In der IT-Branche haben wir das Wort „Failover“ wahrscheinlich schon oft gehört, aber es kann auch Fragen aufwerfen wie:Was ist eigentlich ein Failover? Wofür können wir es verwenden? Ist es wichtig, es zu haben? Wie können wir das tun?
Auch wenn sie ziemlich grundlegende Fragen zu sein scheinen, ist es wichtig, sie in jeder Datenbankumgebung zu berücksichtigen. Und meistens berücksichtigen wir die Grundlagen nicht...
Schauen wir uns zunächst einige grundlegende Konzepte an.
Was ist Failover?
Failover ist die Fähigkeit eines Systems, auch bei einem Ausfall weiter zu funktionieren. Es suggeriert, dass die Funktionen des Systems von sekundären Komponenten übernommen werden, wenn die primären Komponenten ausfallen.
Im Fall von PostgreSQL gibt es verschiedene Tools, mit denen Sie einen ausfallsicheren Datenbankcluster implementieren können. Ein nativ in PostgreSQL verfügbarer Redundanzmechanismus ist die Replikation. Und die Neuheit in PostgreSQL 10 ist die Implementierung der logischen Replikation.
Was ist Replikation?
Es ist der Vorgang des Kopierens und Aktualisierens der Daten in einem oder mehreren Datenbankknoten. Es verwendet ein Konzept eines Master-Knotens, der die Änderungen empfängt, und Slave-Knoten, auf denen sie repliziert werden.
Wir haben mehrere Möglichkeiten, die Replikation zu kategorisieren:
- Synchrone Replikation:Es gibt keinen Datenverlust, auch wenn unser Master-Knoten verloren geht, aber die Commits im Master müssen auf eine Bestätigung vom Slave warten, was die Leistung beeinträchtigen kann.
- Asynchrone Replikation:Es besteht die Möglichkeit eines Datenverlusts, falls wir unseren Masterknoten verlieren. Wenn die Replik aus irgendeinem Grund zum Zeitpunkt des Vorfalls nicht aktualisiert wird, können die nicht kopierten Informationen verloren gehen.
- Physische Replikation:Plattenblöcke werden kopiert.
- Logische Replikation:Streaming der Datenänderungen.
- Warm-Standby-Slaves:Sie unterstützen keine Verbindungen.
- Hot Standby Slaves:Unterstützt Nur-Lese-Verbindungen, nützlich für Berichte oder Abfragen.
Wofür wird Failover verwendet?
Es gibt mehrere mögliche Verwendungen von Failover. Sehen wir uns einige Beispiele an.
Migration
Wenn wir von einem Rechenzentrum zu einem anderen migrieren möchten, indem wir unsere Ausfallzeiten minimieren, können wir Failover verwenden.
Angenommen, unser Master befindet sich im Rechenzentrum A und wir möchten unsere Systeme in das Rechenzentrum B migrieren.
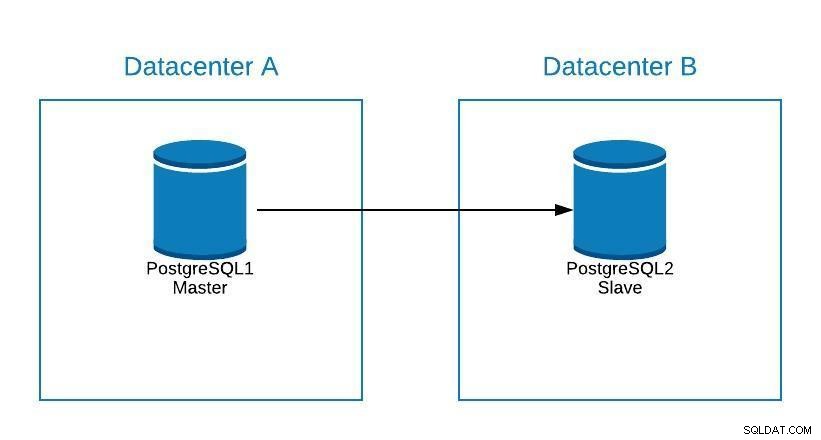 Migrationsdiagramm 1
Migrationsdiagramm 1 Wir können ein Replikat in Rechenzentrum B erstellen. Sobald es synchronisiert ist, müssen wir unser System anhalten, unser Replikat auf einen neuen Master hochstufen und ein Failover durchführen, bevor wir unser System auf den neuen Master in Rechenzentrum B verweisen.
