Im ersten Teil dieses Blogs haben wir eine exemplarische Vorgehensweise zur Bereitstellung von MySQL InnoDB Cluster mit einem Beispiel behandelt, wie die Anwendungen sich über einen dedizierten Lese-/Schreibport mit dem Cluster verbinden können.
In dieser exemplarischen Vorgehensweise zeigen wir Beispiele zur Überwachung, Verwaltung und Skalierung des InnoDB-Clusters als Teil der laufenden Clusterwartungsvorgänge. Wir verwenden denselben Cluster, den wir im ersten Teil des Blogs bereitgestellt haben. Das folgende Diagramm zeigt unsere Architektur:
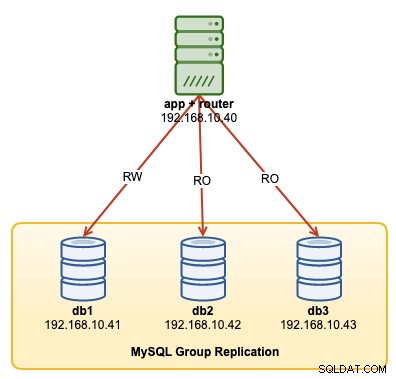
Wir haben eine MySQL-Gruppenreplikation mit drei Knoten und einen Anwendungsserver, auf dem ausgeführt wird MySQL-Router. Alle Server laufen auf Ubuntu 18.04 Bionic.
MySQL InnoDB-Cluster-Befehlsoptionen
Bevor wir mit einigen Beispielen und Erklärungen fortfahren, ist es gut zu wissen, dass Sie eine Erklärung jeder Funktion in MySQL-Cluster für Cluster-Komponenten erhalten können, indem Sie die Funktion help() verwenden, wie unten gezeigt:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Die folgende Liste zeigt die verfügbaren Funktionen auf MySQL Shell 8.0.18 für MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Fügt dem Cluster eine Instanz hinzu.
- checkInstanceState(instance)- überprüft den Gtid-Status der Instanz in Bezug auf den Cluster.
- describe()- Beschreibt die Struktur des Clusters.
- disconnect()- Trennt alle internen Sitzungen, die vom Cluster-Objekt verwendet werden.
- dissolve([options])- Deaktiviert die Replikation und deregistriert die ReplicaSets vom Cluster.
- forceQuorumUsingPartitionOf(instance[, password])- Stellt den Cluster nach Quorumverlust wieder her.
- getName()- Ruft den Namen des Clusters ab.
- help([member])- Bietet Hilfe zu dieser Klasse und ihren Mitgliedern
- options([options])- Listet die Cluster-Konfigurationsoptionen auf.
- rejoinInstance(instance[, options])- Verbindet eine Instanz wieder mit dem Cluster.
- removeInstance(instance[, options])- Entfernt eine Instanz aus dem Cluster.
- rescan([options])- Scannt den Cluster erneut.
- resetRecoveryAccountsPassword(options)- Setzen Sie das Passwort der Wiederherstellungskonten des Clusters zurück.
- setInstanceOption(instance, option, value)- Ändert den Wert einer Konfigurationsoption in einem Clustermitglied.
- setOption(option, value)- Ändert den Wert einer Konfigurationsoption für den gesamten Cluster.
- setPrimaryInstance(instance)- Wählt ein bestimmtes Cluster-Mitglied als neuen primären.
- status([options])- Beschreibt den Status des Clusters.
- switchToMultiPrimaryMode()- Schaltet den Cluster in den Multi-Primary-Modus.
- switchToSinglePrimaryMode([instance])- Schaltet den Cluster in den Single-Primary-Modus.
Wir werden uns die meisten verfügbaren Funktionen ansehen, die uns helfen, den Cluster zu überwachen, zu verwalten und zu skalieren.
