Einführung
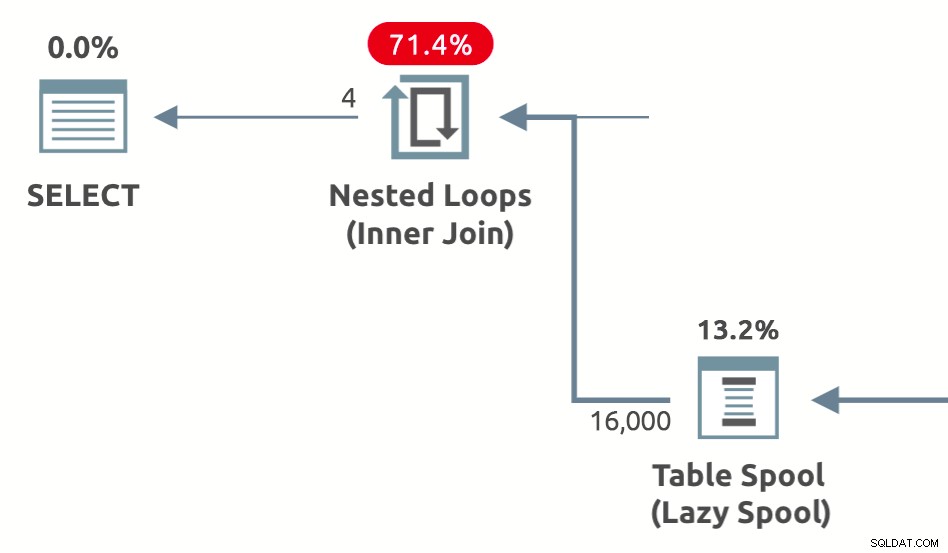
Leistungsspulen sind Lazy Spools, die vom Optimierer hinzugefügt werden, um die geschätzten Kosten der Innenseite zu reduzieren von nested loop joins . Es gibt sie in drei Varianten:Lazy Table Spool , Lazy Index Spool , und Lazy Row Count Spool . Ein Beispiel für eine Planform, die eine Lazy-Table-Performance-Spule zeigt, ist unten:
Die Fragen, die ich in diesem Artikel beantworten möchte, lauten, warum, wie und wann der Abfrageoptimierer jeden Typ von Performance-Spool einführt.
Kurz bevor wir anfangen, möchte ich einen wichtigen Punkt hervorheben:Es gibt zwei unterschiedliche Arten von Joins mit verschachtelten Schleifen in Ausführungsplänen. Ich werde mich auf die Sorte mit äußeren Referenzen beziehen als Bewerbung , und den Typ mit einem Join-Prädikat auf dem Join-Operator selbst als nested loop join . Um es deutlich zu machen, dieser Unterschied bezieht sich auf Ausführungsplanoperatoren , nicht die T-SQL-Abfragesyntax. Weitere Einzelheiten finden Sie in meinem verlinkten Artikel.
Leistungsspulen
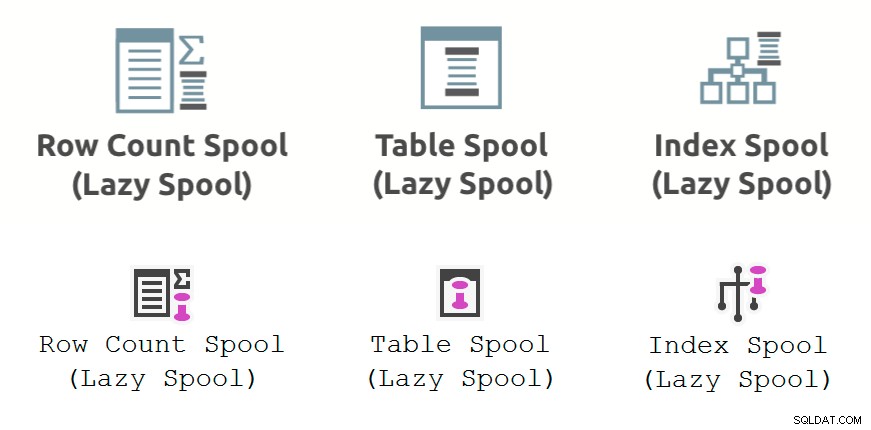
Das Bild unten zeigt die Leistungsspule Ausführungsplanoperatoren wie im Plan Explorer (obere Reihe) und SSMS 18.3 (untere Reihe) angezeigt:
Allgemeine Bemerkungen
Alle Leistungsspulen sind faul . Die Arbeitstabelle der Spule wird nach und nach zeilenweise gefüllt, während Zeilen durch die Spule strömen. (Im Gegensatz dazu verbrauchen eifrige Spools alle Eingaben von ihrem untergeordneten Operator, bevor sie Zeilen an ihren übergeordneten Operator zurückgeben).
