Datenbanken, die Geschäftsanwendungen bedienen, sollten häufig zeitliche Daten unterstützen. Angenommen, ein Vertrag mit einem Lieferanten gilt nur für eine begrenzte Zeit. Sie kann ab einem bestimmten Zeitpunkt gültig sein, oder sie kann für ein bestimmtes Zeitintervall gültig sein – von einem Startzeitpunkt bis zu einem Endzeitpunkt. Außerdem müssen Sie häufig alle Änderungen in einer oder mehreren Tabellen prüfen. Möglicherweise müssen Sie auch den Status zu einem bestimmten Zeitpunkt oder alle Änderungen an einer Tabelle in einem bestimmten Zeitraum anzeigen können. Aus Sicht der Datenintegrität müssen Sie möglicherweise viele zusätzliche zeitspezifische Einschränkungen implementieren.
Einführung von Zeitdaten
In einer Tabelle mit zeitlicher Unterstützung stellt der Header ein Prädikat mit einem mindestens einmaligen Parameter dar, der das Intervall darstellt wenn der Rest des Prädikats gültig ist – das vollständige Prädikat ist daher ein zeitgestempeltes Prädikat. Zeilen stellen Aussagen mit Zeitstempel dar, und der gültige Zeitraum der Zeile wird normalerweise mit zwei Attributen ausgedrückt:von und an , oder beginnen und Ende .
Arten von Zeittabellen
Sie haben vielleicht während des Einführungsteils bemerkt, dass es zwei Arten von zeitlichen Problemen gibt. Der erste ist die Gültigkeitsdauer der Aussage – in welchem Zeitraum war die Aussage, die eine zeitgestempelte Zeile in einer Tabelle darstellt, tatsächlich wahr. Beispielsweise war ein Vertrag mit einem Lieferanten nur von Zeitpunkt 1 bis Zeitpunkt 2 gültig. Diese Art von Gültigkeitsdauer ist für Menschen von Bedeutung, für das Unternehmen von Bedeutung. Die Gültigkeitszeit wird auch Bewerbungszeit genannt oder menschliche Zeit . Wir können mehrere gültige Zeiträume für dieselbe Entität haben. Beispielsweise könnte der oben genannte Vertrag, der von Zeitpunkt 1 bis Zeitpunkt 2 gültig war, auch von Zeitpunkt 7 bis Zeitpunkt 9 gültig sein.
Das zweite zeitliche Problem ist die Transaktionszeit . Eine Zeile für den oben erwähnten Vertrag wurde zum Zeitpunkt 1 eingefügt und war die einzige Version der Wahrheit, die der Datenbank bekannt war, bis jemand sie änderte oder sogar bis zum Ende der Zeit. Wenn die Zeile zum Zeitpunkt 2 aktualisiert wird, war die ursprüngliche Zeile von Zeitpunkt 1 bis Zeitpunkt 2 als wahr für die Datenbank bekannt. Eine neue Zeile für denselben Vorschlag wird mit einer für die Datenbank gültigen Zeit von Zeitpunkt 2 bis eingefügt das Ende der Zeit. Die Transaktionszeit wird auch als Systemzeit bezeichnet oder Datenbankzeit .
Natürlich können Sie auch sowohl anwendungs- als auch systemversionierte Tabellen implementieren. Solche Tabellen werden bitemporal genannt Tabellen.
In SQL Server 2016 erhalten Sie standardmäßig Unterstützung für die Systemzeit mit systemversionierten temporalen Tabellen . Wenn Sie Anwendungszeit implementieren müssen, müssen Sie selbst eine Lösung entwickeln.
Allens Intervalloperatoren
Die Theorie für die zeitlichen Daten in einem relationalen Modell begann sich vor mehr als dreißig Jahren zu entwickeln. Ich werde einige nützliche boolesche Operatoren und einige Operatoren vorstellen, die mit Intervallen arbeiten und ein Intervall zurückgeben. Diese Operatoren sind als Allen-Operatoren bekannt, benannt nach J. F. Allen, der einige von ihnen 1983 in einer Forschungsarbeit über zeitliche Intervalle definierte. Alle von ihnen werden immer noch als gültig und benötigt akzeptiert. Ein Datenbankverwaltungssystem könnte Ihnen helfen, mit Anwendungszeiten umzugehen, indem es diese Operatoren standardmäßig implementiert.