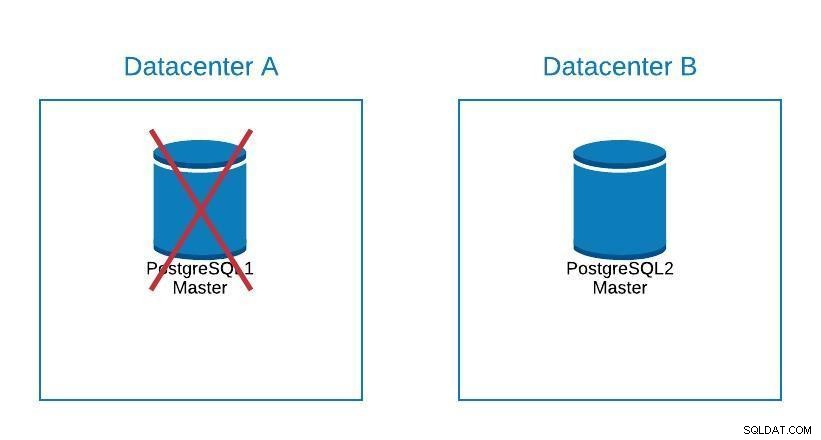 Migrationsdiagramm 2
Migrationsdiagramm 2 Beim Failover geht es nicht nur um die Datenbank, sondern auch um die Anwendung(en). Woher wissen sie, mit welcher Datenbank sie sich verbinden müssen? Wir möchten unsere Anwendung sicherlich nicht ändern müssen, da dies nur unsere Ausfallzeit verlängert. Wir können also einen Load Balancer so konfigurieren, dass er beim Herunterfahren unseres Masters automatisch auf den nächsten hochgestuften Server zeigt.
Eine weitere Option ist die Verwendung von DNS. Indem wir das Master-Replikat im neuen Rechenzentrum hochstufen, ändern wir direkt die IP-Adresse des Hostnamens, der auf den Master verweist. Auf diese Weise vermeiden wir, dass wir unsere Anwendung ändern müssen, und obwohl dies nicht automatisch möglich ist, ist es eine Alternative, wenn wir keinen Load Balancer implementieren möchten.
Eine einzelne Load-Balancer-Instanz zu haben ist nicht gut, da sie zu einem Single Point of Failure werden kann. Daher können Sie auch ein Failover für den Load Balancer implementieren, indem Sie einen Dienst wie Keepalived verwenden. Wenn wir also ein Problem mit unserem primären Load Balancer haben, ist keepalived dafür verantwortlich, die IP auf unseren sekundären Load Balancer zu migrieren, und alles funktioniert weiterhin transparent.
Wartung
Wenn wir Wartungsarbeiten an unserem PostgreSQL-Master-Datenbankserver durchführen müssen, können wir unseren Slave hochstufen, die Aufgabe ausführen und einen Slave auf unserem alten Master rekonstruieren.
