SQL-FALL? Kinderleicht!
Wirklich?
Nicht, bis Sie auf 3 lästige Probleme stoßen, die Laufzeitfehler und langsame Leistung verursachen können.
Wenn Sie versuchen, die Unterüberschriften zu durchsuchen, um zu sehen, was die Probleme sind, kann ich Ihnen keine Vorwürfe machen. Leser, mich eingeschlossen, sind ungeduldig.
Ich vertraue darauf, dass Sie die Grundlagen von SQL CASE bereits kennen, daher werde ich Sie nicht mit langen Einführungen langweilen. Lassen Sie uns in ein tieferes Verständnis dessen eintauchen, was unter der Haube passiert.
1. SQL CASE wertet nicht immer sequentiell aus
Ausdrücke in der Microsoft SQL CASE-Anweisung werden meistens sequentiell oder von links nach rechts ausgewertet. Es ist jedoch eine andere Geschichte, wenn es mit Aggregatfunktionen verwendet wird. Nehmen wir ein Beispiel:
-- aggregate function evaluated first and generated an error
DECLARE @value INT = 0;
SELECT CASE WHEN @value = 0 THEN 1 ELSE MAX(1/@value) END;
Der obige Code sieht normal aus. Wenn ich Sie frage, was das Ergebnis dieser Anweisungen ist, werden Sie wahrscheinlich 1 sagen. Die visuelle Inspektion sagt uns das, weil @value auf 0 gesetzt ist. Wenn @value 0 ist, ist das Ergebnis 1.
Aber das ist hier nicht der Fall. Sehen Sie sich das echte Ergebnis von SQL Server Management Studio an:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
Aber warum?
Wenn bedingte Ausdrücke Aggregatfunktionen wie MAX() in SQL CASE verwenden, werden sie zuerst ausgewertet. Daher verursacht MAX(1/@value) einen Fehler bei der Division durch Null, da @value gleich Null ist.
Diese Situation ist problematischer, wenn sie versteckt ist. Ich erkläre es später.
2. Einfacher SQL-CASE-Ausdruck wird mehrfach ausgewertet
Na und?
Gute Frage. Die Wahrheit ist, dass es überhaupt keine Probleme gibt, wenn Sie Literale oder einfache Ausdrücke verwenden. Aber wenn Sie Unterabfragen als bedingten Ausdruck verwenden, werden Sie eine große Überraschung erleben.
Bevor Sie das folgende Beispiel ausprobieren, möchten Sie vielleicht eine Kopie der Datenbank von hier aus wiederherstellen. Wir werden es für die restlichen Beispiele verwenden.
Betrachten Sie nun diese sehr einfache Abfrage:
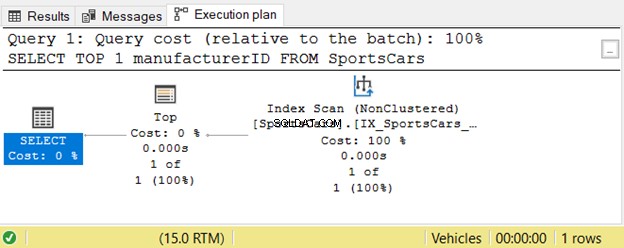
SELECT TOP 1 manufacturerID FROM SportsCars
Es ist ganz einfach, oder? Es gibt 1 Zeile mit 1 Datenspalte zurück. Das STATISTICS IO zeigt minimale logische Lesevorgänge.
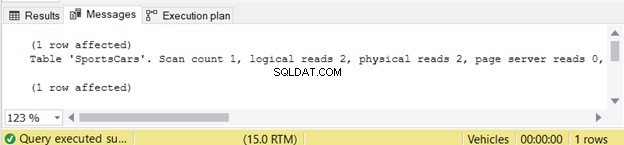
Kurznotiz :Für Uneingeweihte:Höhere logische Lesevorgänge machen eine Abfrage langsam. Lesen Sie dies für weitere Details.
Der Ausführungsplan zeigt auch einen einfachen Prozess:
Lassen Sie uns diese Abfrage nun als Unterabfrage in einen CASE-Ausdruck einfügen:
-- Using a subquery in a SQL CASE
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE (SELECT TOP 1 manufacturerID FROM SportsCars)
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Analyse
Drücken Sie die Daumen, denn dies wird logische Lesevorgänge viermal umhauen.
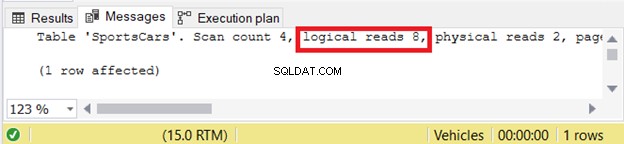
Überraschung! Im Vergleich zu Abbildung 1 mit nur 2 logischen Lesevorgängen ist dies 4-mal höher. Somit ist die Abfrage 4-mal langsamer. Wie konnte das passieren? Wir haben die Unterabfrage nur einmal gesehen.