Lassen Sie mich zuerst die Notation vorstellen, die ich verwenden werde. Ich werde an zwei Intervallen arbeiten, die mit i1 bezeichnet werden und i2 . Der Anfangszeitpunkt des ersten Intervalls ist b1 , und das Ende ist e1 ; der Anfangszeitpunkt des zweiten Intervalls ist b2 und das Ende ist e2 . Die booleschen Operatoren von Allen sind in der folgenden Tabelle definiert.
[table id=2 /]
Zusätzlich zu den booleschen Operatoren gibt es die drei Operatoren von Allen, die Intervalle als Eingabeparameter akzeptieren und ein Intervall zurückgeben. Diese Operatoren bilden eine einfache Intervallalgebra . Beachten Sie, dass diese Operatoren denselben Namen haben wie relationale Operatoren, mit denen Sie wahrscheinlich bereits vertraut sind:Union, Intersect und Minus. Sie verhalten sich jedoch nicht genau wie ihre relationalen Gegenstücke. Im Allgemeinen sollte der Operator bei Verwendung eines der drei Intervalloperatoren NULL zurückgeben, wenn die Operation zu einer leeren Menge von Zeitpunkten oder zu einer Menge führen würde, die nicht durch ein Intervall beschrieben werden kann. Eine Vereinigung zweier Intervalle ist nur dann sinnvoll, wenn sich die Intervalle treffen oder überschneiden. Eine Überschneidung ist nur dann sinnvoll, wenn sich die Intervalle überschneiden. Der Minus-Intervall-Operator ist nur in manchen Fällen sinnvoll. Beispiel:(3:10) Minus (5:7) gibt NULL zurück, da das Ergebnis nicht durch ein Intervall beschrieben werden kann. Die folgende Tabelle fasst die Definition der Operatoren der Intervallalgebra zusammen.
[Tabellen-ID=3 /]
Leistungsproblem bei sich überschneidenden Abfragen Einer der kompliziertesten zu implementierenden Operatoren sind die Überschneidungen Operator. Abfragen, die überlappende Intervalle finden müssen, sind nicht einfach zu optimieren. Solche Abfragen sind jedoch recht häufig in temporalen Tabellen. In diesem und den nächsten beiden Artikeln zeige ich Ihnen einige Möglichkeiten, solche Abfragen zu optimieren. Aber bevor ich die Lösungen vorstelle, lassen Sie mich das Problem vorstellen.
Um das Problem zu erklären, benötige ich einige Daten. Der folgende Code zeigt ein Beispiel, wie eine Tabelle mit Gültigkeitsintervallen erstellt wird, die mit dem b ausgedrückt werden und e Spalten, in denen der Beginn und das Ende eines Intervalls als ganze Zahlen dargestellt werden. Die Tabelle wird mit Demodaten aus der WideWorldImporters.Sales.OrderLines-Tabelle gefüllt. Bitte beachten Sie, dass es mehrere Versionen von WideWorldImporters gibt Datenbank, sodass Sie möglicherweise etwas andere Ergebnisse erhalten. Ich habe die Sicherungsdatei WideWorldImporters-Standard.bak von https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 verwendet, um diese Demodatenbank auf meiner SQL Server-Instanz wiederherzustellen .
Erstellen der Demodaten
Ich habe eine Demotabelle dbo.Intervals erstellt im tempd Datenbank mit dem folgenden Code.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Bitte beachten Sie auch die Indizes erstellt. Die beiden Indizes sind optimal für Suchen am Anfang eines Intervalls oder am Ende eines Intervalls. Sie können den minimalen Beginn und das maximale Ende aller Intervalle mit dem folgenden Code überprüfen.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Sie können in den Ergebnissen sehen, dass der minimale Startzeitpunkt 1 und der maximale Endzeitpunkt 1155 ist.
Den Daten den Kontext geben
Sie werden vielleicht bemerken, dass ich den Beginn und das Ende der Zeitpunkte darstelle als ganze Zahlen. Jetzt muss ich den Intervallen einen zeitlichen Kontext geben. In diesem Fall repräsentiert ein einzelner Zeitpunkt einen Tag . Der folgende Code erstellt eine Datumssuchtabelle und bevölkert es. Beachten Sie, dass das Startdatum der 1. Juli 2014 ist.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Jetzt können Sie die Tabelle dbo.Intervals zweimal mit der Tabelle dbo.DateNums verknüpfen, um den Ganzzahlen, die den Anfang und das Ende der Intervalle darstellen, den Kontext zu geben.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Einführung in das Leistungsproblem
Das Problem bei temporären Abfragen besteht darin, dass SQL Server beim Lesen aus einer Tabelle nur einen Index verwenden und Zeilen, die keine Kandidaten für das Ergebnis sind, nur von einer Seite erfolgreich eliminieren und dann den Rest der Daten scannen kann. Beispielsweise müssen Sie alle Intervalle in der Tabelle finden, die sich mit einem bestimmten Intervall überschneiden. Denken Sie daran, dass sich zwei Intervalle überschneiden, wenn der Anfang des ersten niedriger oder gleich dem Ende des zweiten ist und der Anfang des zweiten niedriger oder gleich dem Ende des ersten ist, oder mathematisch, wenn (b1 ≤ e2) UND (b2 ≤ e1).
