Dieser Artikel ist der vierte Teil einer Serie über Tabellenausdrücke. In Teil 1 und Teil 2 habe ich die konzeptionelle Behandlung abgeleiteter Tabellen behandelt. In Teil 3 habe ich damit begonnen, Überlegungen zur Optimierung abgeleiteter Tabellen zu behandeln. Diesen Monat behandle ich weitere Aspekte der Optimierung von abgeleiteten Tabellen; insbesondere konzentriere ich mich auf das Ersetzen/Entschachteln von abgeleiteten Tabellen.
In meinen Beispielen verwende ich Beispieldatenbanken namens TSQLV5 und PerformanceV5. Das Skript, das TSQLV5 erstellt und füllt, finden Sie hier und sein ER-Diagramm hier. Das Skript, das PerformanceV5 erstellt und füllt, finden Sie hier.
Entschachtelung/Ersetzung
Das Entschachteln/Ersetzen von Tabellenausdrücken ist ein Prozess, bei dem eine Abfrage, die das Verschachteln von Tabellenausdrücken beinhaltet, durch eine Abfrage ersetzt wird, bei der die verschachtelte Logik eliminiert wird. Ich möchte betonen, dass es in der Praxis keinen eigentlichen Prozess gibt, bei dem SQL Server die ursprüngliche Abfragezeichenfolge mit der verschachtelten Logik in eine neue Abfragezeichenfolge ohne die Verschachtelung konvertiert. Was tatsächlich passiert, ist, dass der Abfrage-Parsing-Prozess einen anfänglichen Baum logischer Operatoren erzeugt, der die ursprüngliche Abfrage genau widerspiegelt. Anschließend wendet SQL Server Transformationen auf diese Abfragestruktur an, eliminiert einige der unnötigen Schritte, reduziert mehrere Schritte auf weniger Schritte und verschiebt Operatoren. Solange bestimmte Bedingungen erfüllt sind, kann SQL Server bei seinen Transformationen Dinge über die ursprünglichen Grenzen von Tabellenausdrücken hinweg verschieben – manchmal so, als würde er die verschachtelten Einheiten eliminieren. All dies, um einen optimalen Plan zu finden.
In diesem Artikel behandle ich sowohl Fälle, in denen ein solches Unnesting stattfindet, als auch Unnesting-Inhibitoren. Das heißt, wenn Sie bestimmte Abfrageelemente verwenden, verhindert dies, dass SQL Server logische Operatoren in der Abfragestruktur verschieben kann, und zwingt ihn, die Operatoren basierend auf den Grenzen der Tabellenausdrücke zu verarbeiten, die in der ursprünglichen Abfrage verwendet wurden.
Ich beginne mit einem einfachen Beispiel, bei dem abgeleitete Tabellen entschachtelt werden. Ich werde auch ein Beispiel für einen Unnesting-Inhibitor demonstrieren. Anschließend werde ich über ungewöhnliche Fälle sprechen, in denen das Aufheben der Verschachtelung unerwünscht sein kann, was entweder zu Fehlern oder Leistungseinbußen führt, und demonstriere, wie das Aufheben der Verschachtelung in diesen Fällen durch den Einsatz eines Aufhebungsverhinderers verhindert werden kann.
Die folgende Abfrage (wir nennen sie Abfrage 1) verwendet mehrere verschachtelte Schichten abgeleiteter Tabellen, wobei jeder der Tabellenausdrücke eine grundlegende Filterlogik basierend auf Konstanten anwendet:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Wie Sie sehen können, filtert jeder der Tabellenausdrücke einen Bereich von Bestelldaten, beginnend mit einem anderen Datum. SQL Server entschachtelt diese mehrschichtige Abfragelogik, was es ihm ermöglicht, die vier filternden Prädikate zu einem einzigen zusammenzuführen, das die Schnittmenge aller vier Prädikate darstellt.
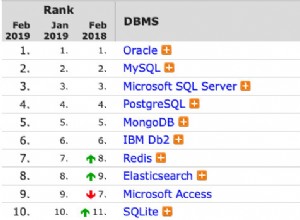
Untersuchen Sie den in Abbildung 1 gezeigten Plan für Abfrage 1.
