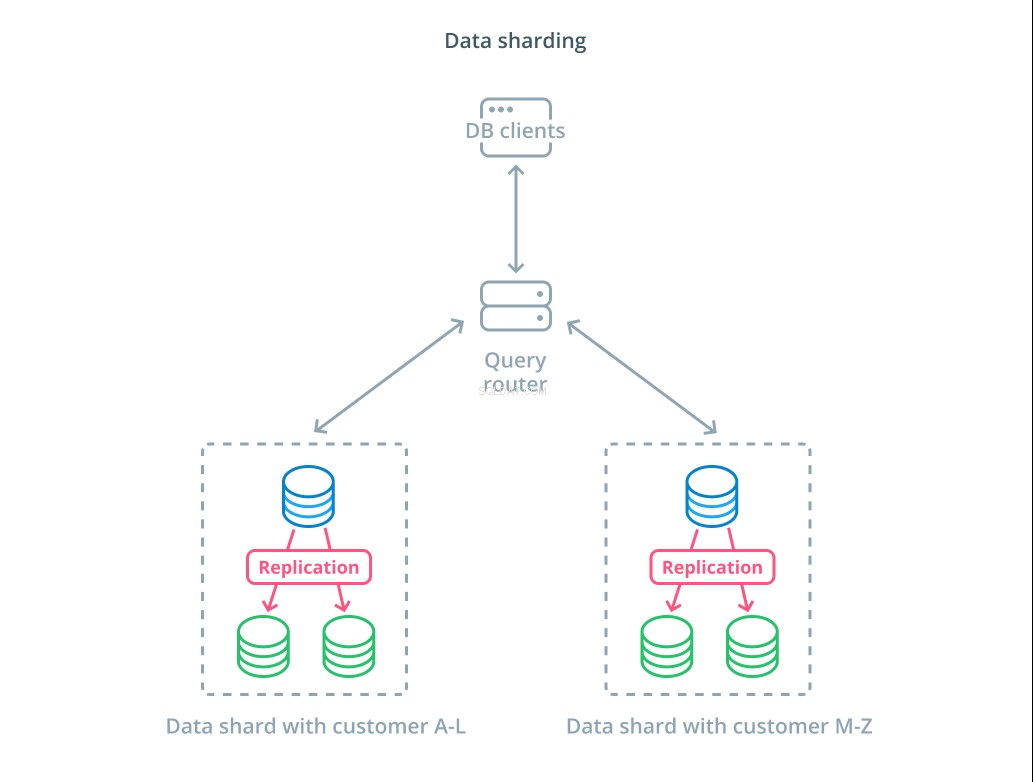
Splitter ist der Prozess der Aufteilung eines logischen Datensatzes in kleinere Teilmengen, um deren Verwaltung auf verschiedene Maschinen zu verteilen. Jeder Datenbankserver verarbeitet nur einen Teil der Daten und es wird ein Routing-Mechanismus eingeführt, der versteht, welche Maschinen für welche Daten verantwortlich sind.
In der Regel wird Sharding in Szenarien durchgeführt, in denen die gleichzeitige Bearbeitung des gesamten Datasets unnötig oder ungewöhnlich ist. Der Datensatz wird basierend auf dem Wert jedes Datensatzes für einen bestimmten Schlüssel segmentiert, der als Sharding-Schlüssel bezeichnet wird . Beispielsweise könnten Sie Daten basierend auf dem Standort von Kunden manuell fragmentieren. Sie können auch automatisch mit einem Hash-Algorithmus fragmentieren, um zu bestimmen, welche Knoten welche Schlüssel verarbeiten sollen. Dies kann Ihrem System helfen, eine unausgewogene Verteilung in Fällen zu vermeiden, in denen der Shard-Schlüsselraum ungleichmäßig verteilt ist.
