„Aber auf unserem Entwicklungsserver lief es problemlos!“
Wie oft habe ich es gehört, wenn hier und da Leistungsprobleme bei SQL-Abfragen auftraten? Ich habe es damals selbst gesagt. Ich ging davon aus, dass eine Abfrage, die in weniger als einer Sekunde ausgeführt wird, auf Produktionsservern problemlos ausgeführt werden kann. Aber ich habe mich geirrt.
Kannst du diese Erfahrung nachvollziehen? Wenn Sie heute aus irgendeinem Grund immer noch in diesem Boot sitzen, ist dieser Beitrag für Sie. Es gibt Ihnen eine bessere Metrik für die Feinabstimmung Ihrer SQL-Abfrageleistung. Wir sprechen über drei der wichtigsten Zahlen in STATISTICS IO.
Als Beispiel verwenden wir die AdventureWorks-Beispieldatenbank.
Bevor Sie mit der Ausführung von Abfragen unten beginnen, aktivieren Sie STATISTICS IO. So machen Sie es in einem Abfragefenster:
USE AdventureWorks
GO
SET STATISTICS IO ONSobald Sie eine Abfrage mit STATISTICS IO ON ausführen, werden verschiedene Meldungen angezeigt. Sie können diese auf der Registerkarte Nachrichten des Abfragefensters in SQL Server Management Studio sehen (siehe Abbildung 1):
Jetzt, da wir mit dem kurzen Intro fertig sind, lass uns tiefer graben.
1. Hohe logische Lesevorgänge
Der erste Punkt in unserer Liste ist der häufigste Übeltäter – hohe logische Lesezugriffe.
Logische Lesevorgänge sind die Anzahl der aus dem Datencache gelesenen Seiten. Eine Seite ist 8 KB groß. Der Datencache hingegen bezieht sich auf den von SQL Server verwendeten Arbeitsspeicher.
Logische Lesevorgänge sind entscheidend für die Leistungsoptimierung. Dieser Faktor definiert, wie viel ein SQL Server benötigt, um die erforderliche Ergebnismenge zu erzeugen. Daher bleibt nur zu bedenken:Je höher die logischen Lesezugriffe sind, desto länger muss der SQL-Server arbeiten. Dies bedeutet, dass Ihre Abfrage langsamer ist. Reduzieren Sie die Anzahl der logischen Lesevorgänge und steigern Sie Ihre Abfrageleistung.
Aber warum logische Lesevorgänge anstelle der verstrichenen Zeit verwenden?
- Die verstrichene Zeit hängt von anderen Dingen ab, die der Server erledigt, nicht nur von Ihrer Anfrage.
- Die verstrichene Zeit kann sich vom Entwicklungsserver zum Produktionsserver ändern. Dies passiert, wenn beide Server unterschiedliche Kapazitäten und Hardware- und Softwarekonfigurationen haben.
Wenn Sie sich auf die verstrichene Zeit verlassen, werden Sie sagen:„Aber auf unserem Entwicklungsserver lief es gut!“ früher oder später.
Warum logische statt physische Lesevorgänge verwenden?
- Physische Lesevorgänge sind die Anzahl der Seiten, die von Datenträgern in den Datencache (im Arbeitsspeicher) gelesen werden. Sobald sich die in einer Abfrage benötigten Seiten im Datencache befinden, müssen sie nicht erneut von Datenträgern gelesen werden.
- Wenn dieselbe Abfrage erneut ausgeführt wird, sind die physischen Lesevorgänge null.
Logische Lesevorgänge sind die logische Wahl für die Feinabstimmung der SQL-Abfrageleistung.
Um dies in Aktion zu sehen, fahren wir mit einem Beispiel fort.
Beispiel für logische Lesevorgänge
Angenommen, Sie müssen die Liste der Kunden abrufen, deren Bestellungen am 11. Juli 2011 versandt wurden. Sie erhalten die folgende ziemlich einfache Abfrage:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Es ist unkompliziert. Diese Abfrage hat die folgende Ausgabe:

Dann überprüfen Sie das STATISTICS IO-Ergebnis dieser Abfrage:

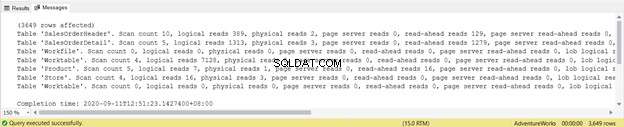
Die Ausgabe zeigt die logischen Lesevorgänge jeder der vier in der Abfrage verwendeten Tabellen. Insgesamt beträgt die Summe der logischen Lesevorgänge 729. Sie können auch physische Lesevorgänge mit einer Gesamtsumme von 21 sehen. Versuchen Sie jedoch, die Abfrage erneut auszuführen, und sie wird null sein.