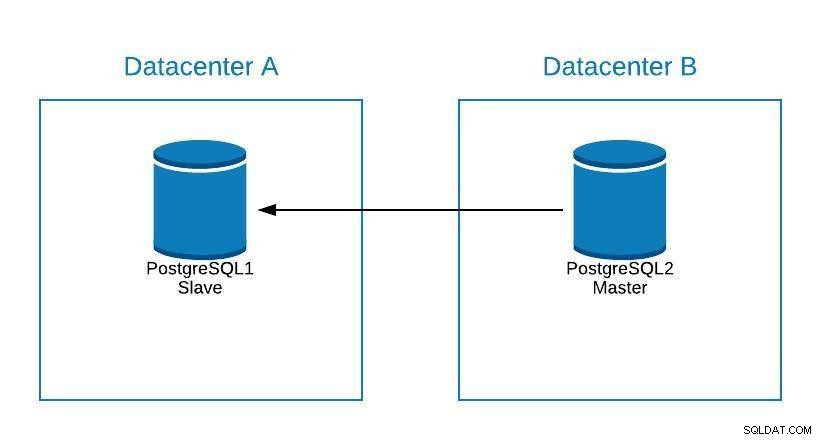 Wartungsdiagramm 1
Wartungsdiagramm 1 Danach können wir den alten Meister erneut befördern und den Wiederherstellungsprozess des Sklaven wiederholen, wobei wir zum ursprünglichen Zustand zurückkehren.
Wartungsdiagramm 2 Auf diese Weise konnten wir an unserem Server arbeiten, ohne Gefahr zu laufen, während der Wartung offline zu sein oder Informationen zu verlieren.
Upgrade
Obwohl PostgreSQL 11 noch nicht verfügbar ist, wäre es technisch möglich, ein Upgrade von PostgreSQL Version 10 mithilfe der logischen Replikation durchzuführen, wie es mit anderen Engines möglich ist.
Die Schritte wären die gleichen wie bei der Migration zu einem neuen Rechenzentrum (siehe Abschnitt Migration), nur dass unser Slave in PostgreSQL 11 wäre.
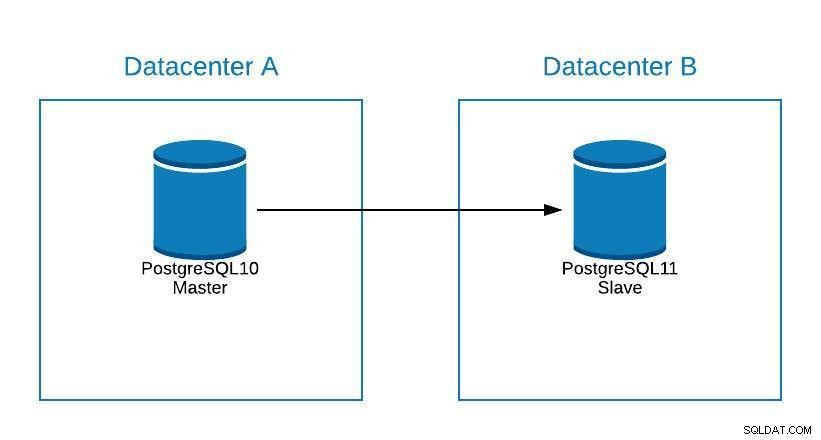 Upgrade-Diagramm 1
Upgrade-Diagramm 1 Probleme
Die wichtigste Funktion des Failover besteht darin, unsere Ausfallzeiten zu minimieren oder Informationsverluste zu vermeiden, wenn ein Problem mit unserer Hauptdatenbank auftritt.
Wenn wir aus irgendeinem Grund unsere Master-Datenbank verlieren, können wir ein Failover durchführen, um unseren Slave zum Master zu machen, und unsere Systeme am Laufen halten.
Dazu stellt uns PostgreSQL keine automatisierte Lösung zur Verfügung. Wir können dies manuell tun oder es mithilfe eines Skripts oder eines externen Tools automatisieren.
Um unseren Sklaven zum Meister zu machen:
-
Führen Sie pg_ctl promote
ausbash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Erstellen Sie eine Datei trigger_file, die wir in der recovery.conf unseres Datenverzeichnisses hinzugefügt haben müssen.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Um eine Failover-Strategie zu implementieren, müssen wir sie planen und gründlich durch verschiedene Ausfallszenarien testen. Da Fehler auf unterschiedliche Weise auftreten können, sollte die Lösung idealerweise für die meisten gängigen Szenarien funktionieren. Wenn wir nach einer Möglichkeit suchen, dies zu automatisieren, können wir uns ansehen, was ClusterControl zu bieten hat.
