SQL Server 2012 AlwaysOn-Verfügbarkeitsgruppen erfordern einen Datenbankspiegelungsendpunkt für jede SQL Server-Instanz, die ein Verfügbarkeitsgruppenreplikat und/oder eine Datenbankspiegelungssitzung hostet. Dieser SQL Server-Instanzendpunkt wird dann von einem oder mehreren Verfügbarkeitsgruppenreplikaten und/oder Datenbankspiegelungssitzungen gemeinsam genutzt und ist der Mechanismus für die Kommunikation zwischen dem primären Replikat und den zugeordneten sekundären Replikaten.
Abhängig von den Datenänderungsworkloads auf dem primären Replikat können die Anforderungen an den Nachrichtendurchsatz der Verfügbarkeitsgruppe nicht trivial sein. Diese Aktivität ist auch empfindlich gegenüber Datenverkehr von gleichzeitigen Nichtverfügbarkeitsgruppenaktivitäten. Wenn der Durchsatz aufgrund von eingeschränkter Bandbreite und gleichzeitigem Datenverkehr leidet, können Sie erwägen, den Datenverkehr der Verfügbarkeitsgruppe für jede SQL Server-Instanz, die ein Verfügbarkeitsreplikat hostet, auf einen eigenen dedizierten Netzwerkadapter zu isolieren. Dieser Beitrag beschreibt diesen Prozess und beschreibt auch kurz, was Sie in einem Szenario mit verringertem Durchsatz erwarten könnten.
Für diesen Artikel verwende ich einen virtuellen Gast-Windows Server-Failovercluster (WSFC) mit fünf Knoten. Jeder Knoten im WSFC verfügt über eine eigene eigenständige SQL Server-Instanz, die nicht gemeinsam genutzten lokalen Speicher verwendet. Jeder Knoten verfügt außerdem über einen separaten virtuellen Netzwerkadapter für die öffentliche Kommunikation, einen virtuellen Netzwerkadapter für die WSFC-Kommunikation und einen virtuellen Netzwerkadapter, den wir der Verfügbarkeitsgruppenkommunikation widmen. Für die Zwecke dieses Beitrags konzentrieren wir uns auf die Informationen, die für die dedizierten Netzwerkadapter der Verfügbarkeitsgruppe auf jedem Knoten benötigt werden:
| WSFC-Knotenname | Verfügbarkeitsgruppen-NIC-TCP/IPv4-Adressen |
|---|---|
| SQL2K12-SVR1 | 192.168.20.31 |
| SQL2K12-SVR2 | 192.168.20.32 |
| SQL2K12-SVR3 | 192.168.20.33 |
| SQL2K12-SVR4 | 192.168.20.34 |
| SQL2K12-SVR5 | 192.168.20.35 |
Das Einrichten einer Verfügbarkeitsgruppe mit einer dedizierten NIC ist fast identisch mit einem gemeinsam genutzten NIC-Prozess, nur um die Verfügbarkeitsgruppe an eine bestimmte NIC zu „binden“, muss ich zuerst die LISTENER_IP festlegen Argument im CREATE ENDPOINT Befehl unter Verwendung der oben genannten IP-Adressen für meine dedizierten NICs. Unten sehen Sie die Erstellung jedes Endpunkts über die fünf WSFC-Knoten hinweg:
:CONNECT SQL2K12-SVR1
USE [master];
GO
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = (192.168.20.31))
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES);
GO
IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
END
GO
USE [master];
GO
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [SQLSKILLSDEMOS\SQLServiceAcct];
GO
:CONNECT SQL2K12-SVR2
-- ...repeat for other 4 nodes... Nach dem Erstellen dieser Endpunkte, die der dedizierten NIC zugeordnet sind, unterscheiden sich die restlichen Schritte beim Einrichten der Verfügbarkeitsgruppentopologie nicht von denen in einem Szenario mit gemeinsam genutzter NIC.