Sehen Sie sich die logischen Lesevorgänge von SalesOrderHeader genauer an . Fragen Sie sich, warum es 689 logische Lesevorgänge hat? Vielleicht haben Sie daran gedacht, den Ausführungsplan der folgenden Abfrage zu überprüfen:
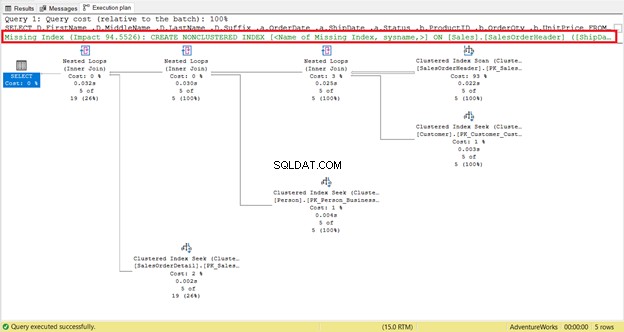
Zum einen gab es einen Index-Scan, der in SalesOrderHeader stattfand mit 93% Kosten. Was könnte passieren? Angenommen, Sie haben seine Eigenschaften überprüft:
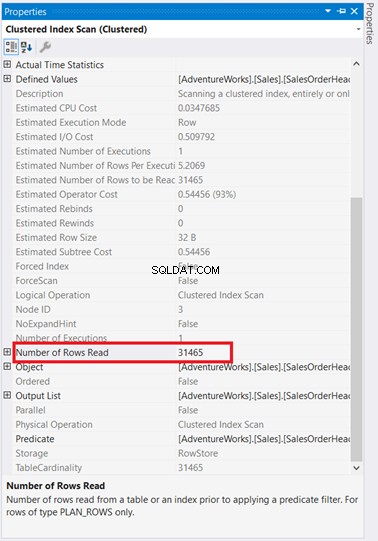
Wow! 31.465 gelesene Zeilen für nur 5 zurückgegebene Zeilen? Es ist absurd!
Verringern der Anzahl logischer Lesevorgänge
Es ist nicht so schwer, diese 31.465 gelesenen Zeilen zu verringern. SQL Server hat uns bereits einen Hinweis gegeben. Gehen Sie wie folgt vor:
SCHRITT 1:Folgen Sie der Empfehlung von SQL Server und fügen Sie den fehlenden Index hinzu
Ist Ihnen die fehlende Indexempfehlung im Ausführungsplan aufgefallen (Abbildung 4)? Wird das Problem dadurch behoben?
Es gibt eine Möglichkeit, das herauszufinden:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Führen Sie die Abfrage erneut aus und sehen Sie sich die Änderungen in den logischen Lesevorgängen von STATISTICS IO an.

Wie Sie in STATISTICS IO (Abbildung 6) sehen können, gibt es einen enormen Rückgang der logischen Lesevorgänge von 689 auf 17. Die neuen logischen Lesevorgänge insgesamt betragen 57, was eine deutliche Verbesserung gegenüber 729 logischen Lesevorgängen darstellt. Aber um sicherzugehen, sehen wir uns den Ausführungsplan noch einmal an.
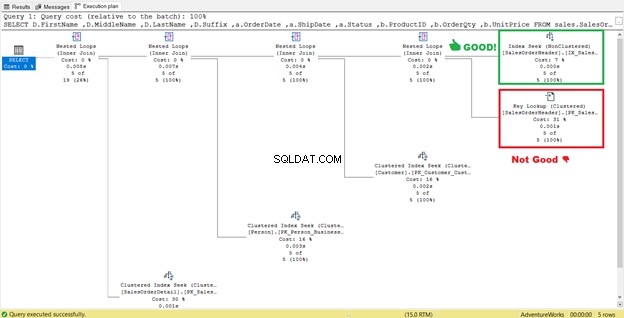
Es sieht so aus, als gäbe es eine Verbesserung des Plans, die zu weniger logischen Lesevorgängen führt. Der Index-Scan ist jetzt ein Index-Suchvorgang. SQL Server muss nicht mehr Zeile für Zeile prüfen, um die Datensätze mit dem Shipdate=’07/11/2011′ abzurufen . Aber etwas lauert immer noch in diesem Plan, und es ist nicht richtig.