Leistungsspulen erscheinen immer auf der Innenseite (die untere Eingabe in grafischen Ausführungsplänen) eines Join- oder Apply-Operators für verschachtelte Schleifen. Die allgemeine Idee besteht darin, Ergebnisse zwischenzuspeichern und wiederzugeben, wobei wiederholte Ausführungen von inneren Operatoren vermieden werden, wo immer dies möglich ist.
Wenn eine Spule zwischengespeicherte Ergebnisse wiedergeben kann, wird dies als Zurückspulen bezeichnet . Wenn die Spule ihre untergeordneten Operatoren ausführen muss, um korrekte Daten zu erhalten, wird ein Rebind ausgeführt auftritt.
Vielleicht finden Sie es hilfreich, an eine Spool-Neubindung zu denken als Cache-Fehltreffer und ein Zurückspulen als Cache-Treffer.
Lazy-Table-Spule
Diese Art von Performance-Spool kann sowohl mit apply verwendet werden und verschachtelte Schleifen verbinden .
Bewerben
Eine Neubindung (Cache Miss) tritt immer dann auf, wenn eine äußere Referenz vorliegt Wert ändert. Eine faule Tabellenspule wird durch Abschneiden neu gebunden seine Arbeitstabelle und vollständige Neubestückung mit seinen untergeordneten Operatoren.
Ein Rücklauf (Cache-Treffer) tritt auf, wenn die innere Seite mit dem gleichen ausgeführt wird äußere Referenzwerte als unmittelbar vorangehende Schleifeniteration. Ein Zurückspulen gibt zwischengespeicherte Ergebnisse aus der Arbeitstabelle der Spule wieder, wodurch die Kosten für die erneute Ausführung der Planoperatoren unterhalb der Spule eingespart werden.
Hinweis:Ein Lazy Table Spool speichert nur Ergebnisse für einen Satz von apply äußere Referenz Werte gleichzeitig.
Verschachtelte Schleifen verbinden
Der Lazy-Table-Spool wird einmal während der ersten Schleifeniteration gefüllt. Die Spule spult ihren Inhalt für jede nachfolgende Iteration des Joins zurück. Bei Joins mit verschachtelten Schleifen ist die innere Seite des Joins ein statischer Satz von Zeilen, da sich das Join-Prädikat auf dem Join selbst befindet. Der statische innere Zeilensatz kann daher zwischengespeichert und mehrfach über den Spool wiederverwendet werden. Eine verschachtelte Schleifen-Join-Performance-Spool wird nie neu gebunden.
Lazy Row Count Spool
Eine Zeilenzählspule ist kaum mehr als eine Tabellenspule ohne Spalten. Es speichert das Vorhandensein einer Zeile, projiziert jedoch keine Spaltendaten. Abgesehen davon, dass es existiert und erwähnt, dass es kann ein Hinweis auf einen Fehler in der Quellabfrage sein, ich werde nicht mehr zu Zeilenzähl-Spools sagen.
Von diesem Punkt an, wenn Sie im Text „Tabellenspule“ sehen, lesen Sie es bitte als „Tabellenspule“ (oder Zeilenanzahlspule), weil sie so ähnlich sind.
Lazy-Index-Spool
Die Lazy Index Spool Operator ist nur mit apply verfügbar .
Die Indexspule verwaltet eine Arbeitstabelle, die nicht abgeschnitten ist wenn äußere Referenz Werte ändern sich. Stattdessen werden dem vorhandenen Cache neue Daten hinzugefügt, die durch die äußeren Referenzwerte indiziert sind. Eine Lazy-Index-Spool unterscheidet sich von einer Lazy-Table-Spool darin, dass sie Ergebnisse von beliebigen wiedergeben kann vorherige Schleifeniteration, nicht nur die letzte.