Sharding bringt ziemlich viel Komplexität in Datensysteme ein und ist nicht für alle Szenarien geeignet. Vorgänge, die mit mehreren Shards interagieren, erleiden erhebliche Leistungseinbußen, da sie Ergebnisse von jedem Mitglied abrufen. Dies kann bei aggregierten Abfragen passieren oder wenn der spezifische Shard-Schlüssel nicht im Voraus bekannt ist. Darüber hinaus kann eine ungleichmäßige Verteilung von Shards auch zu Ineffizienzen und Engpässen führen, die behoben werden müssen, indem die Verteilung des gesamten Datensatzes neu ausbalanciert wird.
Dezentrale funktionale Datenverwaltung
Anstatt die Werte eines Datensatzes in mehrere Segmente aufzuteilen, ist es in vielen Fällen sinnvoller, verschiedene Datenbanken für unterschiedliche funktionale Zwecke zu verwenden. Wenn Sie zum Beispiel einen Buchhaltungs- und einen Produktservice haben, können dedizierte Datenbanken, die mit jedem Anliegen übereinstimmen, Ihnen helfen, verschiedene Komponenten unabhängig voneinander zu skalieren.
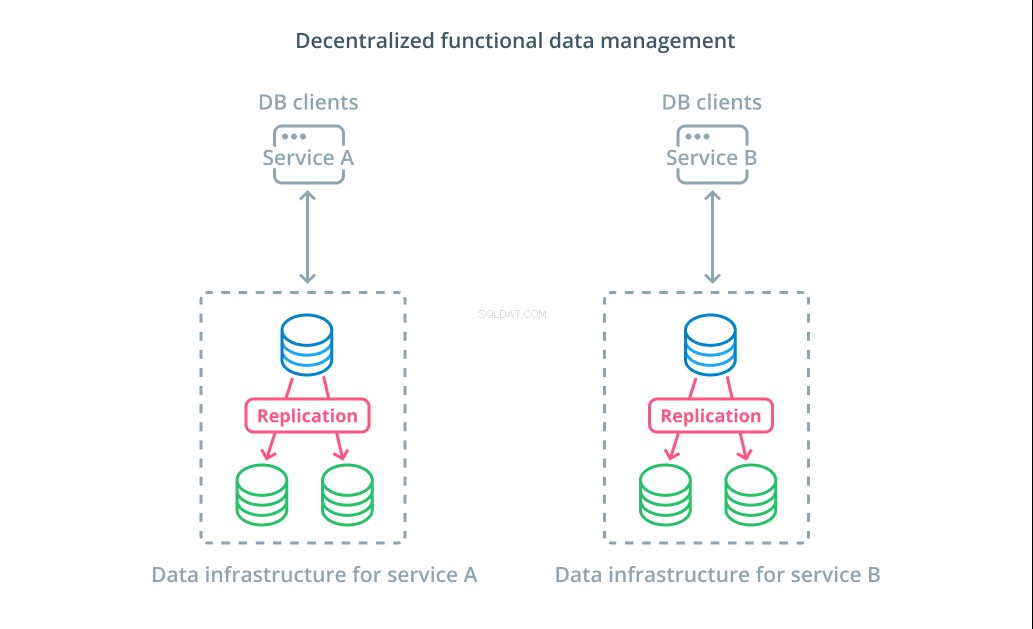
Ein funktionales Datenmanagement ermöglicht es Ihnen, Ihre Datenbankinfrastruktur aufzuteilen und jeden Teil gemäß den Anforderungen Ihrer Kunden zu verwalten. Jeder funktionale Teil kann mit jeder Strategie skaliert werden, die am sinnvollsten ist. Es ermöglicht Ihnen, das Datenbankschema zu entwerfen und an einem Ort bereitzustellen, der den Mustern eines bestimmten Anwendungsfalls am besten entspricht, anstatt zu verlangen, dass es der gesamten Organisation dient.
Für viele Organisationen hat diese Strategie wichtige Vorteile, die über die Eigenschaften der eigentlichen Systeme hinausgehen. Die Dezentralisierung der Datenverwaltung kann es kleineren Teams ermöglichen, ihre eigenen Daten zu besitzen, ohne Änderungen mit anderen Parteien zu koordinieren. Es passt gut zu der fokussierten Trennung von Anliegen, die von Microservice-orientierten Anwendungsarchitekturen gefördert wird.