Die folgende Abfrage suchte nach allen Intervallen, die sich mit dem Intervall (10, 30) überschneiden. Beachten Sie, dass die zweite Bedingung (b2 ≤ e1) zum einfacheren Lesen in (e1 ≥ b2) umgekehrt wird (der Anfang und das Ende der Intervalle aus der Tabelle befinden sich immer auf der linken Seite der Bedingung). Das angegebene oder gesuchte Intervall steht am Anfang der Zeitleiste für alle Intervalle in der Tabelle.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Die Abfrage verwendete 36 logische Lesevorgänge. Wenn Sie den Ausführungsplan überprüfen, können Sie sehen, dass die Abfrage die Indexsuche im Index idx_b mit dem Suchprädikat [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) verwendet und dann gescannt hat die Zeilen und wählen Sie die resultierenden Zeilen mit dem Residualprädikat [tempdb].[dbo].[Intervals].[e]>=(10). Da sich das durchsuchte Intervall am Anfang der Zeitachse befindet, hat das Suchprädikat erfolgreich die Mehrheit der Zeilen eliminiert; nur wenige Intervalle in der Tabelle haben einen Anfangspunkt kleiner oder gleich 30.
Sie würden eine ähnlich effiziente Abfrage erhalten, wenn das durchsuchte Intervall am Ende der Zeitachse liegen würde, nur dass SQL Server den idx_e-Index für die Suche verwenden würde. Was passiert jedoch, wenn sich das gesuchte Intervall in der Mitte der Zeitleiste befindet, wie die folgende Abfrage zeigt?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Dieses Mal verwendete die Abfrage 111 logische Lesevorgänge. Bei einer größeren Tabelle wäre der Unterschied zur ersten Abfrage noch größer. Wenn Sie den Ausführungsplan überprüfen, können Sie feststellen, dass SQL Server den Index idx_e mit dem Suchprädikat [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) und [tempdb].[ verwendet hat. dbo].[Intervalle].[b]<=(590) Restprädikat. Das Suchprädikat schließt ungefähr die Hälfte der Zeilen von einer Seite aus, während die Hälfte der Zeilen von der anderen Seite gescannt und die resultierenden Zeilen mit dem Restprädikat extrahiert werden.
Erweiterte T-SQL-Lösung
Es gibt eine Lösung, die diesen Index zum Eliminieren der Zeilen von beiden Seiten des durchsuchten Intervalls verwenden würde, indem ein einziger Index verwendet wird. Die folgende Abbildung zeigt diese Logik.