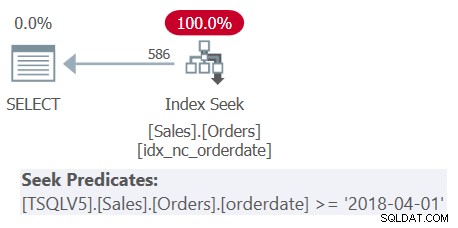 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Beachten Sie, dass alle vier filternden Prädikate zu einem einzigen Prädikat zusammengeführt wurden, das die Schnittmenge der vier darstellt. Der Plan wendet eine Suche im Index idx_nc_orderdate basierend auf dem einzelnen zusammengeführten Prädikat als Suchprädikat an. Dieser Index wird auf orderdate (explizit), orderid (implizit aufgrund des Vorhandenseins eines gruppierten Indexes auf orderid) als Indexschlüssel definiert.
Beachten Sie auch, dass, obwohl alle Tabellenausdrücke SELECT * verwenden und nur die äußerste Abfrage die beiden interessierenden Spalten projiziert:Bestelldatum und Bestell-ID, der oben genannte Index als abdeckend betrachtet wird. Wie ich in Teil 3 erläutert habe, ignoriert SQL Server zu Optimierungszwecken wie der Indexauswahl die Spalten aus den Tabellenausdrücken, die letztendlich nicht relevant sind. Denken Sie jedoch daran, dass Sie Berechtigungen zum Abfragen dieser Spalten benötigen.
Wie bereits erwähnt, versucht SQL Server, Tabellenausdrücke zu entschachteln, vermeidet jedoch die Entschachtelung, wenn er auf einen Entschachtelungsverhinderer stößt. Mit einer bestimmten Ausnahme, die ich später beschreiben werde, verhindert die Verwendung von TOP oder OFFSET FETCH das Aufheben der Verschachtelung. Der Grund dafür ist, dass der Versuch, einen Tabellenausdruck mit TOP oder OFFSET FETCH zu entschachteln, zu einer Änderung der Bedeutung der ursprünglichen Abfrage führen könnte.
Betrachten Sie als Beispiel die folgende Abfrage (wir nennen sie Abfrage 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Die Eingabeanzahl der Zeilen für den TOP-Filter ist ein Wert vom Typ BIGINT. In diesem Beispiel verwende ich den maximalen BIGINT-Wert (2^63 – 1, Berechnung in T-SQL mit SELECT POWER(2., 63) – 1). Obwohl Sie und ich wissen, dass unsere Orders-Tabelle niemals so viele Zeilen haben wird und der TOP-Filter daher wirklich bedeutungslos ist, muss SQL Server die theoretische Möglichkeit berücksichtigen, dass der Filter sinnvoll ist. Folglich hebt SQL Server die Tabellenausdrücke in dieser Abfrage nicht auf. Der Plan für Abfrage 2 ist in Abbildung 2 dargestellt.
 Abbildung 2:Plan für Abfrage 2
Abbildung 2:Plan für Abfrage 2
Die Inhibitoren zum Aufheben der Verschachtelung verhinderten, dass SQL Server die Filterprädikate zusammenführen konnte, wodurch die Form des Plans der konzeptionellen Abfrage ähnlicher wurde. Es ist jedoch interessant zu beobachten, dass SQL Server die Spalten, die letztendlich für die äußerste Abfrage nicht relevant waren, immer noch ignorierte und daher den abdeckenden Index auf orderdate, orderid.
verwenden konnteUm zu veranschaulichen, warum TOP und OFFSET-FETCH Entschachtelungsinhibitoren sind, nehmen wir eine einfache Prädikat-Pushdown-Optimierungstechnik. Prädikat-Pushdown bedeutet, dass der Optimierer ein Filterprädikat an einen früheren Punkt im Vergleich zu dem ursprünglichen Punkt verschiebt, an dem es in der logischen Abfrageverarbeitung erscheint. Angenommen, Sie haben eine Abfrage mit einem Inner Join und einem WHERE-Filter, der auf einer Spalte von einer der Seiten des Joins basiert. Hinsichtlich der logischen Abfrageverarbeitung soll der WHERE-Filter nach dem Join ausgewertet werden. Aber oft verschiebt der Optimierer das Filterprädikat auf einen Schritt vor dem Join, da der Join dann mit weniger Zeilen arbeiten muss, was normalerweise zu einem optimaleren Plan führt. Denken Sie jedoch daran, dass solche Transformationen nur in Fällen zulässig sind, in denen die Bedeutung der ursprünglichen Abfrage erhalten bleibt, in dem Sinne, dass Sie garantiert die richtige Ergebnismenge erhalten.