Aber das ist noch nicht das Ende der Geschichte. Sehen Sie sich den Ausführungsplan an:
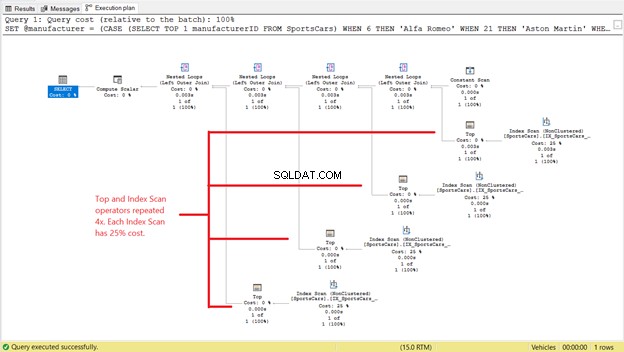
Wir sehen 4 Instanzen der Top- und Index-Scan-Operatoren in Abbildung 4. Wenn jeder Top- und Index-Scan 2 logische Lesevorgänge verbraucht, erklärt das, warum die logischen Lesevorgänge in Abbildung 3 zu 8 wurden. Und da jeder Top- und Index-Scan 25 % Kosten verursacht , es sagt uns auch, dass sie gleich sind.
Aber es endet nicht dort. Die Eigenschaften des Compute Scalar-Operators zeigen, wie die gesamte Anweisung behandelt wird.
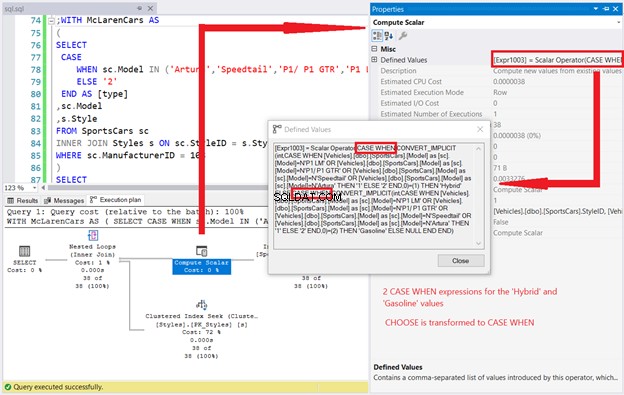
Wir sehen 4 CASE WHEN-Ausdrücke, die von den definierten Werten des Compute Scalar-Operators stammen. Sieht so aus, als wäre unser einfacher CASE-Ausdruck ein gesuchter CASE-Ausdruck wie dieser geworden:
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 6 THEN 'Alfa Romeo'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 21 THEN 'Aston Martin'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 64 THEN 'Ferrari'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Lassen Sie uns rekapitulieren. Es gab 2 logische Lesevorgänge für jeden Top- und Index-Scan-Operator. Dies multipliziert mit 4 ergibt 8 logische Lesevorgänge. Wir haben auch 4 CASE WHEN-Ausdrücke im Compute Scalar-Operator gesehen.
Am Ende wurde die Unterabfrage im einfachen CASE-Ausdruck viermal ausgewertet. Dadurch verzögert sich Ihre Anfrage.
Wie man mehrere Auswertungen einer Unterabfrage in einem einfachen CASE-Ausdruck vermeidet
Um solche Leistungsprobleme wie mehrere CASE-Anweisungen in SQL zu vermeiden, müssen wir die Abfrage neu schreiben.
Legen Sie zuerst das Ergebnis der Unterabfrage in eine Variable. Verwenden Sie diese Variable dann in der Bedingung des einfachen SQL Server-CASE-Ausdrucks wie folgt:
DECLARE @manufacturer NVARCHAR(50)
DECLARE @ManufacturerID INT -- create a new variable
-- store the result of the subquery in a variable
SET @ManufacturerID = (SELECT TOP 1 manufacturerID FROM SportsCars)
-- use the new variable in the simple CASE expression
SET @manufacturer = (CASE @ManufacturerID
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Ist das eine gute Lösung? Sehen wir uns die logischen Lesevorgänge in STATISTICS IO:
an
Wir sehen niedrigere logische Lesevorgänge aus der modifizierten Abfrage. Es ist viel besser, die Unterabfrage herauszunehmen und das Ergebnis einer Variablen zuzuweisen. Wie sieht es mit dem Ausführungsplan aus? Siehe unten.