ClusterControl für PostgreSQL-Failover
ClusterControl verfügt über eine Reihe von Funktionen im Zusammenhang mit PostgreSQL-Replikation und automatisiertem Failover.
Sklave hinzufügen
Wenn wir einen Slave in einem anderen Rechenzentrum hinzufügen möchten, entweder als Notfall oder um Ihre Systeme zu migrieren, können wir zu Cluster-Aktionen gehen und Replikations-Slave hinzufügen auswählen.
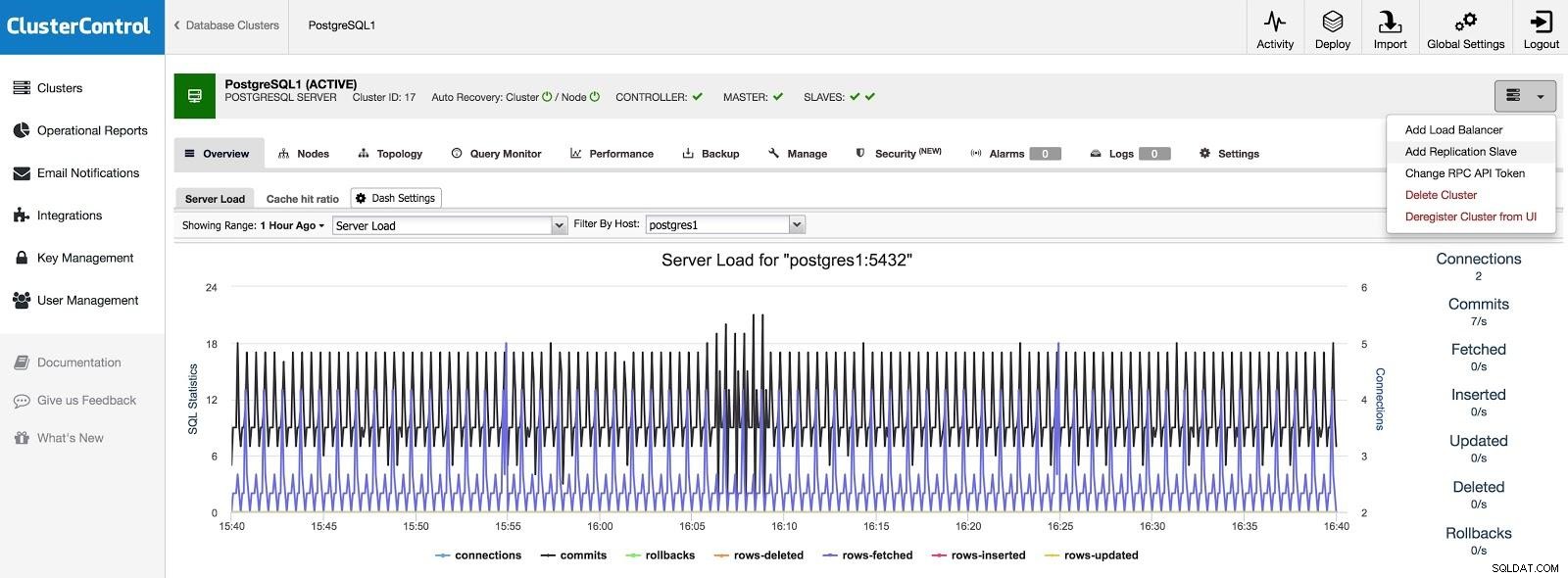 ClusterControl fügt Slave 1 hinzu
ClusterControl fügt Slave 1 hinzu Wir müssen einige grundlegende Daten eingeben, wie z. B. IP oder Hostname, Datenverzeichnis (optional), synchroner oder asynchroner Slave. Nach ein paar Sekunden sollte unser Slave einsatzbereit sein.
Bei Verwendung eines anderen Rechenzentrums empfehlen wir, einen asynchronen Slave anzulegen, da sonst die Latenz die Performance erheblich beeinträchtigen kann.