Der nächste Schritt zum Verständnis, wann Performance-Spools in Ausführungsplänen erscheinen, erfordert ein wenig Verständnis dafür, wie der Optimierer funktioniert.
Optimierer-Hintergrund
Eine Quellabfrage wird durch Parsing, Algebrisierung, Vereinfachung und Normalisierung in eine logische Baumdarstellung umgewandelt. Wenn sich der resultierende Baum nicht für einen trivialen Plan qualifiziert, sucht der kostenbasierte Optimierer nach logischen Alternativen, die garantiert die gleichen Ergebnisse liefern, aber zu niedrigeren geschätzten Kosten.
Sobald der Optimierer potenzielle Alternativen generiert hat, implementiert er jede unter Verwendung geeigneter physikalischer Operatoren und berechnet die geschätzten Kosten. Der endgültige Ausführungsplan wird aus der kostengünstigsten Option erstellt, die für jede Betreibergruppe gefunden wurde. Weitere Einzelheiten zu diesem Prozess finden Sie in meiner Reihe „Detaillierter Einblick in den Abfrageoptimierer“.
Die allgemeinen Bedingungen, die erforderlich sind, damit eine Leistungsspule im endgültigen Plan des Optimierers erscheint, sind:
- Der Optimierer muss untersuchen eine logische Alternative, die einen logischen Spool enthält in einem generierten Ersatz. Das ist komplexer, als es sich anhört, also werde ich die Details im nächsten Hauptabschnitt entpacken.
- Der logische Spool muss implementierbar sein als physische Spule Operator in der Ausführungsmaschine. Für moderne Versionen von SQL Server bedeutet dies im Wesentlichen, dass alle Schlüsselspalten in einer Indexspule vergleichbar sein müssen Typ, nicht mehr als 900 Bytes* insgesamt, mit 64 Schlüsselspalten oder weniger.
- Das Beste Der vollständige Plan nach der kostenbasierten Optimierung muss eine der Spool-Alternativen enthalten. Mit anderen Worten, alle kostenbasierten Entscheidungen zwischen Spool- und Nicht-Spool-Optionen müssen zugunsten der Spool-Option ausfallen.
* Dieser Wert ist fest in SQL Server codiert und wurde nach der Erhöhung auf 1700 Bytes für nonclustered nicht geändert Indexschlüssel ab SQL Server 2016. Dies liegt daran, dass der Spool-Index ein clustered ist Index, kein Nonclustered-Index.
Optimiererregeln
Wir können mit T-SQL keinen Spool spezifizieren, daher bedeutet das Hinzufügen eines Spools in einem Ausführungsplan, dass der Optimierer entscheiden muss, ob er hinzugefügt werden soll. Als erster Schritt bedeutet dies, dass der Optimierer einen logischen Spool in eine der zu untersuchenden Alternativen aufnehmen muss.
Der Optimierer wendet nicht alle logischen Äquivalenzregeln, die er kennt, erschöpfend auf jeden Abfragebaum an. Angesichts des Ziels des Optimierers, schnell einen vernünftigen Plan zu erstellen, wäre dies verschwenderisch. Dies hat mehrere Aspekte. Zunächst geht der Optimierer schrittweise vor, wobei zuerst billigere und häufiger anwendbare Regeln ausprobiert werden. Wenn ein angemessener Plan in einem frühen Stadium gefunden wird oder die Abfrage nicht für spätere Stadien geeignet ist, kann der Optimierungsaufwand vorzeitig mit dem bisher gefundenen Plan mit den niedrigsten Kosten beendet werden. Diese Strategie trägt dazu bei, dass Sie nicht mehr Zeit für die Optimierung aufwenden, als durch inkrementelle Kostenverbesserungen gespart wird.
Regelabgleich
Jeder logische Operator im Abfragebaum wird schnell auf eine Musterübereinstimmung mit den in der aktuellen Optimierungsphase verfügbaren Regeln geprüft. Beispielsweise stimmt jede Regel nur mit einer Teilmenge logischer Operatoren überein und kann auch erfordern, dass bestimmte Eigenschaften vorhanden sind, z. B. eine garantiert sortierte Eingabe. Eine Regel kann einer einzelnen logischen Operation (einer einzelnen Gruppe) oder mehreren zusammenhängenden Gruppen (einem Unterabschnitt des Plans) entsprechen.