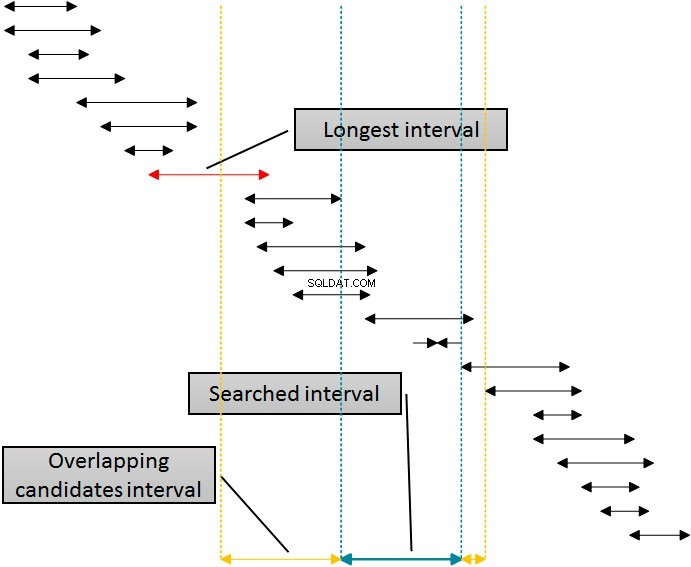
Die Intervalle in der Abbildung sind nach der unteren Grenze sortiert, die die Verwendung des idx_b-Index durch SQL Server darstellt. Das Eliminieren von Intervallen auf der rechten Seite des angegebenen (gesuchten) Intervalls ist einfach:Eliminieren Sie einfach alle Intervalle, bei denen der Anfang mindestens eine Einheit größer (weiter rechts) als das Ende des angegebenen Intervalls ist. Sie können diese Grenze in der Figur sehen, die mit der gepunkteten Linie ganz rechts gekennzeichnet ist. Die Eliminierung von links ist jedoch komplexer. Um denselben Index zu verwenden, den idx_b-Index zum Entfernen von links, muss ich den Beginn der Intervalle in der Tabelle in der WHERE-Klausel der Abfrage verwenden. Ich muss mindestens für die Länge des längsten Intervalls in der Tabelle, das in der Abbildung mit einem Callout gekennzeichnet ist, nach links vom Anfang des angegebenen (gesuchten) Intervalls weggehen. Die Intervalle, die vor der linken gelben Linie beginnen, dürfen sich nicht mit dem angegebenen (blauen) Intervall überschneiden.
Da ich bereits weiß, dass die Länge des längsten Intervalls 20 ist, kann ich ganz einfach eine erweiterte Abfrage schreiben.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Diese Abfrage ruft dieselben Zeilen wie die vorherige mit nur 20 logischen Lesevorgängen ab. Wenn Sie den Ausführungsplan überprüfen, können Sie sehen, dass idx_b verwendet wurde, mit dem Suchprädikat Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , End:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), wodurch Zeilen von beiden Seiten der Zeitachse erfolgreich eliminiert wurden, und dann das Restprädikat [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) wurde verwendet, um Zeilen aus einem sehr begrenzten Teilscan auszuwählen.
Natürlich könnte die Abbildung umgedreht werden, um die Fälle abzudecken, in denen der idx_e-Index nützlicher wäre. Mit diesem Index ist die Eliminierung von links einfach – eliminieren Sie alle Intervalle, die mindestens eine Einheit vor dem Beginn des angegebenen Intervalls enden. Diesmal ist die Eliminierung von rechts komplexer – das Ende der Intervalle in der Tabelle kann nicht weiter rechts liegen als das Ende des angegebenen Intervalls plus die maximale Länge aller Intervalle in der Tabelle.
Bitte beachten Sie, dass diese Leistung die Folge der spezifischen Daten in der Tabelle ist. Die maximale Länge eines Intervalls beträgt 20. Auf diese Weise kann SQL Server Intervalle von beiden Seiten sehr effizient eliminieren. Wenn es jedoch nur ein langes Intervall in der Tabelle geben würde, wäre der Code viel weniger effizient, da SQL Server nicht in der Lage wäre, viele Zeilen von einer Seite zu entfernen, entweder links oder rechts, je nachdem, welchen Index er verwenden würde . Wie auch immer, im wirklichen Leben variiert die Intervalllänge nicht oft, daher könnte diese Optimierungstechnik sehr nützlich sein, besonders weil sie einfach ist.
Schlussfolgerung
Bitte beachten Sie, dass dies nur eine mögliche Lösung ist. Eine komplexere Lösung, die unabhängig von der Länge des längsten Intervalls eine vorhersagbare Leistung liefert, finden Sie im Artikel Interval Queries in SQL Server von Itzik Ben-Gan (https://sqlmag.com/t-sql/ SQL-Server-Intervall-Abfragen). Allerdings gefällt mir das erweiterte T-SQL sehr gut Lösung, die ich in diesem Artikel vorgestellt habe. Die Lösung ist sehr einfach; Alles, was Sie tun müssen, ist, der WHERE-Klausel Ihrer überlappenden Abfragen zwei Prädikate hinzuzufügen. Dies ist jedoch nicht das Ende der Möglichkeiten. Bleiben Sie dran, in den nächsten beiden Artikeln werde ich Ihnen weitere Lösungen zeigen, damit Sie eine Fülle von Möglichkeiten in Ihrer Optimierungs-Toolbox haben werden.
Nützliches Tool:
dbForge Query Builder for SQL Server – ermöglicht Benutzern das schnelle und einfache Erstellen komplexer SQL-Abfragen über eine intuitive visuelle Oberfläche ohne manuelles Schreiben von Code.