Sie benötigen Schritt 2.
SCHRITT 2:Ändern Sie den Index und fügen Sie ihn den enthaltenen Spalten hinzu:Bestelldatum, Status und Kunden-ID
Sehen Sie diesen Key Lookup-Operator im Ausführungsplan (Abbildung 7)? Das bedeutet, dass der erstellte Non-Clustered-Index nicht ausreicht – der Abfrageprozessor muss den Clustered-Index erneut verwenden.
Lassen Sie uns seine Eigenschaften überprüfen.
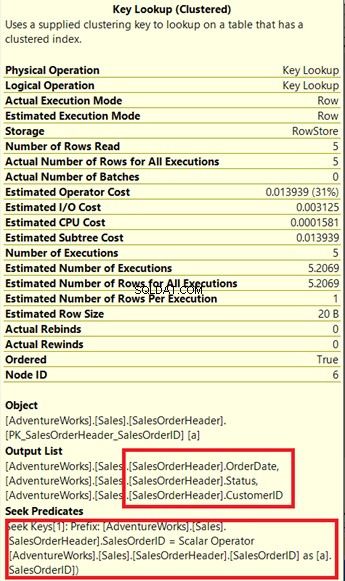
Beachten Sie das beigefügte Feld unter der Ausgabeliste . Es kommt vor, dass wir OrderDate benötigen , Status und Kunden-ID in der Ergebnismenge. Um diese Werte zu erhalten, verwendete der Abfrageprozessor den gruppierten Index (siehe Suchprädikate ), um zum Tisch zu gelangen.
Wir müssen diese Schlüsselsuche entfernen. Die Lösung besteht darin, das Bestelldatum einzubeziehen , Status und Kunden-ID Spalten in den zuvor erstellten Index.
- Klicken Sie mit der rechten Maustaste auf IX_SalesOrderHeader_ShipDate in SSMS.
- Wählen Sie Eigenschaften .
- Klicken Sie auf die Eingeschlossenen Spalten Registerkarte.
- Fügen Sie Bestelldatum hinzu , Status und Kunden-ID .
- Klicken Sie auf OK .
Führen Sie nach der Neuerstellung des Index die Abfrage erneut aus. Wird dadurch Key Lookup entfernt und logische Lesevorgänge reduzieren?

Es funktionierte! Von 17 logischen Lesevorgängen auf 2 (Abbildung 9).
Und die Schlüsselsuche ?
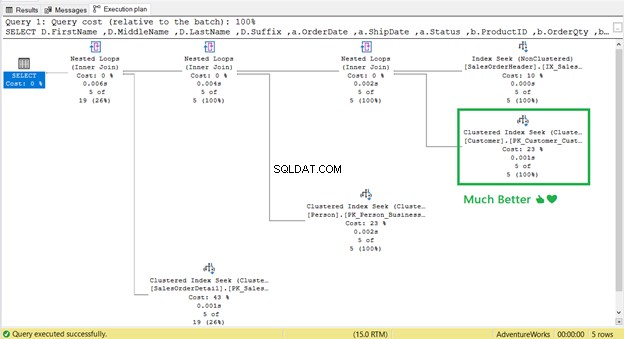
Es ist weg! Clustered-Index-Suche hat die Schlüsselsuche ersetzt.
Der Imbiss
Also, was haben wir gelernt?
Eine der wichtigsten Möglichkeiten, logische Lesevorgänge zu reduzieren und die SQL-Abfrageleistung zu verbessern, besteht darin, einen geeigneten Index zu erstellen. Aber da ist ein Fang. In unserem Beispiel wurden die logischen Lesevorgänge reduziert. Manchmal wird das Gegenteil richtig sein. Es kann sich auch auf die Leistung anderer verwandter Abfragen auswirken.
Überprüfen Sie daher nach dem Erstellen des Index immer die STATISTICS IO und den Ausführungsplan.
2. Logische Lesevorgänge mit hohem Lob
Es ist ziemlich dasselbe wie Punkt #1, aber es wird sich mit den Datentypen Text befassen , ntext , Bild , varchar (maximal ), nvarchar (maximal ), varbinary (maximal ) oder columnstore Indexseiten.