Serverlose Datenbanken
Die verschiedenen Kompromisse, die Sie evaluieren müssen, und die Menge an Infrastruktur, die Sie möglicherweise für eine ordnungsgemäße Skalierung verwalten müssen, können für viele Menschen überwältigend sein. Eine Möglichkeit, diese Komplexität zu entlasten, besteht darin, Datenbankdienste zu nutzen, die die Infrastruktur verwalten und für Sie skalieren.
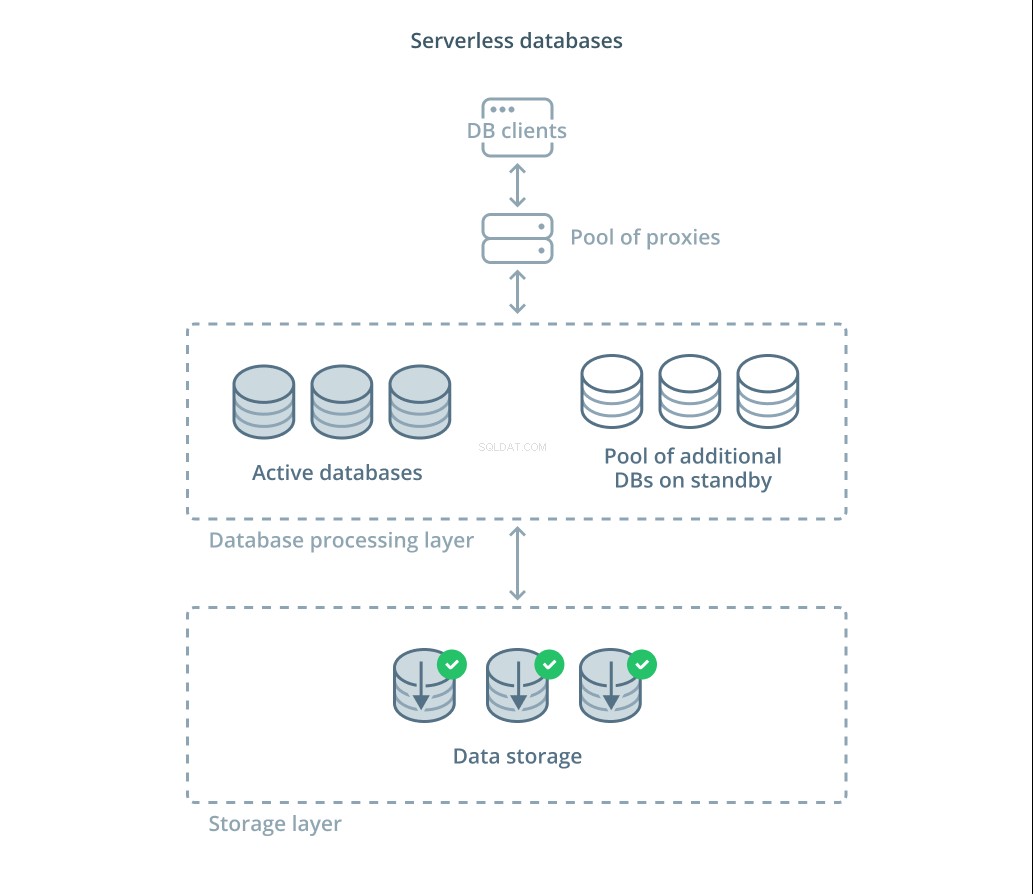
Serverlose Datenbanken sind eine Kategorie von Diensten, die die Datenspeicherung von der Datenverarbeitung entkoppeln, um Ressourcen einfach als Reaktion auf Nachfrageänderungen zu skalieren.