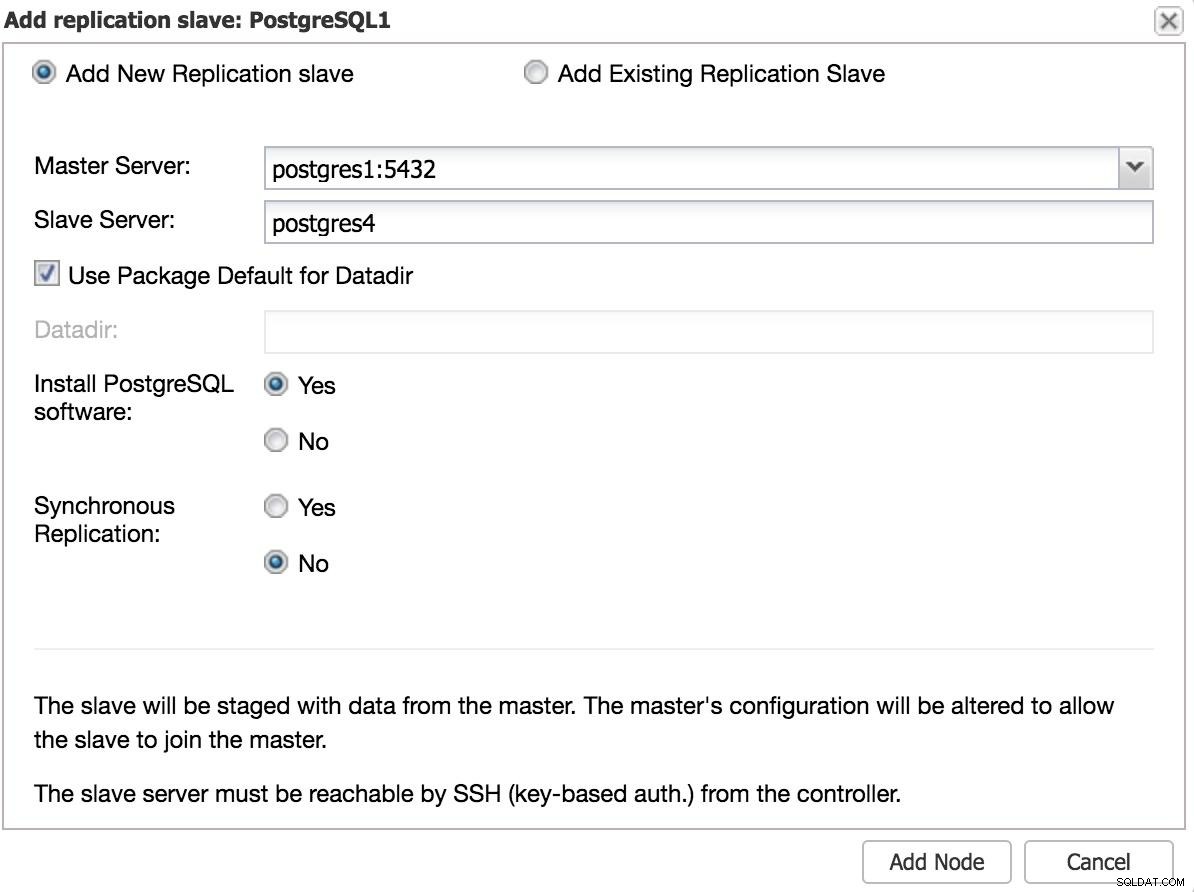 ClusterControl fügt Slave 2 hinzu
ClusterControl fügt Slave 2 hinzu Manuelles Failover
Mit ClusterControl kann Failover manuell oder automatisch erfolgen.