Überwachung von MySQL InnoDB-Cluster-Operationen
Cluster-Status
Um den Clusterstatus zu überprüfen, verwenden Sie zunächst die MySQL-Shell-Befehlszeile und verbinden Sie sich dann als example@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Erstellen Sie dann ein Objekt namens „cluster“ und deklarieren Sie es als globales „dba“-Objekt, das mithilfe der AdminAPI Zugriff auf InnoDB-Clusterverwaltungsfunktionen bietet (sehen Sie sich die MySQL Shell-API-Dokumentation an):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Dann können wir den Objektnamen verwenden, um die API-Funktionen für das „dba“-Objekt aufzurufen:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Die Ausgabe ist ziemlich lang, aber wir können sie herausfiltern, indem wir die Kartenstruktur verwenden. Wenn wir beispielsweise nur die Replikationsverzögerung für db3 anzeigen möchten, könnten wir wie folgt vorgehen:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Beachten Sie, dass es bei der Gruppenreplikation zu einer Replikationsverzögerung kommt, die von der Schreibintensität des primären Mitglieds im Replikatsatz und den group_replication_flow_control_*-Variablen abhängt. Wir werden dieses Thema hier nicht im Detail behandeln. Sehen Sie sich diesen Blogbeitrag an, um mehr über die Leistung der Gruppenreplikation und die Flusskontrolle zu erfahren.
Eine andere ähnliche Funktion ist die Funktion describe(), aber diese ist etwas einfacher. Es beschreibt die Struktur des Clusters einschließlich aller seiner Informationen, ReplicaSets und Instanzen:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}Auf ähnliche Weise können wir die JSON-Ausgabe mithilfe der Kartenstruktur filtern:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryAls der primäre Knoten ausfiel (in diesem Fall db1), gab die Ausgabe Folgendes zurück:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Achten Sie auf den Status OK_NO_TOLERANCE, bei dem der Cluster noch läuft, aber keinen weiteren Ausfall tolerieren kann, nachdem einer von drei Knoten nicht verfügbar ist. Die primäre Rolle wurde automatisch von db2 übernommen, und die Datenbankverbindungen von der Anwendung werden an den richtigen Knoten umgeleitet, wenn sie sich über MySQL Router verbinden. Sobald db1 wieder online ist, sollten wir den folgenden Status sehen:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Es zeigt, dass db1 jetzt verfügbar ist, aber als sekundär mit aktiviertem Schreibschutz dient. Die primäre Rolle wird weiterhin db2 zugewiesen, bis beim Knoten etwas schief geht, wo automatisch ein Failover auf den nächsten verfügbaren Knoten erfolgt.
Instanzstatus prüfen
Wir können den Status eines MySQL-Knotens überprüfen, bevor wir planen, ihn dem Cluster hinzuzufügen, indem wir die Funktion checkInstanceState() verwenden. Es analysiert die von der Instanz ausgeführten GTIDs mit den ausgeführten/gelöschten GTIDs auf dem Cluster, um festzustellen, ob die Instanz für das Cluster gültig ist.
Das Folgende zeigt den Instanzzustand von db3 im Standalone-Modus, vor einem Teil des Clusters:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Wenn der Knoten bereits Teil des Clusters ist, sollten Sie Folgendes erhalten:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Jeden "abfragbaren" Zustand überwachen
Mit MySQL Shell können wir jetzt die integrierten Befehle \show und \watch verwenden, um jede administrative Abfrage in Echtzeit zu überwachen. Zum Beispiel können wir den Echtzeitwert von verbundenen Threads erhalten, indem wir verwenden:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Oder holen Sie sich die aktuelle MySQL-Prozessliste:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTWir können dann den Befehl \watch verwenden, um einen Bericht auf die gleiche Weise wie den Befehl \show auszuführen, aber er aktualisiert die Ergebnisse in regelmäßigen Abständen, bis Sie den Befehl mit Strg + C abbrechen. Wie in gezeigt die folgenden Beispiele:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTDas Standard-Aktualisierungsintervall beträgt 2 Sekunden. Sie können den Wert ändern, indem Sie das Flag --interval verwenden und einen Wert von 0,1 bis 86400 angeben.
MySQL InnoDB-Clusterverwaltungsvorgänge
Primäre Umschaltung
Die primäre Instanz ist der Knoten, der als Anführer in einer Replikationsgruppe angesehen werden kann und Lese- und Schreibvorgänge ausführen kann. Im Single-Primary-Topologiemodus ist nur eine primäre Instanz pro Cluster zulässig. Diese Topologie wird auch als Replikatsatz bezeichnet und ist der empfohlene Topologiemodus für die Gruppenreplikation mit Schutz vor Sperrkonflikten.
