In diesem Artikel konzentrieren wir uns auf operative Echtzeitanalysen und die Anwendung dieses Ansatzes auf eine OLTP-Datenbank. Wenn wir uns das herkömmliche Analysemodell ansehen, sehen wir, dass OLTP und Analyseumgebungen separate Strukturen sind. Zunächst einmal müssen die traditionellen analytischen Modellumgebungen ETL-Aufgaben (Extract, Transform and Load) erstellen. Weil wir Transaktionsdaten in das Data Warehouse übertragen müssen. Diese Architekturtypen haben einige Nachteile. Sie sind Kosten, Komplexität und Datenlatenz. Um diese Nachteile zu beseitigen, brauchen wir einen anderen Ansatz.
Betriebsanalysen in Echtzeit
Microsoft hat Real-Time Operational Analytics in SQL Server 2016 angekündigt. Die Fähigkeit dieser Funktion besteht darin, die Arbeitslast von Transaktionsdatenbanken und analytischen Abfragen ohne Leistungsprobleme zu kombinieren. Real-Time Operational Analytics bietet:
- Hybridstruktur
- Transaktions- und Analyseabfragen können gleichzeitig ausgeführt werden
- verursacht keine Leistungs- und Latenzprobleme.
- eine einfache Implementierung.
Diese Funktion kann die Nachteile der traditionellen Analyseumgebung überwinden. Das Hauptthema dieser Funktion besteht darin, dass der Spaltenspeicherindex eine Kopie der Daten verwaltet, ohne die Leistung des Transaktionssystems zu beeinträchtigen. Mit diesem Design können die analytischen Abfragen ausgeführt werden, ohne die Leistung zu beeinträchtigen. Dadurch werden die Auswirkungen auf die Leistung minimiert. Die Haupteinschränkung dieser Funktion besteht darin, dass wir keine Daten aus verschiedenen Datenquellen sammeln können.
Non-Clustered Column Store Index
SQL Server 2016 führt den aktualisierbaren „Non-Clustered Column Store Index“ ein. Der Non-Clustered Column Store Index ist ein spaltenbasierter Index, der Leistungsvorteile für analytische Abfragen bietet. Mit dieser Funktion können wir das Rahmenwerk für operative Analysen in Echtzeit erstellen. Das bedeutet, dass wir Transaktionen und analytische Abfragen gleichzeitig ausführen können. Bedenken Sie, dass wir den monatlichen Gesamtumsatz benötigen. In einem traditionellen Modell müssen wir ETL-Aufgaben, Data Mart und Data Warehouse entwickeln. Bei der operativen Echtzeitanalyse können wir dies jedoch tun, ohne dass ein Data Warehouse oder Änderungen an der OLTP-Struktur erforderlich sind. Wir müssen nur einen geeigneten Non-Clustered Column Store Index erstellen.
Architektur des nicht geclusterten Spaltenspeicherindex
Sehen wir uns kurz die Architektur des nicht geclusterten Spaltenspeicherindex und des Ausführungsmechanismus an. Der nicht gruppierte Spaltenspeicherindex enthält eine Kopie eines Teils oder aller Zeilen und Spalten in der zugrunde liegenden Tabelle. Das Hauptthema des nicht gruppierten Column Store-Index besteht darin, eine Kopie der Daten zu verwalten und diese Kopie der Daten zu verwenden. Dieser Mechanismus minimiert also die Auswirkungen auf die Leistung der Transaktionsdatenbank. Der nicht gruppierte Spaltenspeicherindex kann eine oder mehrere Spalten erstellen und einen Filter auf Spalten anwenden.
Wenn wir eine neue Zeile in eine Tabelle einfügen, die einen nicht gruppierten Spaltenspeicherindex hat, erstellt SQL Server zunächst eine „Zeilengruppe“. Rowgroup ist eine logische Struktur, die eine Reihe von Zeilen darstellt. Anschließend speichert SQL Server diese Zeilen in einem temporären Speicher. Der Name dieses Zwischenspeichers lautet „deltastore“. SQL Server verwendet diesen temporären Speicherbereich, da dieser Mechanismus das Komprimierungsverhältnis verbessert und die Indexfragmentierung verringert. Wenn die Anzahl der Zeilen 1.048.577 erreicht, schließt SQL Server den Zustand der Zeilengruppe. SQL Server komprimiert diese Zeilengruppe und ändert den Status in „komprimiert“.
Jetzt erstellen wir eine Tabelle und fügen den nicht geclusterten Spaltenspeicherindex hinzu.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
In diesem Schritt fügen wir mehrere Zeilen ein und sehen uns die Eigenschaften des nicht geclusterten Spaltenspeicherindex an.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Diese Abfrage zeigt den Status der Zeilengruppe, die Gesamtzahl der Zeilengröße und andere Werte an.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

Das obige Bild zeigt uns den Deltastore-Status und die Gesamtzahl der Zeilen, die nicht komprimiert sind. Jetzt füllen wir mehr Daten in die Tabelle und wenn die Anzahl der Zeilen 1.048.577 erreicht, schließt SQL Server die erste Zeilengruppe und öffnet eine neue Zeilengruppe.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server komprimiert diese Zeilengruppe und erstellt eine neue Zeilengruppe. Mit der Option „COMPRESSION_DELAY“ können wir steuern, wie lange die Zeilengruppe im geschlossenen Status wartet.

Wenn wir die Indexpflegebefehle ausführen (reorganize, rebuild), werden die gelöschten Zeilen physisch entfernt und der Index defragmentiert.