Nach dem Abgleich wird eine Kandidatenregel aufgefordert, einen Versprechenswert zu generieren . Dies ist eine Zahl, die angibt, wie wahrscheinlich es ist, dass die aktuelle Regel angesichts des lokalen Kontexts ein nützliches Ergebnis liefert. Beispielsweise kann eine Regel einen höheren Zusagewert generieren, wenn das Ziel viele Duplikate in seiner Eingabe, eine große geschätzte Anzahl von Zeilen, eine garantiert sortierte Eingabe oder eine andere wünschenswerte Eigenschaft aufweist.
Sobald vielversprechende Explorationsregeln identifiziert wurden, sortiert der Optimierer sie in der Reihenfolge der vielversprechenden Werte und beginnt damit, sie aufzufordern, neue logische Ersatzregeln zu generieren. Jede Regel kann einen oder mehrere Substitute erzeugen, die später unter Verwendung physikalischer Operatoren implementiert werden. Als Teil dieses Prozesses werden geschätzte Kosten berechnet.
Der Punkt all dessen, was für Performance-Spools gilt, ist, dass die Form und die Eigenschaften des logischen Plans dem Abgleich von spoolfähigen Regeln förderlich sein müssen und der lokale Kontext einen ausreichend hohen Versprechungswert erzeugen muss, den der Optimierer auswählt, um mithilfe der Regel Ersatz zu generieren .
Spool-Regeln
Es gibt eine Reihe von Regeln, die logische verschachtelte Schleifenverknüpfungen untersuchen oder bewerben Alternativen. Einige dieser Regeln können einen oder mehrere Ersatzstoffe mit einer bestimmten Art von Leistungsspule erzeugen. Andere Regeln, die mit verschachtelten Schleifen übereinstimmen oder gelten, erzeugen niemals eine Spool-Alternative.
Zum Beispiel die Regel ApplyToNL implementiert ein logisches apply als physische Schleifen verbinden sich mit äußeren Referenzen. Diese Regel kann mehrere Alternativen generieren jedes Mal wenn es läuft. Zusätzlich zum physischen Join-Operator kann jeder Ersatz einen Lazy-Table-Spool, einen Lazy-Index-Spool oder überhaupt keinen Spool enthalten. Die logischen Spool-Ersatzteile werden später durch eine andere Regel namens BuildSpool einzeln implementiert und als die entsprechend typisierten physischen Spools berechnet .
Als zweites Beispiel die Regel JNtoIdxLookup implementiert einen logischen Join als physisches apply , mit einer Indexsuche unmittelbar auf der Innenseite. Diese Regel nie generiert eine Alternative mit einer Spool-Komponente. JNtoIdxLookup wird frühzeitig ausgewertet und gibt bei Übereinstimmung einen hohen vielversprechenden Wert zurück, sodass einfache Index-Lookup-Pläne schnell gefunden werden.
Wenn der Optimierer frühzeitig eine kostengünstige Alternative wie diese findet, können komplexere Alternativen aggressiv beschnitten oder ganz übersprungen werden. Der Grund dafür ist, dass es keinen Sinn macht, Optionen zu verfolgen, die wahrscheinlich keine Verbesserung gegenüber einer bereits gefundenen kostengünstigen Alternative darstellen. Ebenso lohnt es sich nicht, weiter nachzuforschen, wenn die Gesamtkosten des derzeit besten Gesamtplans bereits niedrig genug sind.
Ein drittes Regelbeispiel:Die Regel JNtoNL ähnelt ApplyToNL , aber es implementiert nur physische nested loop joins , mit entweder einer faulen Tischspule oder gar keiner Spule. Diese Regel nie generiert einen Index-Spool, weil dieser Spool-Typ ein apply erfordert.
Spool-Generierung und -Kosten
Eine Regel, die fähig ist eine logische Spule zu erzeugen, wird dies nicht unbedingt jedes Mal tun, wenn sie aufgerufen wird. Es wäre verschwenderisch, logische Alternativen zu generieren, die so gut wie keine Chance haben, als billigste ausgewählt zu werden. Es entstehen auch Kosten für die Generierung neuer Alternativen, die wiederum weitere Alternativen hervorbringen können – von denen jede möglicherweise implementiert und kalkuliert werden muss.
Um dies zu verwalten, implementiert der Optimierer eine gemeinsame Logik für alle Spool-fähigen Regeln, um zu bestimmen, welche Art(en) von Spool-Alternativen basierend auf lokalen Planbedingungen generiert werden sollen.