Um eine primäre Instanzumschaltung durchzuführen, melden Sie sich bei einem der Datenbankknoten als Benutzer „clusteradmin“ an und geben Sie den Datenbankknoten an, den Sie heraufstufen möchten, indem Sie die Funktion setPrimaryInstance() verwenden:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Wir haben gerade db1 als neue primäre Komponente hochgestuft und db2 ersetzt, während db3 als sekundärer Knoten verbleibt.
Cluster herunterfahren
Der beste Weg, um den Cluster ordnungsgemäß herunterzufahren, indem zuerst der MySQL Router-Dienst (falls er ausgeführt wird) auf dem Anwendungsserver gestoppt wird:
$ myrouter/stop.shDer obige Schritt bietet Clusterschutz vor versehentlichen Schreibvorgängen durch die Anwendungen. Fahren Sie dann einen Datenbankknoten nach dem anderen herunter, indem Sie den Standard-Stoppbefehl von MySQL verwenden, oder führen Sie das Herunterfahren des Systems nach Belieben durch:
$ systemctl stop mysqlStarten des Clusters nach einem Herunterfahren
Falls Ihr Cluster vollständig ausfällt oder Sie den Cluster nach einem sauberen Herunterfahren starten möchten, können Sie mit der Funktion dba.rebootClusterFromCompleteOutage() sicherstellen, dass er korrekt neu konfiguriert wird. Es bringt einfach einen Cluster wieder ONLINE, wenn alle Mitglieder OFFLINE sind. Für den Fall, dass ein Cluster komplett gestoppt wurde, müssen die Instanzen gestartet werden und erst dann kann der Cluster gestartet werden.
Stellen Sie daher sicher, dass alle MySQL-Server gestartet sind und laufen. Prüfen Sie auf jedem Datenbankknoten, ob der mysqld-Prozess läuft:
$ ps -ef | grep -i mysqlWählen Sie dann einen Datenbankserver als primären Knoten aus und stellen Sie über die MySQL-Shell eine Verbindung her:
MySQL|JS> shell.connect("example@sqldat.com:3306");Führen Sie den folgenden Befehl von diesem Host aus, um sie zu starten:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Sie werden mit den folgenden Fragen konfrontiert:
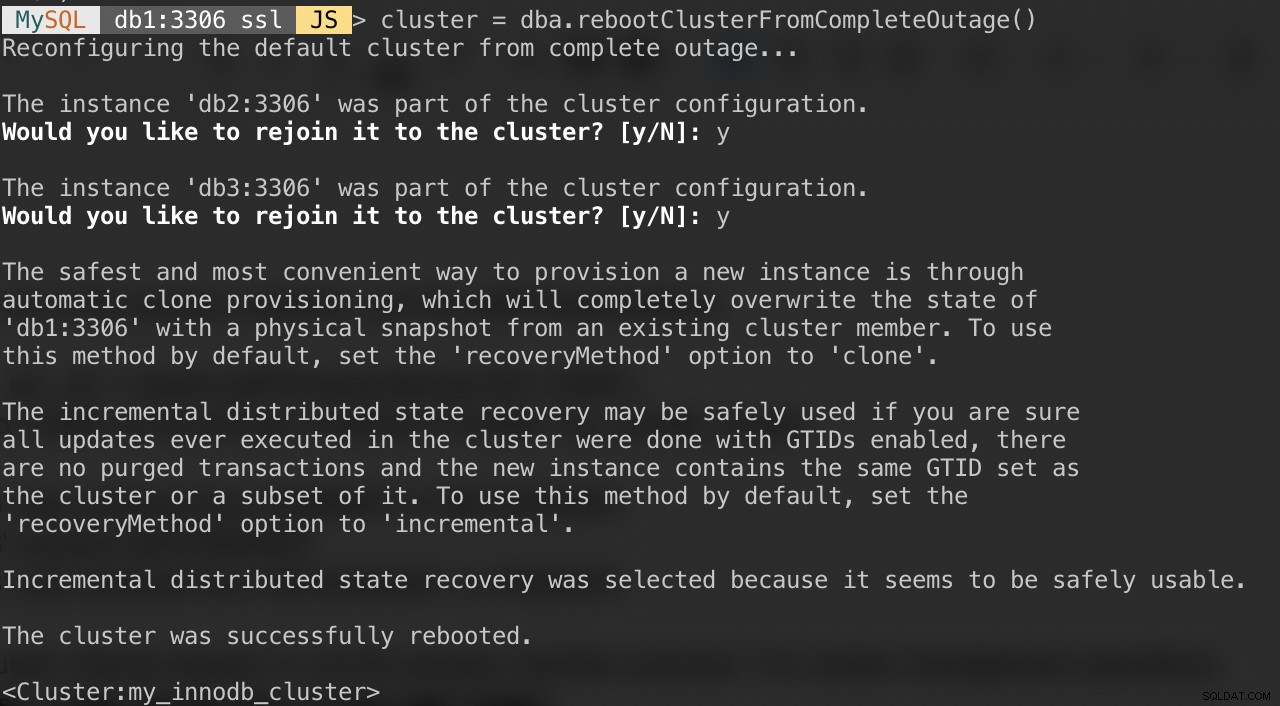
Nachdem die obigen Schritte abgeschlossen sind, können Sie den Clusterstatus überprüfen:
MySQL|db1:3306 ssl|JS> cluster.status()Zu diesem Zeitpunkt ist db1 der primäre Knoten und der Writer. Der Rest sind die sekundären Mitglieder. Wenn Sie den Cluster mit db2 oder db3 als primärem Knoten starten möchten, können Sie die Funktion shell.connect() verwenden, um eine Verbindung zum entsprechenden Knoten herzustellen und rebootClusterFromCompleteOutage() von diesem bestimmten Knoten aus auszuführen.