Wenn ich nach dem Erstellen meiner Verfügbarkeitsgruppe beginne, die Datenänderungslast für die primären Replikat-Verfügbarkeitsdatenbanken zu steuern, kann ich mithilfe des Task-Managers auf der Registerkarte „Netzwerk“ schnell erkennen, dass der Kommunikationsdatenverkehr der Verfügbarkeitsgruppe auf der dedizierten NIC fließt (der erste Abschnitt ist der Durchsatz für die dedizierte Verfügbarkeitsgruppen-NIC):
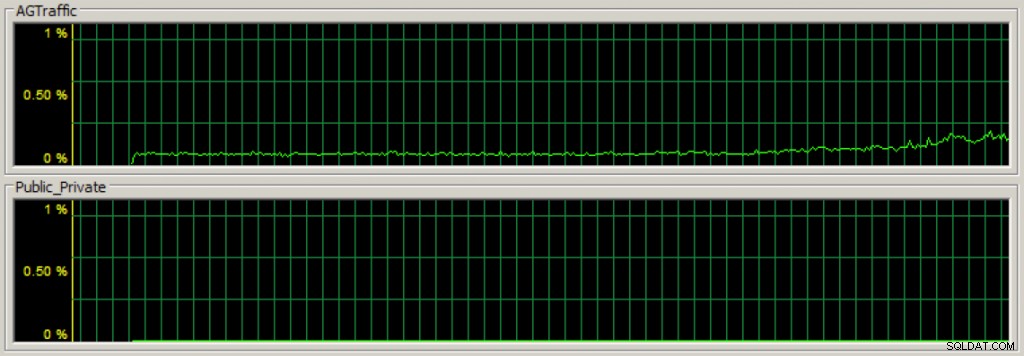
Und ich kann die Statistiken auch mit verschiedenen Leistungszählern verfolgen. In der Abbildung unten ist die Inetl[R] PRO_1000 MT-Netzwerkverbindung _2 meine dedizierte Verfügbarkeitsgruppen-NIC und hat im Vergleich zu den beiden anderen NICs den Großteil des NIC-Datenverkehrs:

Jetzt eine dedizierte NIC für den Datenverkehr der Verfügbarkeitsgruppe zu haben, kann eine Möglichkeit sein, Aktivitäten zu isolieren und theoretisch die Leistung zu verbessern, aber wenn Ihre dedizierte NIC nicht genügend Bandbreite hat, wie Sie vielleicht erwarten, wird die Leistung darunter leiden und der Zustand der Topologie der Verfügbarkeitsgruppe wird sich verschlechtern.
Beispielsweise habe ich die dedizierte Verfügbarkeitsgruppen-NIC auf dem primären Replikat auf eine ausgehende Übertragungsbandbreite von 28,8 Kbit/s geändert, um zu sehen, was passieren würde. Unnötig zu sagen, es war nicht gut. Der NIC-Durchsatz der Verfügbarkeitsgruppe ist erheblich gesunken:

Innerhalb weniger Sekunden verschlechterte sich der Zustand der verschiedenen Replikate, wobei einige der Replikate in den Status „nicht synchronisiert“ wechselten:
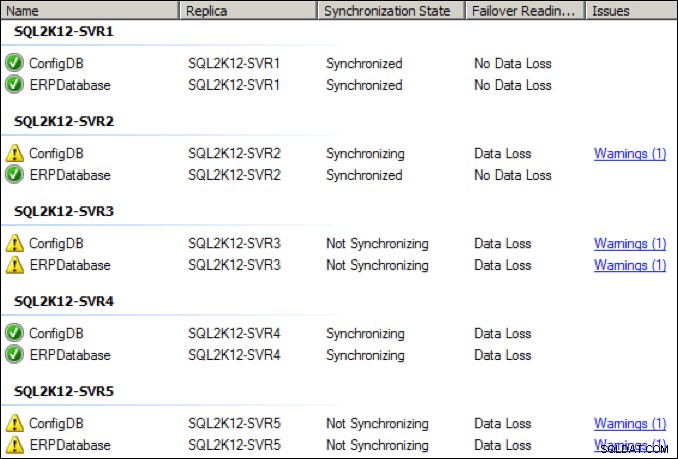
Ich habe die dedizierte NIC auf dem primären Replikat auf 64 Kbps erhöht und nach ein paar Sekunden gab es auch eine anfängliche Aufholspitze:

Während sich die Dinge verbesserten, habe ich bei dieser niedrigeren NIC-Durchsatzeinstellung regelmäßige Verbindungsabbrüche und Zustandswarnungen beobachtet:
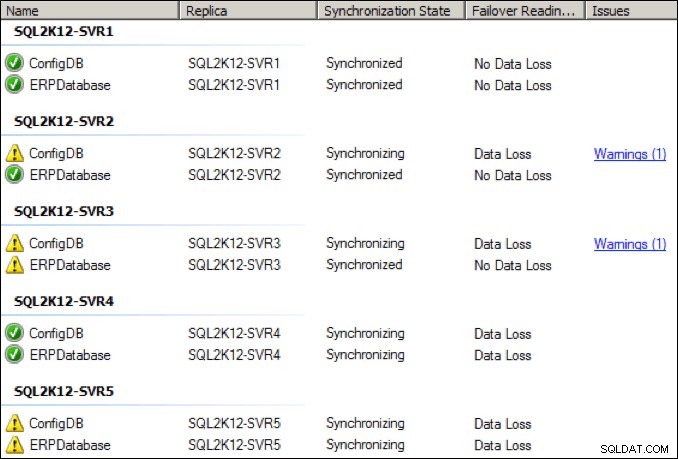
Was ist mit den zugehörigen Wartestatistiken auf dem primären Replikat?