Verschachtelte Schleifen verbinden
Für eine verschachtelte Schleifenverknüpfung , die Chance auf eine faule Tischspule erhöht sich entsprechend:
- Die geschätzte Anzahl von Zeilen auf der äußeren Eingabe des Joins.
- Die geschätzten Kosten von innenseitigen Planbetreibern.
Die Kosten der Spule werden durch Einsparungen zurückgezahlt, die dadurch erzielt werden, dass die Ausführung durch die Bedienungsperson auf der Innenseite vermieden wird. Die Einsparungen steigen mit mehr inneren Iterationen und höheren inneren Kosten. Dies gilt insbesondere deshalb, weil das Kostenmodell Tabellen-Spool-Rückläufen (Cache-Treffern) relativ niedrige E/A- und CPU-Kostenzahlen zuweist. Denken Sie daran, dass eine Tabellenspule in einem Nested-Loops-Join immer nur zurückgespult wird, da das Fehlen von Parametern bedeutet, dass der Datensatz auf der Innenseite statisch ist.
Eine Spule kann Daten dichter speichern als die Betreiber, die es füttern. Ein gruppierter Basistabellenindex kann beispielsweise durchschnittlich 100 Zeilen pro Seite speichern. Nehmen wir an, eine Abfrage benötigt nur einen einzigen ganzzahligen Spaltenwert aus jeder Wide Clustered Index-Zeile. Das Speichern nur des ganzzahligen Werts in der Spool-Arbeitstabelle bedeutet, dass weit über 800 solcher Zeilen pro Seite gespeichert werden können. Dies ist wichtig, da der Optimierer die Kosten des Tabellenspools teilweise anhand einer Schätzung der Anzahl der Arbeitstabellenseiten bewertet erforderlich. Andere Kostenfaktoren umfassen die CPU-Kosten pro Zeile, die beim Schreiben und Lesen des Spools über die geschätzte Anzahl von Schleifeniterationen anfallen.
Der Optimierer ist wohl etwas zu erpicht darauf, Lazy-Table-Spools zur Innenseite eines Joins mit verschachtelten Schleifen hinzuzufügen. Dennoch ist die Entscheidung des Optimierers im Hinblick auf die geschätzten Kosten immer sinnvoll. Ich persönlich betrachte Nested-Loop-Joins als hohes Risiko , da sie schnell langsam werden können, wenn eine der Join-Eingabekardinalitätsschätzungen zu niedrig ist.
Eine Tischspule darf helfen, die Kosten zu reduzieren, aber es kann die Worst-Case-Leistung eines naiven Joins mit verschachtelten Schleifen nicht vollständig verbergen. Ein indizierter Apply-Join ist normalerweise vorzuziehen und widerstandsfähiger gegenüber Schätzungsfehlern. Es ist auch eine gute Idee, Abfragen zu schreiben, die der Optimierer gegebenenfalls mit Hash oder Merge-Join implementieren kann.
Lazy-Table-Spule anwenden
Für eine Bewerbung , die Chancen auf eine faule Tischspule steigen mit der geschätzten Anzahl von Duplikaten Verbinden Sie Schlüsselwerte mit der äußeren Eingabe von apply. Bei mehr Duplikaten gibt es statistisch eine höhere Wahrscheinlichkeit, dass die Spule ihre aktuell gespeicherten Ergebnisse bei jeder Iteration zurückspult. Eine anwendungsverzögerte Tischspule mit niedrigeren geschätzten Kosten hat eine bessere Chance, im endgültigen Ausführungsplan berücksichtigt zu werden.
Wenn die Zeilen, die an der äußeren Eingabe „apply“ ankommen, keine bestimmte Reihenfolge haben, nimmt der Optimierer eine statistische Bewertung vor wie wahrscheinlich es ist, dass jede Iteration zu einem billigen Zurückspulen oder einem teuren Neubinden führt. Diese Bewertung verwendet Daten aus Histogrammschritten, sofern verfügbar, aber selbst dieses Best-Case-Szenario ist eher eine fundierte Vermutung. Ohne eine Garantie ist die Reihenfolge der an der äußeren Eingabe von apply ankommenden Zeilen unvorhersehbar.