Sehen wir uns ein Beispiel an:Generieren von logischen Lob-Lesezugriffen.
Beispiel für logische Lob-Lesevorgänge
Angenommen, Sie möchten ein Produkt mit Preis, Farbe, Vorschaubild und einem größeren Bild auf einer Webseite anzeigen. Daher erhalten Sie eine anfängliche Abfrage wie unten gezeigt:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorDann führen Sie es aus und sehen die Ausgabe wie die folgende:

Da Sie so ein leistungsorientierter Typ (oder Mädel) sind, überprüfen Sie sofort die STATISTIK IO. Hier ist es:

Es fühlt sich an wie Dreck in den Augen. Logische 665-Lob-Lesevorgänge? Das können Sie nicht akzeptieren. Ganz zu schweigen von jeweils 194 logischen Lesevorgängen von ProductPhoto und ProductProductPhoto Tische. Sie denken tatsächlich, dass diese Abfrage einige Änderungen benötigt.
Logische Lob-Lesevorgänge reduzieren
Die vorherige Abfrage hatte 97 Zeilen zurückgegeben. Alle 97 Fahrräder. Denken Sie, dass dies gut auf einer Webseite angezeigt werden kann?
Ein Index kann helfen, aber warum nicht zuerst die Abfrage vereinfachen? Auf diese Weise können Sie auswählen, was SQL Server zurückgibt. Sie können die logischen Lob-Lesezugriffe reduzieren.
- Fügen Sie einen Filter für die Produktunterkategorie hinzu und lassen Sie den Kunden auswählen. Fügen Sie dies dann in die WHERE-Klausel ein.
- Entfernen Sie die Produktunterkategorie Spalte, da Sie einen Filter für die Produktunterkategorie hinzufügen werden.
- Entfernen Sie das GroßeFoto Säule. Fragen Sie dies ab, wenn der Benutzer ein bestimmtes Produkt auswählt.
- Verwenden Sie Paging. Der Kunde kann nicht alle 97 Fahrräder auf einmal sehen.
Basierend auf diesen oben beschriebenen Operationen ändern wir die Abfrage wie folgt:
- Entfernen Sie Produktunterkategorie und LargePhoto Spalten aus der Ergebnismenge.
- Verwenden Sie OFFSET und FETCH, um Paging in der Abfrage unterzubringen. Fragen Sie nur 10 Produkte gleichzeitig ab.
- Fügen Sie ProductSubcategoryID hinzu in der WHERE-Klausel basierend auf der Auswahl des Kunden.
- Entfernen Sie die Produktunterkategorie Spalte in der ORDER BY-Klausel.
Die Abfrage sieht nun ähnlich aus:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Werden sich die logischen Lob-Lesevorgänge mit den vorgenommenen Änderungen verbessern? STATISTIK IO meldet jetzt:

Produktfoto Die Tabelle hat jetzt 0 logische Lob-Lesezugriffe – von 665 logischen Lob-Lesezugriffen auf keine. Das ist eine Verbesserung.
Imbiss
Eine der Möglichkeiten, logische Lob-Lesevorgänge zu reduzieren, besteht darin, die Abfrage neu zu schreiben, um sie zu vereinfachen.
Entfernen Sie nicht benötigte Spalten und reduzieren Sie die zurückgegebenen Zeilen auf das am wenigsten Erforderliche. Verwenden Sie bei Bedarf OFFSET und FETCH zum Paging.
Um sicherzustellen, dass die Abfrageänderungen zu verbesserten logischen Lob-Lesevorgängen und der SQL-Abfrageleistung führen, überprüfen Sie immer STATISTICS IO.
3. Hohe logische Lesevorgänge für Arbeitstabelle/Arbeitsdatei
Schließlich sind es logische Lesevorgänge von Worktable und Arbeitsdatei . Aber was sind das für Tische? Warum werden sie angezeigt, obwohl Sie sie nicht in Ihrer Abfrage verwenden?
Worktable haben und Arbeitsdatei Das Erscheinen im STATISTICS IO bedeutet, dass SQL Server viel mehr Arbeit benötigt, um die gewünschten Ergebnisse zu erzielen. Es greift auf temporäre Tabellen in tempdb zurück , nämlich Worktables und Arbeitsdateien . Es ist nicht unbedingt schädlich, sie in der STATISTICS IO-Ausgabe zu haben, solange die logischen Lesevorgänge null sind und dem Server keine Probleme bereiten.
