Der Wert guter Testdaten für DBAs ist bekannt:
„Das Testen datenbankintensiver Anwendungen ist mit einzigartigen Herausforderungen verbunden, die sich aus versteckten Abhängigkeiten, subtilen Unterschieden in der Datensemantik, Zieldatenbankschemata und impliziten Geschäftsregeln ergeben. Diese Herausforderungen werden noch schwieriger, wenn die Anwendung integrierte und heterogene Datenbanken oder vertrauliche Daten betrifft. Richtige Testdaten, die reale Datenprobleme simulieren, sind entscheidend für das Erreichen angemessener Qualitätsbenchmarks für funktionale Eingabevalidierung, Last-, Leistungs- und Stresstests. ” – Ali Raza &Stephen Clyde, Zusammenfassung von „Creating Datasets for Testing Relational Databases“
Das Testen von Datenbankvorgängen, das Prototyping von Data Warehouse- und ETL/ELT-Jobs, das sichere Auslagern von Dateimustern und Berichten und das Ausführen von Leistungsbenchmarks auf DB-Appliances erfordern alle Testdaten mit dem Aussehen und Verhalten der Produktionsdatenbank, damit die Anwendungen diese Testdaten jetzt verwenden später erfolgreich mit realen Daten durchführen. In ihrem Buch von 2012 vergleichen Raza und Clyde die Generierung von Testdaten mit der Extraktion von Testdaten.
IRI und seine Benutzer wissen, dass die Verwendung echter Daten zum Testen unerwünscht ist. Der offensichtlichste Grund heute ist, dass reale Daten riskieren, persönlich identifizierbare Informationen (PII) offenzulegen, die vertraulich behandelt werden müssen. Ein Entwickler oder Tester möchte in dieser Phase keine Prozesse ausführen oder ein Datenbanksystem testen und riskieren, Kundeninformationen wie Sozialversicherungsnummern, Kreditkarteninformationen, Geburtsdaten usw. zu teilen. Die derzeit verfügbaren realen Daten sind möglicherweise auch nicht robust oder realistisch genug, um Anwendungen oder Datenbanken, die größere Volumina und/oder Wertebereiche verarbeiten müssen, Stresstests zu unterziehen.
Leider haben Raza und Clyde ihr Buch geschrieben, bevor RowGen v3 veröffentlicht wurde, als sie möglicherweise beobachtet haben, dass es Testdaten erzeugt, die:
1) stellt PII nicht offen, weil sie neue oder randomisierte echte Spaltenwerte enthält
2) behält die strukturelle und referenzielle Integrität bei, die in der ursprünglichen DDL definiert ist
3) ist nicht auf die Datenmengen der ursprünglichen Datenbank beschränkt oder Wertebereiche
4) können durch die Generierung von Skripten angepasst werden, um komplexe Anforderungen zu erfüllen
5) werden vorsortiert und automatisch für die schnellstmögliche Bestückung geladen
6) werden im Batch definiert Skripte, die vielfältige Flexibilität aufweisen und nach Bedarf exportiert, wiederverwendet und modifiziert werden können
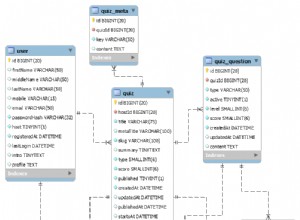
IRI RowGen v3 ist die neueste Version des weltweit schnellsten und robustesten Generators für Testdaten mit hohem Volumen für relationale Datenbanken. RowGen wird von der IRI Workbench-GUI, die auf Eclipse aufgebaut ist, auf der Befehlszeile oder von Batch-Programmen ausgeführt, um die Qualität und Quantität der Testdaten zu erzeugen, die erforderlich sind, um den Umfang, die Layouts und die Beziehungen innerhalb der Produktionsdatenbanken genau wiederzugeben, und im Gegenzug, Data Warehouses und Betriebsdatenspeicher.
Der neue DB-Testdaten-Assistent von RowGen v3 führt Benutzer, wenn er über die IRI Workbench-GUI gestartet wird, durch die Spezifikation und Automatisierung von:
Parsen – Durch die Auswahl des Schemas und der zu füllenden Tabellen übersetzt RowGen die Datenbanktabellenbeschreibungen und Integritätsbedingungen in .rcl-Skripte, die die Quellstruktur, die abhängigen Sätze und die Datenerstellung in der erforderlichen Reihenfolge angeben, um die Tabellen im richtigen Format zu füllen, und wobei alle Primärschlüssel, eindeutigen Indizes und Fremdschlüsselbeziehungen berücksichtigt werden.
Generation – durch Erstellen und Ausführen der .rcl-Skripte, um eine Testdatei pro Tabelle zu erstellen, die in großen Mengen geladen und/oder für die zukünftige Verwendung gespeichert werden kann.
Bevölkerung – durch Massenladen der Zieltabellen in der richtigen Reihenfolge mit vorsortierten Testdaten, die strukturell und referenziell korrekt sind.
Der Prozess kann riesige Testdatenbanken schnell laden und sowohl Geschäftsregeln als auch Datenschutzgesetze einhalten. Die generierten Daten sind realistisch und robust genug, um Datenbankoperationen zu testen und Anwendungen abzufragen.
RowGen v3 unterstützt auch regel- und skriptbasierte Optionen zur Steuerung bestimmter Feldwerte und Wertebereichsverteilungen, die bestimmte Datenbankeinschränkungen berücksichtigen und das Erscheinen und die Häufigkeit von Daten in der Produktion am besten darstellen. Benutzer können auch grafisch darstellen und visuell belegen, dass die Testwerte linearen, normalisierten, gewichteten oder Standardverteilungen entsprechen.
Weitere Informationen zu RowGen v3 finden Sie unter www.iri.com/products/rowgen, www.iri.com/products/rowgen/gui oder lesen Sie die anderen Artikel im Abschnitt „Testdaten“ des IRI-Blogs.