Betrachten Sie den folgenden Code, der eine äußere Abfrage mit einem WHERE-Filter gegen eine abgeleitete Tabelle hat, die wiederum auf einem Tabellenausdruck mit einem TOP-Filter basiert:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Diese Abfrage ist natürlich nicht deterministisch, da im Tabellenausdruck keine ORDER BY-Klausel vorhanden ist. Als ich es ausführte, griff SQL Server zufällig auf die ersten drei Zeilen mit Bestelldaten vor 2018 zu, sodass ich als Ausgabe einen leeren Satz erhielt:
orderid orderdate ----------- ---------- (0 rows affected)
Wie bereits erwähnt, verhinderte die Verwendung von TOP im Tabellenausdruck hier die Entschachtelung/Ersetzung des Tabellenausdrucks. Hätte SQL Server den Tabellenausdruck entschachtelt, hätte der Ersetzungsprozess das Äquivalent zu der folgenden Abfrage ergeben:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Diese Abfrage ist aufgrund des Fehlens der ORDER BY-Klausel ebenfalls nicht deterministisch, hat aber eindeutig eine andere Bedeutung als die ursprüngliche Abfrage. Wenn die Tabelle „Sales.Orders“ mindestens drei Bestellungen enthält, die 2018 oder später aufgegeben wurden – und das ist der Fall –, gibt diese Abfrage im Gegensatz zur ursprünglichen Abfrage zwangsläufig drei Zeilen zurück. Hier ist das Ergebnis, das ich erhalten habe, als ich diese Abfrage ausgeführt habe:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
Falls Sie die nichtdeterministische Natur der beiden obigen Abfragen verwirrt, hier ein Beispiel mit einer deterministischen Abfrage:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; Der Tabellenausdruck filtert die drei Aufträge mit den niedrigsten Auftrags-IDs. Die äußere Abfrage filtert dann aus diesen drei Bestellungen nur diejenigen heraus, die am oder nach dem 8. Juli 2017 aufgegeben wurden. Es stellt sich heraus, dass es nur eine qualifizierte Bestellung gibt. Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Angenommen, SQL Server hat den Tabellenausdruck in der ursprünglichen Abfrage entschachtelt, wobei der Ersetzungsprozess zu folgendem Abfrageäquivalent führt:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
Die Bedeutung dieser Abfrage unterscheidet sich von der ursprünglichen Abfrage. Diese Abfrage filtert zuerst die Bestellungen, die am oder nach dem 8. Juli 2017 aufgegeben wurden, und filtert dann die ersten drei unter denen mit den niedrigsten Bestell-IDs. Diese Abfrage generiert die folgende Ausgabe:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
Um zu vermeiden, dass die Bedeutung der ursprünglichen Abfrage geändert wird, wendet SQL Server hier keine Entschachtelung/Ersetzung an.
Bei den letzten beiden Beispielen handelte es sich um eine einfache Mischung aus WHERE- und TOP-Filterung, aber es könnten zusätzliche widersprüchliche Elemente entstehen, die sich aus der Aufhebung der Verschachtelung ergeben. Was ist zum Beispiel, wenn Sie unterschiedliche Sortierspezifikationen im Tabellenausdruck und in der äußeren Abfrage haben, wie im folgenden Beispiel:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; Sie stellen fest, dass die resultierende Abfrage eine andere Bedeutung als die ursprüngliche Abfrage gehabt hätte, wenn SQL Server den Tabellenausdruck entschachtelt und die beiden unterschiedlichen Sortierspezifikationen zu einer zusammengefasst hätte. Es hätte entweder die falschen Zeilen gefiltert oder die Ergebniszeilen in der falschen Präsentationsreihenfolge dargestellt. Kurz gesagt, Sie erkennen, warum es für SQL Server am sichersten ist, das Aufheben/Ersetzen von Tabellenausdrücken zu vermeiden, die auf TOP- und OFFSET-FETCH-Abfragen basieren.
Ich habe bereits erwähnt, dass es eine Ausnahme von der Regel gibt, dass die Verwendung von TOP und OFFSET-FETCH das Entschachteln verhindert. In diesem Fall verwenden Sie TOP (100) PERCENT in einem verschachtelten Tabellenausdruck mit oder ohne ORDER BY-Klausel. SQL Server erkennt, dass keine wirkliche Filterung stattfindet, und optimiert die Option aus. Hier ist ein Beispiel, das dies demonstriert:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Der TOP-Filter wird ignoriert, die Verschachtelung wird aufgehoben, und Sie erhalten denselben Plan wie zuvor für Abfrage 1 in Abbildung 1.