Sie können dann den MySQL Router-Dienst starten (falls er noch nicht gestartet ist) und die Anwendung erneut mit dem Cluster verbinden lassen.
Mitglieder- und Clusteroptionen festlegen
Um die clusterweiten Optionen zu erhalten, führen Sie einfach Folgendes aus:
MySQL|db1:3306 ssl|JS> cluster.options()Oben werden die globalen Optionen für den Replikatsatz und auch individuelle Optionen pro Mitglied im Cluster aufgelistet. Diese Funktion ändert eine InnoDB-Cluster-Konfigurationsoption in allen Mitgliedern des Clusters. Die unterstützten Optionen sind:
- clusterName:Zeichenfolgenwert zum Definieren des Clusternamens.
- exitStateAction:Zeichenfolgenwert, der die Ausgangszustandsaktion der Gruppenreplikation angibt.
- memberWeight:ganzzahliger Wert mit prozentualer Gewichtung für automatische Primärwahl bei Failover.
- failoverConsistency:Zeichenfolgenwert, der die vom Cluster bereitgestellten Konsistenzgarantien angibt.
- consistency: String-Wert, der die Konsistenzgarantien angibt, die der Cluster bietet.
- expelTimeout:ganzzahliger Wert zum Definieren des Zeitraums in Sekunden, den Cluster-Mitglieder auf ein nicht antwortendes Mitglied warten sollen, bevor sie es aus dem Cluster entfernen.
- autoRejoinTries:ganzzahliger Wert, um festzulegen, wie oft eine Instanz versucht, dem Cluster wieder beizutreten, nachdem sie ausgeschlossen wurde.
- disableClone:boolescher Wert, der verwendet wird, um die Verwendung von Klonen auf dem Cluster zu deaktivieren.
Ähnlich wie bei anderen Funktionen kann die Ausgabe in der Kartenstruktur gefiltert werden. Der folgende Befehl listet nur die Optionen für db2 auf:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Sie können die obige Liste auch erhalten, indem Sie die Funktion help() verwenden:
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Der folgende Befehl zeigt ein Beispiel, um eine Option namens memberWeight für alle Mitglieder auf 60 (von 50) zu setzen:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Wir können die Konfigurationsverwaltung auch automatisch über die MySQL-Shell durchführen, indem wir die Funktion setInstanceOption() verwenden und den Datenbankhost, den Optionsnamen und den entsprechenden Wert übergeben:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Die unterstützten Optionen sind:
- exitStateAction: String-Wert, der die Ausgangszustandsaktion der Gruppenreplikation angibt.
- memberWeight:ganzzahliger Wert mit prozentualer Gewichtung für automatische Primärwahl bei Failover.
- autoRejoinTries:ganzzahliger Wert, um festzulegen, wie oft eine Instanz versucht, dem Cluster wieder beizutreten, nachdem sie ausgeschlossen wurde.