Dieselben Optimierungsregeln, die logische Spool-Alternativen generieren, können auch Geben Sie an, dass der Apply-Operator requires ist sortierte Zeilen an seinem äußeren Eingang. Dies maximiert Lazy Spool Zurückspulen weil alle Duplikate garantiert in einem Block angetroffen werden. Wenn die Sortierreihenfolge der äußeren Eingabe garantiert ist, entweder durch beibehaltene Reihenfolge oder eine explizite Sortierung , sind die Kosten der Spule stark reduziert. Der Optimierer berücksichtigt den Einfluss der Sortierreihenfolge auf die Anzahl der Spulenrückläufe und Neubindungen.
Pläne mit einer Sortierung auf dem äußeren Eingang anwenden und eine Lazy Table Spool am inneren Eingang sind durchaus üblich. Die außenseitige Sortieroptimierung kann am Ende dennoch kontraproduktiv sein. Dies kann zum Beispiel passieren, wenn die äußere Kardinalitätsschätzung so niedrig ist, dass die Sortierung zu tempdb überläuft .
Lazy Index Spool anwenden
Für eine Bewerbung , wodurch ein fauler Index-Spool entsteht Alternative hängt von Planform sowie Kosten ab.
Der Optimierer benötigt:
- Einige duplizieren Join-Werte an der äußeren Eingabe.
- Eine Gleichheit Join-Prädikat (oder ein logisches Äquivalent, das der Optimierer versteht, wie
x <= y AND x >= y). - Eine Garantie dass die äußeren Referenzen eindeutig sind unterhalb der vorgeschlagenen Lazy-Index-Spule.
In Ausführungsplänen wird die erforderliche Eindeutigkeit häufig durch eine Aggregatgruppierung durch die äußeren Referenzen oder ein skalares Aggregat (eines ohne Gruppieren nach) bereitgestellt. Eindeutigkeit kann auch auf andere Weise bereitgestellt werden, zum Beispiel durch das Vorhandensein eines eindeutigen Indexes oder einer Einschränkung.
Ein Spielzeugbeispiel, das die Planform zeigt, ist unten:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
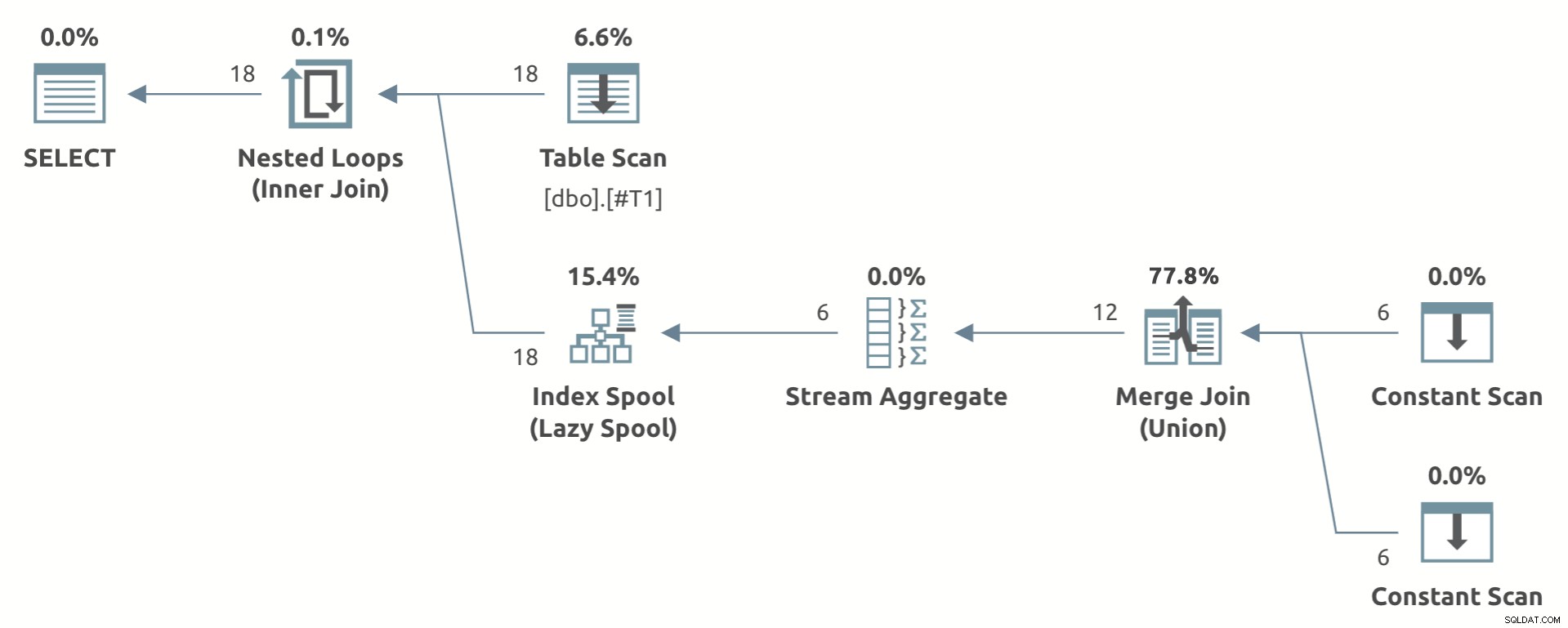
Beachten Sie das Stream-Aggregat unterhalb der Lazy Index Spool .