Wenn Sie OFFSET 0 ROWS ohne FETCH-Klausel in einem verschachtelten Tabellenausdruck verwenden, findet auch keine wirkliche Filterung statt. Theoretisch hätte SQL Server diese Option also auch optimieren und das Aufheben der Verschachtelung aktivieren können, aber zum Zeitpunkt des Schreibens dieses Artikels ist dies nicht der Fall. Hier ist ein Beispiel, das dies demonstriert:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; Sie erhalten denselben Plan wie zuvor für Abfrage 2 in Abbildung 2, der zeigt, dass keine Entschachtelung stattgefunden hat.
Weiter oben habe ich erklärt, dass der Aufhebungs-/Ersetzungsprozess nicht wirklich eine neue Abfragezeichenfolge generiert, die dann optimiert wird, sondern eher mit Transformationen zu tun hat, die SQL Server auf den Baum der logischen Operatoren anwendet. Es gibt einen Unterschied zwischen der Art und Weise, wie SQL Server eine Abfrage mit verschachtelten Tabellenausdrücken optimiert, und einer tatsächlichen logisch äquivalenten Abfrage ohne die Verschachtelung. Die Verwendung von Tabellenausdrücken wie abgeleiteten Tabellen sowie Unterabfragen verhindert eine einfache Parametrisierung. Erinnern Sie sich an Abfrage 1, die weiter oben im Artikel gezeigt wurde:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Da die Abfrage abgeleitete Tabellen verwendet, findet keine einfache Parametrisierung statt. Das heißt, SQL Server ersetzt die Konstanten nicht durch Parameter und optimiert dann die Abfrage, sondern optimiert die Abfrage mit den Konstanten. Mit auf Konstanten basierenden Prädikaten kann SQL Server die sich überschneidenden Perioden zusammenführen, was in unserem Fall zu einem einzigen Prädikat im Plan führte, wie zuvor in Abbildung 1 gezeigt.
Betrachten Sie als Nächstes die folgende Abfrage (wir nennen sie Abfrage 3), die ein logisches Äquivalent zu Abfrage 1 ist, bei der Sie die Verschachtelung jedoch selbst anwenden:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
Der Plan für diese Abfrage ist in Abbildung 3 dargestellt.
 Abbildung 3:Plan für Abfrage 3
Abbildung 3:Plan für Abfrage 3
Dieser Plan gilt als sicher für eine einfache Parametrisierung, daher werden die Konstanten durch Parameter ersetzt und die Prädikate folglich nicht zusammengeführt. Die Motivation für die Parametrisierung besteht natürlich darin, die Wahrscheinlichkeit einer Wiederverwendung von Plänen zu erhöhen, wenn ähnliche Abfragen ausgeführt werden, die sich nur in den verwendeten Konstanten unterscheiden.
Wie bereits erwähnt, verhinderte die Verwendung von abgeleiteten Tabellen in Abfrage 1 eine einfache Parametrisierung. Ebenso würde die Verwendung von Unterabfragen eine einfache Parametrisierung verhindern. Hier ist zum Beispiel unsere vorherige Abfrage 3 mit einem bedeutungslosen Prädikat basierend auf einer Unterabfrage, die der WHERE-Klausel hinzugefügt wurde:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Dieses Mal findet keine einfache Parametrisierung statt, sodass SQL Server die sich überschneidenden Perioden, die durch die Prädikate dargestellt werden, mit den Konstanten zusammenführen kann, was zu demselben Plan führt, wie er zuvor in Abbildung 1 gezeigt wurde.
Wenn Sie Abfragen mit Tabellenausdrücken haben, die Konstanten verwenden, und es für Sie wichtig ist, dass SQL Server den Code parametrisiert hat, und Sie ihn aus irgendeinem Grund nicht selbst parametrisieren können, denken Sie daran, dass Sie die Möglichkeit haben, die erzwungene Parametrisierung mit einer Planhinweisliste zu verwenden. Als Beispiel erstellt der folgende Code eine solche Planhinweisliste für Abfrage 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Führen Sie Abfrage 3 erneut aus, nachdem Sie die Planhinweisliste erstellt haben:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Sie erhalten denselben Plan wie zuvor in Abbildung 3 mit den parametrisierten Prädikaten.