- Beschrifte einen String-Identifizierer der Instanz.
Umschalten in den Multi-Primary/Single-Primary-Modus
Standardmäßig ist der InnoDB-Cluster mit Single-Primary konfiguriert, d. h. nur ein Mitglied kann Lese- und Schreibvorgänge zu einem bestimmten Zeitpunkt ausführen. Dies ist die sicherste und empfohlene Methode zum Ausführen des Clusters und für die meisten Workloads geeignet.
Wenn die Anwendungslogik jedoch verteilte Schreibvorgänge verarbeiten kann, ist es wahrscheinlich eine gute Idee, in den Multi-Primary-Modus zu wechseln, in dem alle Mitglieder im Cluster gleichzeitig Lese- und Schreibvorgänge verarbeiten können. Um vom Single-Primary- in den Multi-Primary-Modus zu wechseln, verwenden Sie einfach die Funktion switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Bestätigen Sie mit:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Im Multi-Primary-Modus sind alle Knoten primär und können Lese- und Schreibvorgänge verarbeiten. Beim Senden einer neuen Verbindung über MySQL Router auf Single-Writer-Port (6446) wird die Verbindung nur an einen Knoten gesendet, wie in diesem Beispiel db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Wenn sich die Anwendung mit dem Multi-Writer-Port (6447) verbindet, wird die Verbindung über einen Round-Robin-Algorithmus für alle Mitglieder belastet:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Wie Sie der obigen Ausgabe entnehmen können, sind alle Knoten in der Lage, Lese- und Schreibvorgänge mit read_only =OFF zu verarbeiten. Sie können sichere Schreibvorgänge an alle Mitglieder verteilen, indem Sie sich mit dem Multi-Writer-Port (6447) verbinden, und die widersprüchlichen oder umfangreichen Schreibvorgänge an den Single-Writer-Port (6446) senden.
Um wieder in den Single-Primary-Modus zu wechseln, verwenden Sie die Funktion switchToSinglePrimaryMode() und geben Sie ein Mitglied als primären Knoten an. In diesem Beispiel haben wir db1:
gewähltMySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.An diesem Punkt ist db1 jetzt der primäre Knoten, der mit deaktiviertem Nur-Lesen konfiguriert ist, und der Rest wird als sekundärer Knoten mit aktiviertem Nur-Lesen konfiguriert.
MySQL InnoDB-Cluster-Skalierungsvorgänge
Hochskalieren (Hinzufügen eines neuen DB-Knotens)
Beim Hinzufügen einer neuen Instanz muss ein Knoten zuerst bereitgestellt werden, bevor er an der Replikationsgruppe teilnehmen darf. Der Bereitstellungsprozess wird automatisch von MySQL durchgeführt. Außerdem können Sie zuerst den Instanzstatus überprüfen, ob der Knoten gültig ist, um dem Cluster beizutreten, indem Sie die Funktion checkInstanceState() wie zuvor erklärt verwenden.
Verwenden Sie zum Hinzufügen eines neuen DB-Knotens die Funktion addInstances() und geben Sie den Host an:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Folgendes würden Sie erhalten, wenn Sie eine neue Instanz hinzufügen:
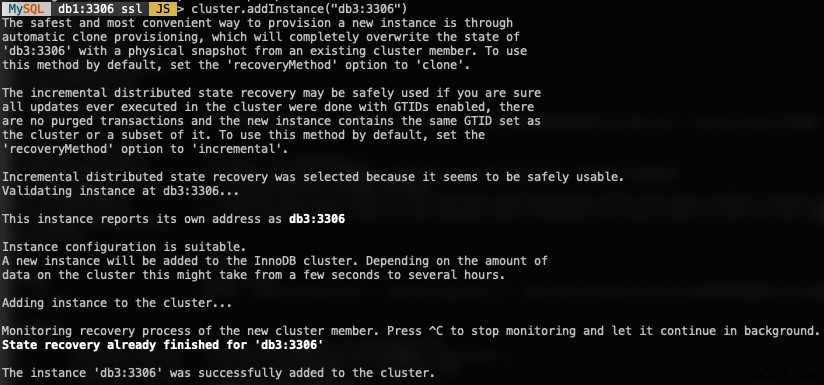
Überprüfen Sie die neue Clustergröße mit:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router nimmt den hinzugefügten Knoten db3 automatisch in das Lastverteilungsset auf.