Als auf der dedizierten NIC ausreichend Bandbreite vorhanden war und alle Verfügbarkeitsreplikate in einem fehlerfreien Zustand waren, sah ich die folgende Verteilung während meiner Datenladevorgänge über einen Zeitraum von 2 Minuten:
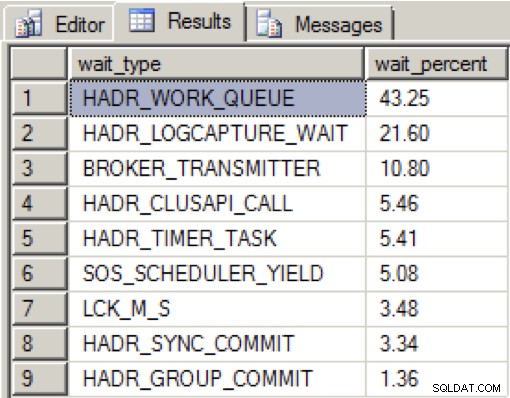
HADR_WORK_QUEUE stellt einen erwarteten Worker-Thread im Hintergrund dar, der auf neue Arbeit wartet. HADR_LOGCAPTURE_WAIT stellt eine weitere erwartete Wartezeit dar, bis neue Protokolldatensätze verfügbar werden, und wird laut Books Online erwartet, wenn der Protokollscan aufgeholt wird oder von der Festplatte liest.
Als ich den Durchsatz der NIC ausreichend reduzierte, um die Verfügbarkeitsgruppe in einen fehlerhaften Zustand zu versetzen, war die Verteilung des Wartetyps wie folgt:
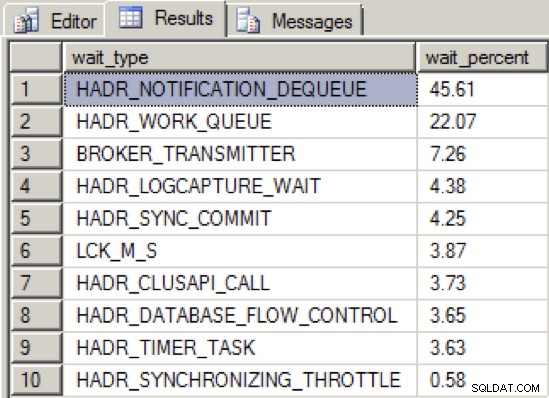
Wir sehen jetzt einen neuen Top-Wartetyp, HADR_NOTIFICATION_DEQUEUE . Dies ist einer dieser „nur für den internen Gebrauch“ Wartetypen, wie sie in Books Online definiert sind und eine Hintergrundaufgabe darstellen, die WSFC-Benachrichtigungen verarbeitet. Interessant ist, dass dieser Wartetyp nicht direkt auf ein Problem hinweist, und dennoch zeigen die Tests, dass dieser Wartetyp in Verbindung mit einem verschlechterten Messaging-Durchsatz von Verfügbarkeitsgruppen an die Spitze kommt.
Unter dem Strich kann es also von Vorteil sein, Ihre Verfügbarkeitsgruppenaktivität auf eine dedizierte NIC zu isolieren, wenn Sie einen Netzwerkdurchsatz mit ausreichender Bandbreite bereitstellen. Wenn Sie jedoch selbst bei Verwendung eines dedizierten Netzwerks keine gute Bandbreite garantieren können, leidet die Integrität Ihrer Verfügbarkeitsgruppentopologie.