Diese Tabellen können erscheinen, wenn unter anderem ORDER BY, GROUP BY, CROSS JOIN oder DISTINCT vorhanden sind.
Beispiel für logische Lesevorgänge von Arbeitstabellen/Arbeitsdateien
Angenommen, Sie müssen alle Geschäfte ohne Verkauf bestimmter Produkte abfragen.
Sie kommen zunächst auf Folgendes:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDDiese Abfrage hat 3649 Zeilen zurückgegeben:
Sehen wir uns an, was das STATISTICS IO sagt:

Beachten Sie, dass der Arbeitstisch logische Lesevorgänge sind 7128. Die logischen Lesevorgänge insgesamt sind 8853. Wenn Sie den Ausführungsplan überprüfen, werden Sie viele Parallelismen, Hash-Matches, Spools und Index-Scans sehen.
Logische Lesevorgänge für Arbeitstabelle/Arbeitsdatei reduzieren
Ich konnte keine einzige SELECT-Anweisung mit einem zufriedenstellenden Ergebnis konstruieren. Daher besteht die einzige Möglichkeit darin, die SELECT-Anweisung in mehrere Abfragen aufzuteilen. Siehe unten:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsEs ist mehrere Zeilen länger und verwendet temporäre Tabellen. Sehen wir uns nun an, was der STATISTICS IO enthüllt:
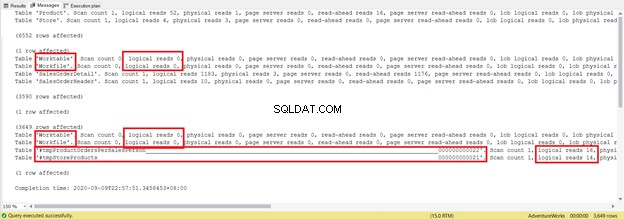
Versuchen Sie, sich nicht auf diese statistische Berichtslänge zu konzentrieren – es ist nur frustrierend. Fügen Sie stattdessen logische Lesevorgänge aus jeder Tabelle hinzu.
Für insgesamt 1279 ist dies ein erheblicher Rückgang, da es 8853 logische Lesevorgänge von der einzelnen SELECT-Anweisung waren.
Wir haben den temporären Tabellen keinen Index hinzugefügt. Sie benötigen möglicherweise einen, wenn viel mehr Datensätze zu SalesOrderHeader hinzugefügt werden und SalesOrderDetail . Aber Sie verstehen, worauf es ankommt.
Imbiss
Manchmal erscheint 1 SELECT-Anweisung gut. Hinter den Kulissen ist jedoch das Gegenteil der Fall. Arbeitstische und Arbeitsdateien bei hohen logischen Lesevorgängen verzögert sich Ihre SQL-Abfrageleistung.
Wenn Ihnen keine andere Möglichkeit einfällt, die Abfrage zu rekonstruieren, und die Indizes nutzlos sind, versuchen Sie es mit dem „Teile und herrsche“-Ansatz. Die Worktables und Arbeitsdateien wird möglicherweise weiterhin auf der Registerkarte „Nachricht“ von SSMS angezeigt, aber die logischen Lesevorgänge sind null. Daher wird das Gesamtergebnis weniger logische Lesevorgänge sein.
Das Endergebnis in SQL-Abfrageleistung und STATISTIK-E/A
Was hat es mit diesen 3 fiesen E/A-Statistiken auf sich?
Der Unterschied in der SQL-Abfrageleistung wird wie Tag und Nacht sein, wenn Sie auf diese Zahlen achten und sie senken. Wir haben nur einige Möglichkeiten vorgestellt, logische Lesevorgänge zu reduzieren, wie zum Beispiel:
- Erstellen geeigneter Indizes;
- Vereinfachen von Abfragen – Entfernen unnötiger Spalten und Minimieren der Ergebnismenge;
- eine Abfrage in mehrere Abfragen aufteilen.
Es gibt mehr wie das Aktualisieren von Statistiken, das Defragmentieren von Indizes und das Setzen des richtigen FILLFACTOR. Können Sie im Kommentarbereich mehr dazu hinzufügen?
Wenn Ihnen dieser Beitrag gefällt, teilen Sie ihn bitte mit Ihren bevorzugten sozialen Medien.