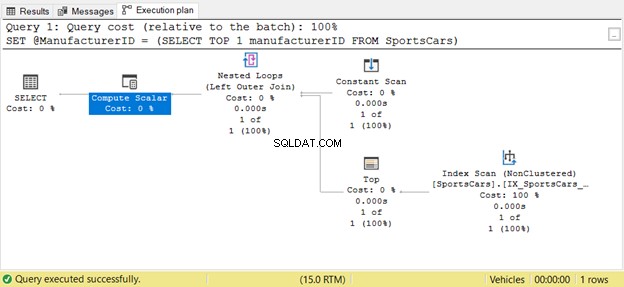
Der Top- und Index-Scan-Operator erschien nur einmal, nicht viermal. Wunderbar!
Imbiss :Verwenden Sie keine Unterabfrage als Bedingung im CASE-Ausdruck. Wenn Sie einen Wert abrufen müssen, fügen Sie das Ergebnis der Unterabfrage zuerst in eine Variable ein. Verwenden Sie dann diese Variable im CASE-Ausdruck.
3. Diese 3 eingebauten Funktionen verwandeln sich heimlich in SQL CASE
Es gibt ein Geheimnis, und die CASE-Anweisung von SQL Server hat etwas damit zu tun. Wenn Sie nicht wissen, wie sich diese 3 Funktionen verhalten, werden Sie nicht wissen, dass Sie einen Fehler begehen, den wir zuvor in den Punkten 1 und 2 versucht haben zu vermeiden. Hier sind sie:
- IIF
- VEREINIGUNG
- WÄHLEN
Sehen wir sie uns nacheinander an.
IIF
Ich habe Immediate IF oder IIF in Visual Basic und Visual Basic for Applications verwendet. Dies entspricht auch dem ternären Operator von C#:
Diese Funktion gibt bei gegebener Bedingung 1 der 2 Argumente basierend auf dem Ergebnis der Bedingung zurück. Und diese Funktion ist auch in T-SQL verfügbar. Die CASE-Anweisung in der WHERE-Klausel kann innerhalb der SELECT-Anweisung verwendet werden
Aber es ist nur ein Zuckermantel eines längeren CASE-Ausdrucks. Woher wissen wir? Sehen wir uns ein Beispiel an.
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'McLaren Senna', 'Yes', 'No');Das Ergebnis dieser Abfrage ist „Nein“. Sehen Sie sich jedoch den Ausführungsplan zusammen mit den Eigenschaften von Compute Scalar an.
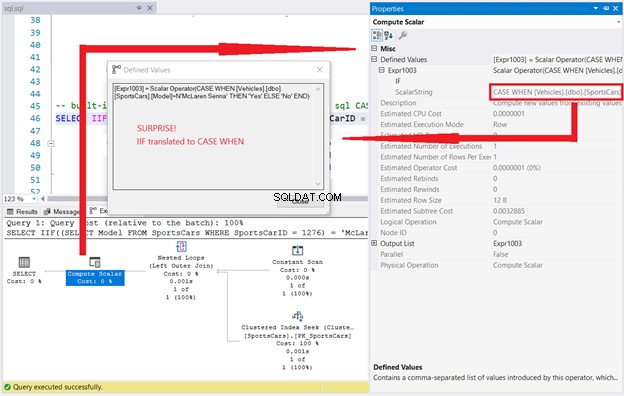
Da IIF CASE WHEN ist, was denkst du, wird passieren, wenn du so etwas ausführst?
DECLARE @averageCost MONEY = 1000000.00;
DECLARE @noOfPayments TINYINT = 0; -- intentional to force the error
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'SF90 Spider', 83333.33,MIN(@averageCost / @noOfPayments));
Dies führt zu einem Divide by Zero-Fehler, wenn @noOfPayments 0 ist. Dasselbe geschah bei Punkt #1 zuvor.
Sie fragen sich vielleicht, was diesen Fehler verursacht, da die obige Abfrage TRUE ergibt und 83333,33 zurückgeben sollte. Überprüfen Sie noch einmal Punkt 1.
Wenn Sie also bei der Verwendung von IIF mit einem Fehler wie diesem stecken bleiben, ist SQL CASE der Übeltäter.
VEREINIGUNG
COALESCE ist auch eine Abkürzung eines SQL CASE-Ausdrucks. Es wertet die Werteliste aus und gibt den ersten Nicht-Nullwert zurück. Im vorherigen Artikel über COALESCE habe ich ein Beispiel vorgestellt, das eine Unterabfrage zweimal auswertet. Aber ich habe eine andere Methode verwendet, um den SQL CASE im Ausführungsplan aufzudecken. Hier ist ein weiteres Beispiel, das dieselben Techniken verwendet.
SELECT
COALESCE(m.Manufacturer + ' ','') + sc.Model AS Car
FROM SportsCars sc
LEFT JOIN Manufacturers m ON sc.ManufacturerID = m.ManufacturerID
Sehen wir uns den Ausführungsplan und die berechneten skalaren definierten Werte an.