Eine Datenspeicherschicht ist für die Aufrechterhaltung der vom System verwalteten tatsächlichen Daten verantwortlich. Vor dieser Schicht wird eine Schicht skalierbarer Datenbankverarbeitungseinheiten bereitgestellt, um die eigentliche Abfrageverarbeitung für die Datensätze zu handhaben. Die Anzahl der zu einem bestimmten Zeitpunkt aktiven Einheiten ist direkt an die aktuelle Nutzung gebunden, sodass bei Bedarfsspitzen mehr Ressourcen zugewiesen werden und die Verarbeitungseinheiten in den Standby-Modus zurückversetzt werden, wenn sich die Situation beruhigt.
Anfragen werden über einen Routing-Proxy an die Datenbankprozessoren weitergeleitet, der weiß, wie Anfragen an die aktiven Knoten weitergeleitet werden und wann zusätzliche Ressourcen angefordert werden müssen.
Serverlose Datenbanken haben viele der gleichen Eigenschaften wie herkömmliche Datenbankdienste, die Autoscaling-Funktionen implementieren. Beide können Kapazitäten bedarfsgerecht zuweisen. Mit serverlosen Datenbanken können Sie jedoch die Speicherkosten von den Verarbeitungskosten trennen und die Verarbeitung auf null herunterskalieren, wenn sie nicht benötigt wird. Darüber hinaus können serverlose Lösungen im Vergleich zur automatischen Skalierung, die von herkömmlichen Angeboten angeboten wird, in der Regel viel schneller skaliert werden, um den Bedarf zu decken.
Obwohl serverlose Datenbanken für einige gut geeignet sind, sind sie keine Wunderwaffe. In Fällen, in denen die Datenbankprozessoren waren auf Null skaliert, kann es aufgrund von Kaltstarts erneut zu Verzögerungen in der Verarbeitung kommen. Darüber hinaus können die Churn-Through-Verbindungen zwischen den verschiedenen Komponenten in einem serverlosen Datenbankstapel zu zusätzlicher Latenz führen.
Serverlose Datenbankplattformen können auch aus betrieblicher Sicht schwierig sein. Bereitstellungen und Datenbankänderungen können schwieriger zu begründen und zu überwachen sein. Die lokale Entwicklungsumgebung kann sich aufgrund des dynamischen Zustands des Datenbanksystems auch erheblich von der Produktionsumgebung unterscheiden. Und schließlich kann Sie die Verwendung serverloser Datenbanken, wie bei jedem anderen Cloud-Dienst, möglicherweise der Gefahr einer Anbieterbindung aussetzen. Es ist wichtig, diese Kompromisse zu berücksichtigen, wenn Sie eine serverlose Plattform entwerfen.
Fazit
Es gibt viele Möglichkeiten, Ihre Datenbankinfrastruktur zu entwerfen, bereitzustellen und zu verwalten, wenn Ihre Anwendungsanforderungen immer ernster werden. Jede Lösung hat ihre Stärken und Einschränkungen, die Sie verstehen sollten, wenn Sie versuchen, eine Lösung für Ihre Umgebung zu finden.
Wenn Sie lernen, wie sich die Datenbankinfrastruktur auf die Verfügbarkeit, Leistung und Integrität Ihrer Daten auswirkt, können Sie kostspielige Fehler und Implementierungen vermeiden, die nicht die erforderlichen Garantien bieten. Wenn eines der oben genannten Designs Ihre Anforderungen nicht erfüllt, können Sie möglicherweise einige der Elemente verschiedener Ansätze kombinieren, um zusätzliche Vorteile zu erzielen.
Wenn Sie mehr über die oben behandelten allgemeinen Muster erfahren möchten, finden Sie hier einige zusätzliche Ressourcen, die Sie sich vielleicht ansehen sollten:
- Hochskalieren im Vergleich zum Hochskalieren
- Verantwortungstrennung für Befehlsabfragen
- Multiprimäre Replikation
- Leseabfragen zwischenspeichern
- Daten-Sharding
- Dezentrale Datenverwaltung
- Serverlose Datenbanken