Wenn die Anforderungen an die Planform erfüllt sind, generiert der Optimierer häufig eine Lazy-Index-Alternative (vorbehaltlich der zuvor erwähnten Einschränkungen). Ob der endgültige Plan eine Lazy-Index-Spule enthält oder nicht, hängt von den Kosten ab.
Index-Spool versus Tabellen-Spool
Die Anzahl der geschätzten Rückläufe und neu binden für eine faule Indexspule ist das dasselbe wie bei einer faulen Tischspule ohne sortiert äußere Eingabe anwenden.
Dies mag wie ein ziemlich unglücklicher Zustand erscheinen. Der Hauptvorteil einer Indexspule besteht darin, dass sie alle zuvor gesehenen Ergebnisse zwischenspeichert. Dies sollte den Index-Spool zurückspulen wahrscheinlicher als für eine Tischspule (ohne Außeneingangssortierung) unter den gleichen Umständen. Mein Verständnis ist, dass diese Eigenart existiert, weil der Optimierer ohne sie viel zu oft eine Indexspule wählen würde.
Ungeachtet dessen passt sich das Kostenmodell in gewissem Maße an das Obige an, indem es unterschiedliche I/O- und CPU-Kostenzahlen für die Anfangs- und Folgezeilen für Index- und Tabellen-Spools verwendet. Der Nettoeffekt ist, dass eine Indexspule normalerweise weniger kostet als eine Tischspule ohne sortierte äußere Eingabe, aber denken Sie an die restriktiven Planformanforderungen, die Indexspulen relativ faul machen selten.
Dennoch ist der Hauptkostenkonkurrent eines Lazy-Spool-Index eine Tischspule mit sortierter äußerer Eingang. Die Intuition dafür ist ziemlich einfach:Sortierte äußere Eingabe bedeutet, dass die Tabellenspule garantiert alle doppelten äußeren Referenzen nacheinander sieht. Das bedeutet, es wird neu gebunden nur einmal pro eindeutigem Wert und Zurückspulen für alle Duplikate. Dies ist dasselbe wie das erwartete Verhalten einer Indexspule (zumindest logisch gesprochen).
In der Praxis ist es wahrscheinlicher, dass ein Index-Spool gegenüber einem sortieroptimierten Tabellen-Spool bevorzugt wird, da weniger doppelte Anwendungsschlüsselwerte vorhanden sind. Weniger doppelte Schlüssel reduzieren das Zurückspulen Vorteil des sortieroptimierten Tabellen-Spools im Vergleich zu den zuvor erwähnten „unglücklichen“ Index-Spool-Schätzungen.
Die Index-Spool-Option profitiert auch von den geschätzten Kosten einer Tabellen-Spool-Außenseite Sortieren erhöht sich. Dies würde meistens mit mehr (oder breiteren) Zeilen an diesem Punkt im Plan verbunden sein.
Trace-Flags und Hinweise
-
Leistungsspulen können deaktiviert werden mit leicht dokumentiertem Trace-Flag 8690 , oder der dokumentierte Abfragehinweis
NO_PERFORMANCE_SPOOLauf SQL Server 2016 oder höher. -
Undokumentiertes Trace-Flag 8691 kann (auf einem Testsystem) verwendet werden, um immer einen Performance-Spool hinzuzufügen wenn möglich. Der Typ von faulen Spools, die Sie erhalten (Zeilenanzahl, Tabelle oder Index), kann nicht erzwungen werden; es hängt immer noch von der Kostenschätzung ab.