Herunterskalieren (Entfernen eines Knotens)
Um einen Knoten zu entfernen, verbinden Sie sich mit einem der DB-Knoten außer dem, den wir entfernen werden, und verwenden Sie die Funktion removeInstance() mit dem Namen der Datenbankinstanz:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Das Folgende erhalten Sie, wenn Sie eine Instanz entfernen:
Überprüfen Sie die neue Clustergröße mit:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router schließt automatisch den entfernten Knoten db3 aus dem Lastausgleichssatz aus.
Neuen Replikations-Slave hinzufügen
Wir können den InnoDB-Cluster mit asynchronen Replikations-Slave-Replikaten von jedem der Cluster-Knoten skalieren. Ein Slave ist lose mit dem Cluster gekoppelt und kann eine hohe Last bewältigen, ohne die Leistung des Clusters zu beeinträchtigen. Der Slave kann auch eine Live-Kopie der Datenbank für Notfallwiederherstellungszwecke sein. Im Multi-Primary-Modus können Sie den Slave als dedizierten MySQL-Nur-Lese-Prozessor verwenden, um die Leselast zu skalieren, Analysevorgänge durchzuführen oder als dedizierten Backup-Server.
Laden Sie auf dem Slave-Server das neueste APT-Konfigurationspaket herunter, installieren Sie es (wählen Sie MySQL 8.0 im Konfigurationsassistenten), installieren Sie den APT-Schlüssel, aktualisieren Sie repolist und installieren Sie den MySQL-Server.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellÄndern Sie die MySQL-Konfigurationsdatei, um den Server für den Replikations-Slave vorzubereiten. Öffnen Sie die Konfigurationsdatei per Texteditor:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfUnd fügen Sie die folgenden Zeilen hinzu:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Starten Sie den MySQL-Server auf dem Slave neu, um die Änderungen zu übernehmen:
$ systemctl restart mysqlErstellen Sie auf einem der InnoDB-Cluster-Server (wir haben db3 gewählt) einen Replikations-Slave-Benutzer, gefolgt von einem vollständigen MySQL-Dump:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlÜbertrage die Dump-Datei von db3 auf den Slave:
$ scp dump.sql example@sqldat.com:~Und führen Sie die Wiederherstellung auf dem Slave durch:
$ mysql -uroot -p < dump.sqlMit master-data=1 konfiguriert unsere MySQL-Dump-Datei automatisch den ausgeführten und gelöschten GTID-Wert. Wir können dies nach der Wiederherstellung mit der folgenden Anweisung auf dem Slave-Server überprüfen:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Sieht gut aus. Wir können dann den Replikationslink konfigurieren und die Replikationsthreads auf dem Slave starten:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Überprüfen Sie den Replikationsstatus und stellen Sie sicher, dass der folgende Status „Ja“ zurückgibt:
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
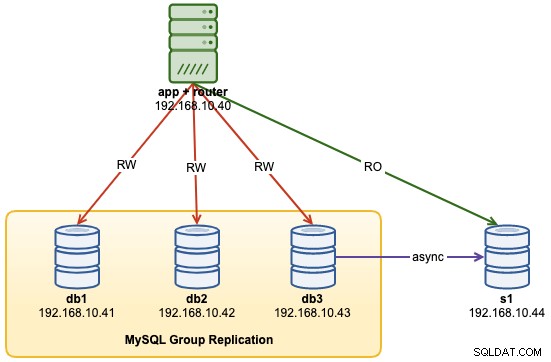
...An diesem Punkt sieht unsere Architektur nun so aus:
Häufige Probleme mit MySQL InnoDB-Clustern
Speichererschöpfung
Bei der Verwendung von MySQL Shell mit MySQL 8.0 erhielten wir ständig den folgenden Fehler, wenn die Instanzen mit 1 GB RAM konfiguriert waren:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Das Aufrüsten des RAM jedes Hosts auf 2 GB RAM löste das Problem. Anscheinend benötigen MySQL 8.0-Komponenten mehr RAM, um effizient zu arbeiten.
Verbindung zum MySQL-Server unterbrochen
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Fazit
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).