Wenn Sie fertig sind, führen Sie den folgenden Code aus, um die Planhinweisliste zu löschen:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Entschachtelung verhindern
Denken Sie daran, dass SQL Server Tabellenausdrücke aus Optimierungsgründen entschachtelt. Das Ziel besteht darin, die Wahrscheinlichkeit zu erhöhen, einen Plan mit niedrigeren Kosten im Vergleich zu ohne Aufhebung der Verschachtelung zu finden. Das gilt für die meisten Transformationsregeln, die vom Optimierer angewendet werden. Es kann jedoch einige ungewöhnliche Fälle geben, in denen Sie das Aufheben der Verschachtelung verhindern möchten. Dies kann entweder der Vermeidung von Fehlern dienen (ja, in einigen ungewöhnlichen Fällen kann das Aufheben der Verschachtelung zu Fehlern führen) oder aus Leistungsgründen, um eine bestimmte Planform zu erzwingen, ähnlich wie bei der Verwendung anderer Leistungshinweise. Denken Sie daran, dass Sie eine einfache Möglichkeit haben, das Aufheben der Verschachtelung zu verhindern, indem Sie TOP mit einer sehr großen Zahl verwenden.
Beispiel zur Fehlervermeidung
Ich beginne mit einem Fall, in dem das Aufheben der Verschachtelung von Tabellenausdrücken zu Fehlern führen kann.
Betrachten Sie die folgende Abfrage (wir nennen sie Abfrage 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Dieses Beispiel ist insofern etwas konstruiert, als es einfach ist, das zweite Filterprädikat so umzuschreiben, dass es niemals zu einem Fehler führen würde (Rabatt <0,1), aber es ist ein praktisches Beispiel für mich, um meinen Standpunkt zu veranschaulichen. Rabatte sind nichtnegativ. Selbst wenn also Bestellpositionen mit einem Rabatt von Null vorhanden sind, soll die Abfrage diese herausfiltern (das erste Filterprädikat besagt, dass der Rabatt größer sein muss als der Mindestrabatt in der Tabelle). Es gibt jedoch keine Garantie dafür, dass SQL Server die Prädikate in schriftlicher Reihenfolge auswertet, sodass Sie nicht mit einem Kurzschluss rechnen können.
Untersuchen Sie den in Abbildung 4 gezeigten Plan für Abfrage 4.
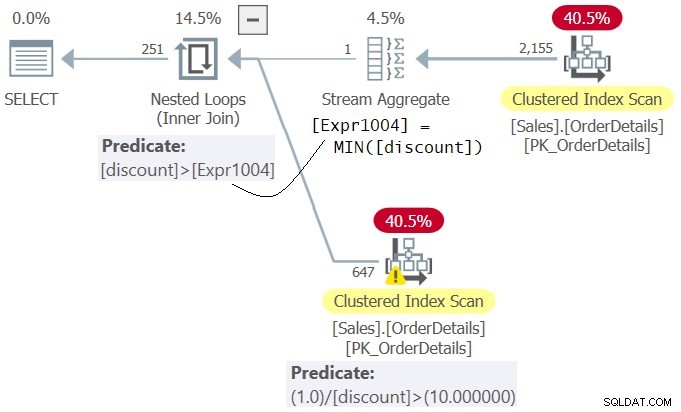 Abbildung 4:Plan für Abfrage 4
Abbildung 4:Plan für Abfrage 4
Beachten Sie, dass im Plan das Prädikat 1.0 / Rabatt> 10.0 (an zweiter Stelle in der WHERE-Klausel) vor dem Prädikat Rabatt>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Vielleicht denken Sie, dass Sie den Fehler vermeiden können, indem Sie eine abgeleitete Tabelle verwenden und die Filteraufgaben wie folgt in eine innere und eine äußere trennen:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; SQL Server wendet jedoch die Entschachtelung der abgeleiteten Tabelle an, was zu demselben Plan führt, der zuvor in Abbildung 4 gezeigt wurde, und infolgedessen schlägt auch dieser Code mit einem Fehler bei der Division durch null fehl:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Eine einfache Lösung hier ist die Einführung eines Entschachtelungs-Inhibitors, wie folgt (wir nennen diese Lösung Abfrage 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Der Plan für Abfrage 5 ist in Abbildung 5 dargestellt.