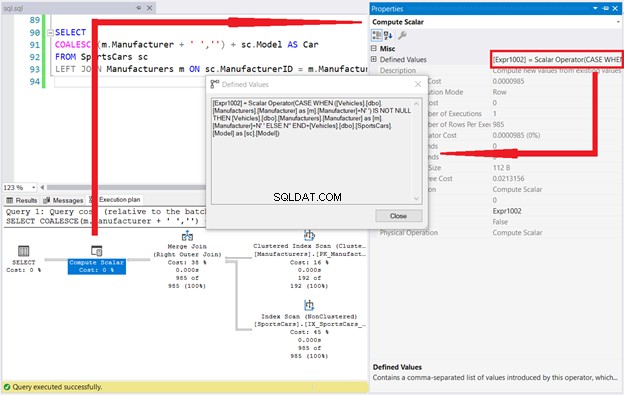
SQL CASE ist in Ordnung. Das Schlüsselwort COALESCE befindet sich nirgendwo im Fenster „Definierte Werte“. Das beweist das Geheimnis hinter dieser Funktion.
Aber das ist nicht alles. Wie oft haben Sie [Fahrzeuge].[dbo].[Stile].[Stil] gesehen im Fenster Definierte Werte? ZWEIMAL! Dies steht im Einklang mit der offiziellen Microsoft-Dokumentation. Stellen Sie sich vor, eines der Argumente in COALESCE wäre eine Unterabfrage. Verdoppeln Sie dann die logischen Lesevorgänge und erhalten Sie auch die langsamere Ausführung.
WÄHLEN
Schließlich WÄHLEN. Dies ähnelt der Funktion AUSWÄHLEN von MS Access. Es gibt 1 Wert aus einer Liste von Werten basierend auf einer Indexposition zurück. Es fungiert auch als Index in einem Array.
Mal sehen, ob wir die Transformation in einen SQL CASE anhand eines Beispiels verstehen können. Sehen Sie sich den folgenden Code an:
;WITH McLarenCars AS
(
SELECT
CASE
WHEN sc.Model IN ('Artura','Speedtail','P1/ P1 GTR','P1 LM') THEN '1'
ELSE '2'
END AS [type]
,sc.Model
,s.Style
FROM SportsCars sc
INNER JOIN Styles s ON sc.StyleID = s.StyleID
WHERE sc.ManufacturerID = 108
)
SELECT
Model
,Style
,CHOOSE([Type],'Hybrid','Gasoline') AS [type]
FROM McLarenCars
Da ist unser CHOOSE-Beispiel. Lassen Sie uns nun den Ausführungsplan und die Compute Scalar Defined Values überprüfen:
Sehen Sie das Schlüsselwort CHOOSE im Fenster „Defined Values“ in Abbildung 10? Wie wäre es mit CASE WHEN?
Wie die vorherigen Beispiele ist diese CHOOSE-Funktion nur ein Zuckerguss für einen längeren CASE-Ausdruck. Und da die Abfrage zwei Elemente für AUSWÄHLEN enthält, wurden die Schlüsselwörter CASE WHEN zweimal angezeigt. Siehe das rot umrandete Fenster "Definierte Werte".
Wir haben hier jedoch mehrere CASE WHEN in SQL. Das liegt am CASE-Ausdruck in der inneren Abfrage des CTE. Wenn Sie genau hinsehen, erscheint dieser Teil der inneren Abfrage auch zweimal.
Imbiss
Jetzt, wo die Geheimnisse gelüftet sind, was haben wir gelernt?
- SQL CASE verhält sich anders, wenn Aggregatfunktionen verwendet werden. Seien Sie vorsichtig, wenn Sie Argumente an Aggregatfunktionen wie MIN, MAX oder COUNT übergeben.
- Ein einfacher CASE-Ausdruck wird mehrfach ausgewertet. Beachten Sie dies und vermeiden Sie es, eine Unterabfrage zu übergeben. Obwohl es syntaktisch korrekt ist, wird es schlecht funktionieren.
- IIF, CHOOSE und COALESCE haben schmutzige Geheimnisse. Denken Sie daran, bevor Sie Werte an diese Funktionen übergeben. Es verwandelt sich in einen SQL CASE. Abhängig von den Werten verursachen Sie entweder einen Fehler oder eine Leistungseinbuße.
Ich hoffe, diese andere Sichtweise auf SQL CASE war für Sie hilfreich. Wenn ja, könnte es Ihren Entwicklerfreunden auch gefallen. Bitte teilen Sie es auf Ihren bevorzugten Social-Media-Plattformen. Und lassen Sie uns im Kommentarbereich wissen, was Sie darüber denken.