Wenn wir einige Zeilen in dieser Tabelle aktualisieren (löschen + einfügen), werden die gelöschten Zeilen als „gelöscht“ markiert und neue aktualisierte Zeilen werden in den Deltastore eingefügt.
Leistungsbenchmark für analytische Abfragen
In dieser Überschrift füllen wir Daten in die Analysis_TableTest-Tabelle. Ich habe 4 Millionen Datensätze eingefügt. (Sie müssen diesen Schritt und die nächsten Schritte in Ihrer Testumgebung testen. Es können Leistungsprobleme auftreten und auch der Befehl DBCC DROPCLEANBUFFERS kann die Leistung beeinträchtigen. Dieser Befehl entfernt alle Pufferdaten aus dem Pufferpool.)
Jetzt führen wir die folgende analytische Abfrage aus und untersuchen die Leistungswerte.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

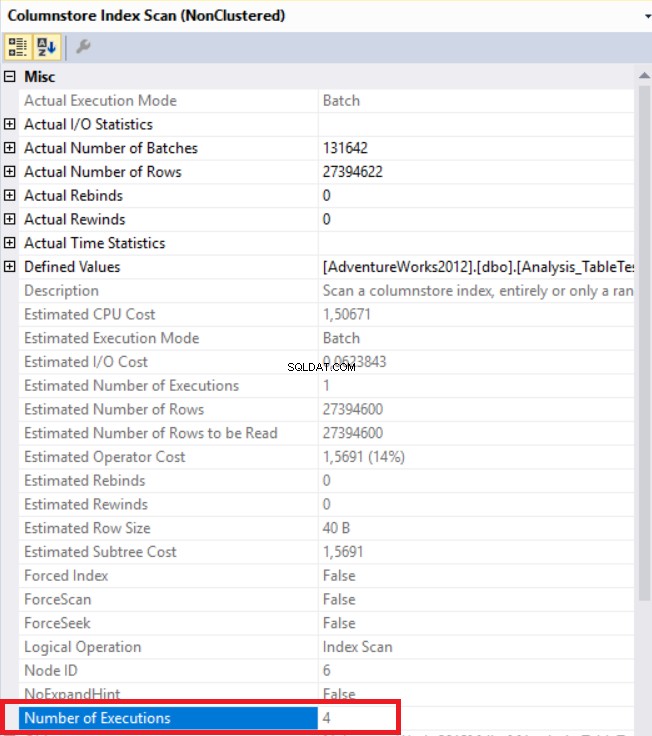
In der obigen Abbildung sehen wir den Non-Clustered-Column-Store-Index-Scan-Operator. Die folgende Tabelle zeigt CPU- und Ausführungszeiten. Diese Abfrage verbraucht 1,765 Millisekunden CPU und ist in 0,791 Millisekunden abgeschlossen. Die CPU-Zeit ist größer als die verstrichene Zeit, da der Ausführungsplan parallele Prozessoren verwendet und Aufgaben auf 4 Prozessoren verteilt. Wir können es in den Eigenschaften des Operators „Columnstore Index Scan“ sehen. Der Wert „Anzahl der Ausführungen“ zeigt dies an.

Jetzt fügen wir der Abfrage einen Hinweis hinzu, um die Anzahl der Prozessoren zu reduzieren. Wir werden keinen Parallelitätsoperator sehen.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)
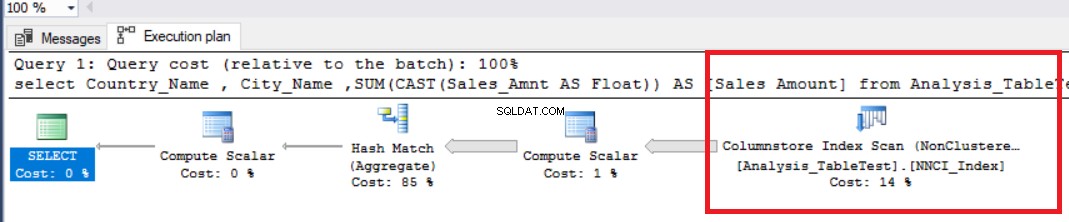

Die folgende Tabelle definiert Ausführungszeiten. In diesem Diagramm können wir sehen, dass die verstrichene Zeit größer ist als die CPU-Zeit, da SQL Server nur einen Prozessor verwendet.
Jetzt deaktivieren wir den nicht geclusterten Spaltenspeicherindex und führen dieselbe Abfrage aus.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

Die obige Tabelle zeigt uns, dass der nicht gruppierte Spaltenspeicherindex eine unglaubliche Leistung bei analytischen Abfragen bietet. Die indizierte Column Store-Abfrage ist ungefähr fünfmal besser als die andere.
Schlussfolgerung
Real-Time Operational Analytics bietet eine unglaubliche Flexibilität, da wir analytische Abfragen in OLTP-Systemen ohne Datenlatenz ausführen können. Gleichzeitig beeinträchtigen diese analytischen Abfragen nicht die Performance der OLTP-Datenbank. Diese Funktion gibt uns die Möglichkeit, Transaktionsdaten und analytische Abfragen in derselben Umgebung zu verwalten.
Referenzen
Column Store-Indizes – Anleitung zum Laden von Daten
Beginnen Sie mit Column Store für Betriebsanalysen in Echtzeit
Betriebsanalysen in Echtzeit
Weiterführende Literatur:
SQL Server Index Backward Scan:Verstehen, Optimieren
Verwenden von Indizes in speicheroptimierten SQL Server-Tabellen