 Abbildung 5:Plan für Abfrage 5
Abbildung 5:Plan für Abfrage 5
Lassen Sie sich nicht von der Tatsache verwirren, dass der Ausdruck 1,0 / Rabatt im inneren Teil des Nested Loops-Operators erscheint, als würde er zuerst ausgewertet. Dies ist nur die Definition des Members Expr1006. Die eigentliche Auswertung des Prädikats Ausdr1006> 10,0 wird vom Operator Filter als letzter Schritt im Plan angewendet, nachdem die Zeilen mit dem Mindestrabatt zuvor vom Operator Nested Loops herausgefiltert wurden. Diese Lösung wird erfolgreich und ohne Fehler ausgeführt.
Beispiel aus Performance-Gründen
Ich werde mit einem Fall fortfahren, in dem das Aufheben der Verschachtelung von Tabellenausdrücken die Leistung beeinträchtigen kann.
Führen Sie zunächst den folgenden Code aus, um den Kontext zur PerformanceV5-Datenbank zu wechseln und STATISTICS IO und TIME zu aktivieren:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Betrachten Sie die folgende Abfrage (wir nennen sie Abfrage 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
Der Optimierer identifiziert einen unterstützenden abdeckenden Index mit shipperid und orderdate als führenden Schlüsseln. Es erstellt also einen Plan mit einem geordneten Scan des Index, gefolgt von einem reihenfolgebasierten Stream-Aggregate-Operator, wie im Plan für Abfrage 6 in Abbildung 6 gezeigt.
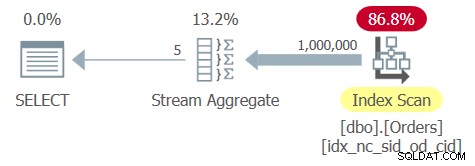 Abbildung 6:Plan für Abfrage 6
Abbildung 6:Plan für Abfrage 6
Die Orders-Tabelle hat 1.000.000 Zeilen und die Gruppierungsspalte shipperid ist sehr dicht – es gibt nur 5 verschiedene Shipper-IDs, was zu einer Dichte von 20 % führt (durchschnittlicher Prozentsatz pro eindeutigem Wert). Das Anwenden eines vollständigen Scans des Indexblatts erfordert das Lesen von einigen tausend Seiten, was auf meinem System zu einer Laufzeit von etwa einer Drittelsekunde führt. Hier sind die Leistungsstatistiken, die ich für die Ausführung dieser Abfrage erhalten habe:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
Der Indexbaum ist derzeit drei Ebenen tief.
Skalieren wir die Anzahl der Bestellungen um den Faktor 1.000 auf 1.000.000.000, aber immer noch mit nur 5 verschiedenen Versendern. Die Anzahl der Seiten im Indexblatt würde um den Faktor 1.000 wachsen, und der Indexbaum würde wahrscheinlich zu einer zusätzlichen Ebene (vier Ebenen tief) führen. Dieser Plan hat eine lineare Skalierung. Sie würden am Ende fast 4.000.000 logische Lesevorgänge und eine Laufzeit von wenigen Minuten haben.
Wenn Sie ein MIN- oder MAX-Aggregat gegen eine große Tabelle mit sehr hoher Dichte in der Gruppierungsspalte (wichtig!) und einem unterstützenden B-Baum-Index berechnen müssen, der auf der Gruppierungsspalte und der Aggregationsspalte basiert, gibt es eine viel optimalere Planform als die in Abbildung 6. Stellen Sie sich eine Planform vor, die den kleinen Satz von Versender-IDs von einem Index in der Tabelle Versender scannt und in einer Schleife für jeden Versender eine Suche gegen den unterstützenden Index für Bestellungen anwendet, um das Aggregat zu erhalten. Bei 1.000.000 Zeilen in der Tabelle würden 5 Suchvorgänge 15 Lesevorgänge beinhalten. Bei 1.000.000.000 Zeilen würden 5 Suchvorgänge 20 Lesevorgänge beinhalten. Mit einer Billion Zeilen insgesamt 25 Lesevorgänge. Eindeutig ein viel optimalerer Plan. Sie können einen solchen Plan tatsächlich erreichen, indem Sie die Shippers-Tabelle abfragen und das Aggregat mithilfe einer skalaren Aggregat-Unterabfrage für Bestellungen wie folgt erhalten (wir nennen diese Lösung Abfrage 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
Der Plan für diese Abfrage ist in Abbildung 7 dargestellt.