-
Undokumentiertes Trace-Flag 2363 kann mit dem neuen Kardinalitätsschätzungsmodell verwendet werden, um die Ableitung der eindeutigen Schätzung anzuzeigen auf der äußeren Eingabe zu einer Anwendung und Kardinalitätsschätzung im Allgemeinen.
-
Nicht dokumentiertes Trace-Flag 9198 kann verwendet werden, um Lazy Index Performance Spools zu deaktivieren speziell. Sie können stattdessen immer noch eine verzögerte Tabellen- oder Zeilenzählungsspule erhalten (mit oder ohne Sortieroptimierung), je nach Kosten.
-
Undokumentiertes Trace-Flag 2387 kann verwendet werden, um die CPU-Kosten zu senken Zeilen aus einem faulen Index-Spool zu lesen . Dieses Flag wirkt sich auf allgemeine CPU-Kostenschätzungen zum Lesen einer Reihe von Zeilen aus einem B-Baum aus. Dieses Flag macht aus Kostengründen tendenziell die Index-Spool-Auswahl wahrscheinlicher.
Weitere Ablaufverfolgungs-Flags und Methoden zum Ermitteln, welche Optimierungsregeln während der Abfragekompilierung aktiviert wurden, finden Sie in meiner Reihe „Query Optimizer Deep Dive“.
Abschließende Gedanken
Es gibt sehr viele interne Details, die sich darauf auswirken, ob der endgültige Ausführungsplan eine Leistungsspule verwendet oder nicht. Ich habe versucht, die Hauptüberlegungen in diesem Artikel zu behandeln, ohne zu weit in die äußerst komplizierten Details der Kostenformeln für Spool-Operatoren einzudringen. Hoffentlich gibt es hier genügend allgemeine Ratschläge, um Ihnen zu helfen, mögliche Gründe für einen bestimmten Leistungsspulentyp in einem Ausführungsplan (oder das Fehlen eines solchen) zu ermitteln.
Leistungsspulen bekommen oft einen schlechten Ruf, ich denke, es ist fair zu sagen. Einiges davon ist zweifellos verdient. Viele von Ihnen werden eine Demo gesehen haben, in der ein Plan ohne „Leistungsspule“ schneller ausgeführt wird als mit. In gewisser Weise ist das nicht unerwartet. Es gibt Grenzfälle, das Kostenmodell ist nicht perfekt, und Demos enthalten zweifellos oft Pläne mit schlechten Kardinalitätsschätzungen oder anderen Problemen, die den Optimierer einschränken.
Abgesehen davon wünsche ich mir manchmal, dass SQL Server eine Art Warnung oder ein anderes Feedback liefert, wenn es darauf zurückgreift, einem Nested-Loops-Join einen Lazy-Table-Spool hinzuzufügen (oder eine Anwendung ohne einen verwendeten unterstützenden inneren Index). Wie im Hauptteil erwähnt, sind dies die Situationen, die meiner Meinung nach am häufigsten schief gehen, wenn sich die Kardinalitätsschätzungen als schrecklich niedrig herausstellen.
Vielleicht wird der Abfrageoptimierer eines Tages ein gewisses Risikokonzept berücksichtigen, um Entscheidungen zu planen, oder „anpassungsfähigere“ Fähigkeiten bereitstellen. In der Zwischenzeit lohnt es sich, Ihre Joins mit verschachtelten Schleifen mit nützlichen Indizes zu unterstützen und das Schreiben von Abfragen zu vermeiden, die nach Möglichkeit nur mit verschachtelten Schleifen implementiert werden können. Ich verallgemeinere das natürlich, aber der Optimierer ist tendenziell besser, wenn er mehr Auswahlmöglichkeiten, ein vernünftiges Schema, gute Metadaten und überschaubare T-SQL-Anweisungen hat, mit denen er arbeiten kann. Genauso wie ich, wenn ich darüber nachdenke.
Andere Spulenartikel
Non-Performance-Spools werden für viele Zwecke innerhalb von SQL Server verwendet, einschließlich:
- Halloween-Schutz
- Einige Fensterfunktionen im Zeilenmodus
- Berechnung mehrerer Aggregate
- Optimierungsanweisungen, die Daten ändern