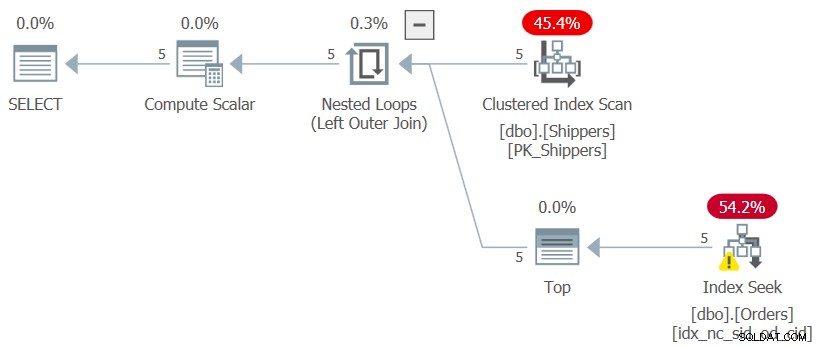 Abbildung 7:Plan für Abfrage 7
Abbildung 7:Plan für Abfrage 7
Die gewünschte Form des Plans wird erreicht, und die Leistungszahlen für die Ausführung dieser Abfrage sind erwartungsgemäß vernachlässigbar:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Solange die Gruppierungsspalte sehr dicht ist, wird die Größe der Orders-Tabelle praktisch unbedeutend.
Aber warten Sie einen Moment, bevor Sie feiern gehen. Es besteht die Anforderung, nur die Versender zu behalten, deren maximales Bestelldatum in der Bestelltabelle auf oder nach 2018 liegt. Klingt nach einer einfachen Ergänzung. Definieren Sie eine abgeleitete Tabelle basierend auf Abfrage 7 und wenden Sie den Filter wie folgt in der äußeren Abfrage an (wir nennen diese Lösung Abfrage 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Leider entschachtelt SQL Server die abgeleitete Tabellenabfrage sowie die Unterabfrage und konvertiert die Aggregationslogik in das Äquivalent der gruppierten Abfragelogik mit shipperid als Gruppierungsspalte. Und die Art und Weise, wie SQL Server eine gruppierte Abfrage optimiert, basiert auf einem einzigen Durchgang über die Eingabedaten, was zu einem Plan führt, der dem zuvor in Abbildung 6 gezeigten sehr ähnlich ist, nur mit dem zusätzlichen Filter. Der Plan für Abfrage 8 ist in Abbildung 8 dargestellt.
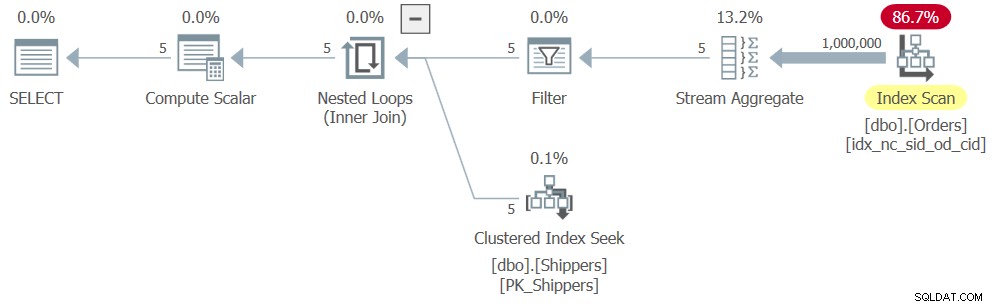 Abbildung 8:Plan für Abfrage 8
Abbildung 8:Plan für Abfrage 8
Folglich ist die Skalierung linear und die Leistungszahlen ähneln denen für Abfrage 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
Die Lösung besteht darin, einen Unnesting-Inhibitor einzuführen. Dies kann erreicht werden, indem dem Tabellenausdruck, auf dem die abgeleitete Tabelle basiert, ein TOP-Filter wie folgt hinzugefügt wird (wir nennen diese Lösung Abfrage 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Der Plan für diese Abfrage ist in Abbildung 9 dargestellt und hat die gewünschte Planform mit den Suchvorgängen:
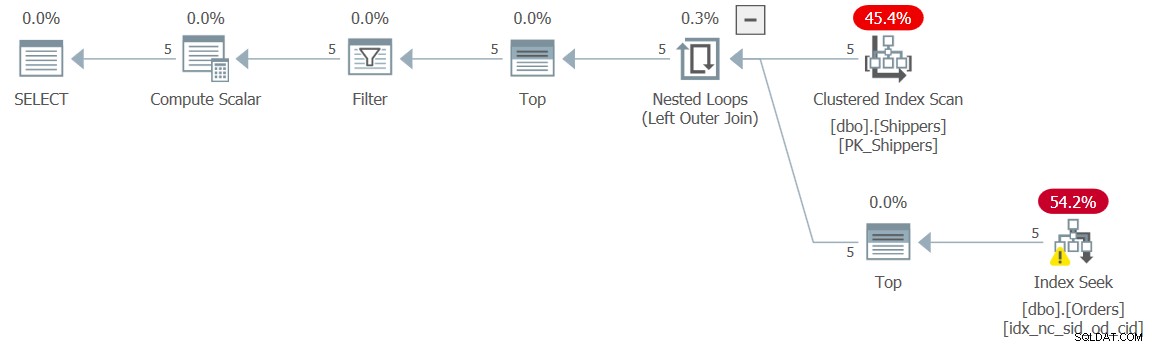 Abbildung 9:Plan für Abfrage 9
Abbildung 9:Plan für Abfrage 9
Die Leistungszahlen für diese Ausführung sind dann natürlich vernachlässigbar:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Eine weitere Möglichkeit besteht darin, das Aufheben der Verschachtelung der Unterabfrage zu verhindern, indem das MAX-Aggregat wie folgt durch einen äquivalenten TOP (1)-Filter ersetzt wird (wir nennen diese Lösung Abfrage 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Der Plan für diese Abfrage ist in Abbildung 10 dargestellt und hat wieder die gewünschte Form mit den Suchvorgängen.
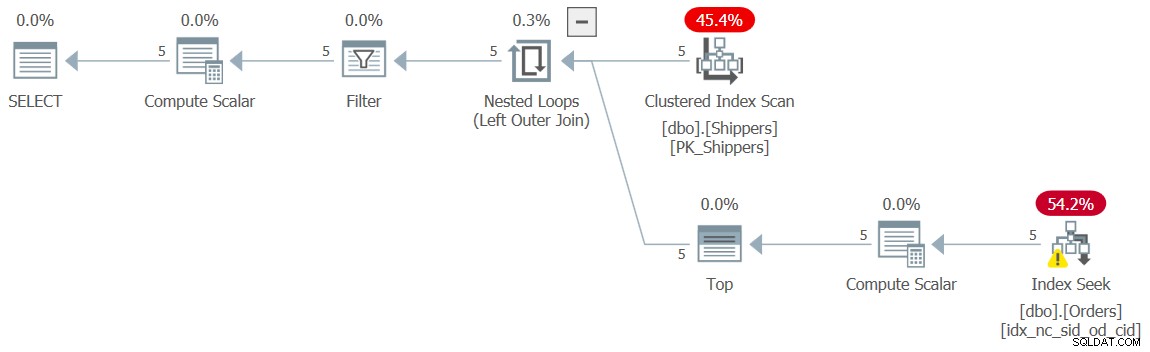 Abbildung 10:Plan für Abfrage 10
Abbildung 10:Plan für Abfrage 10
Ich habe die bekannten vernachlässigbaren Leistungszahlen für diese Ausführung:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Wenn Sie fertig sind, führen Sie den folgenden Code aus, um das Melden von Leistungsstatistiken zu beenden:
SET STATISTICS IO, TIME OFF;
Zusammenfassung
In diesem Artikel habe ich die Diskussion fortgesetzt, die ich letzten Monat über die Optimierung abgeleiteter Tabellen begonnen habe. Diesen Monat habe ich mich auf die Entschachtelung von abgeleiteten Tabellen konzentriert. Ich habe erklärt, dass das Aufheben der Verschachtelung in der Regel zu einem optimaleren Plan führt als ohne Aufheben der Verschachtelung, aber ich habe auch Beispiele behandelt, bei denen dies unerwünscht ist. Ich habe ein Beispiel gezeigt, bei dem das Aufheben der Verschachtelung zu einem Fehler führte, sowie ein Beispiel, das zu Leistungseinbußen führte. Ich habe gezeigt, wie man das Aufheben der Verschachtelung verhindert, indem man einen Aufhebungsverhinderer wie TOP anwendet.
Nächsten Monat werde ich die Erforschung benannter Tabellenausdrücke fortsetzen und den Fokus auf CTEs verlagern.