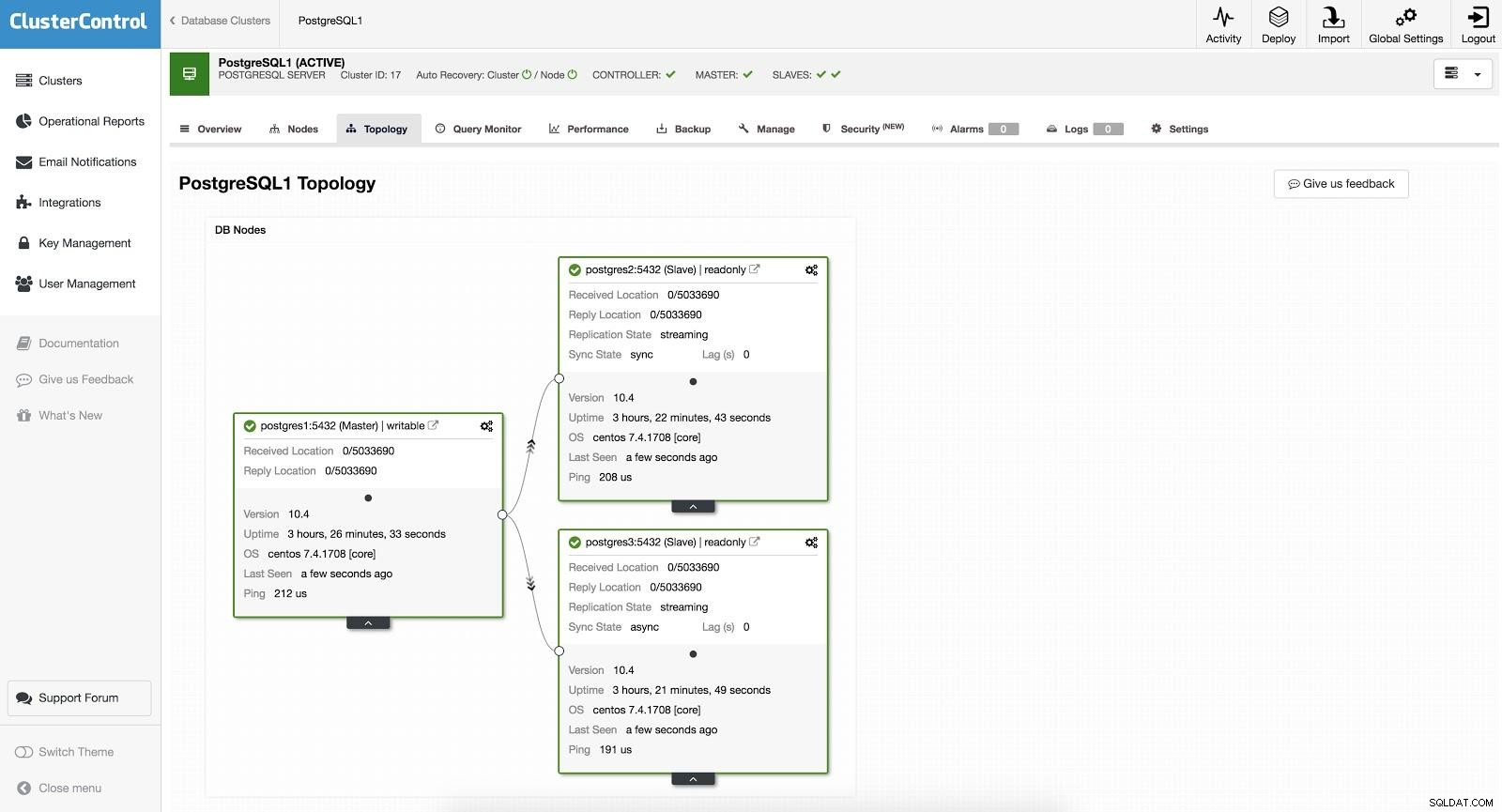 ClusterControl-Failover 1
ClusterControl-Failover 1 Um ein manuelles Failover durchzuführen, gehen Sie zu ClusterControl -> Select Cluster -> Nodes und wählen Sie im Action Node eines unserer Slaves „Promote Slave“. Auf diese Weise wird unser Sklave nach ein paar Sekunden Herr, und was vorher unser Herr war, wird zu einem Sklaven.
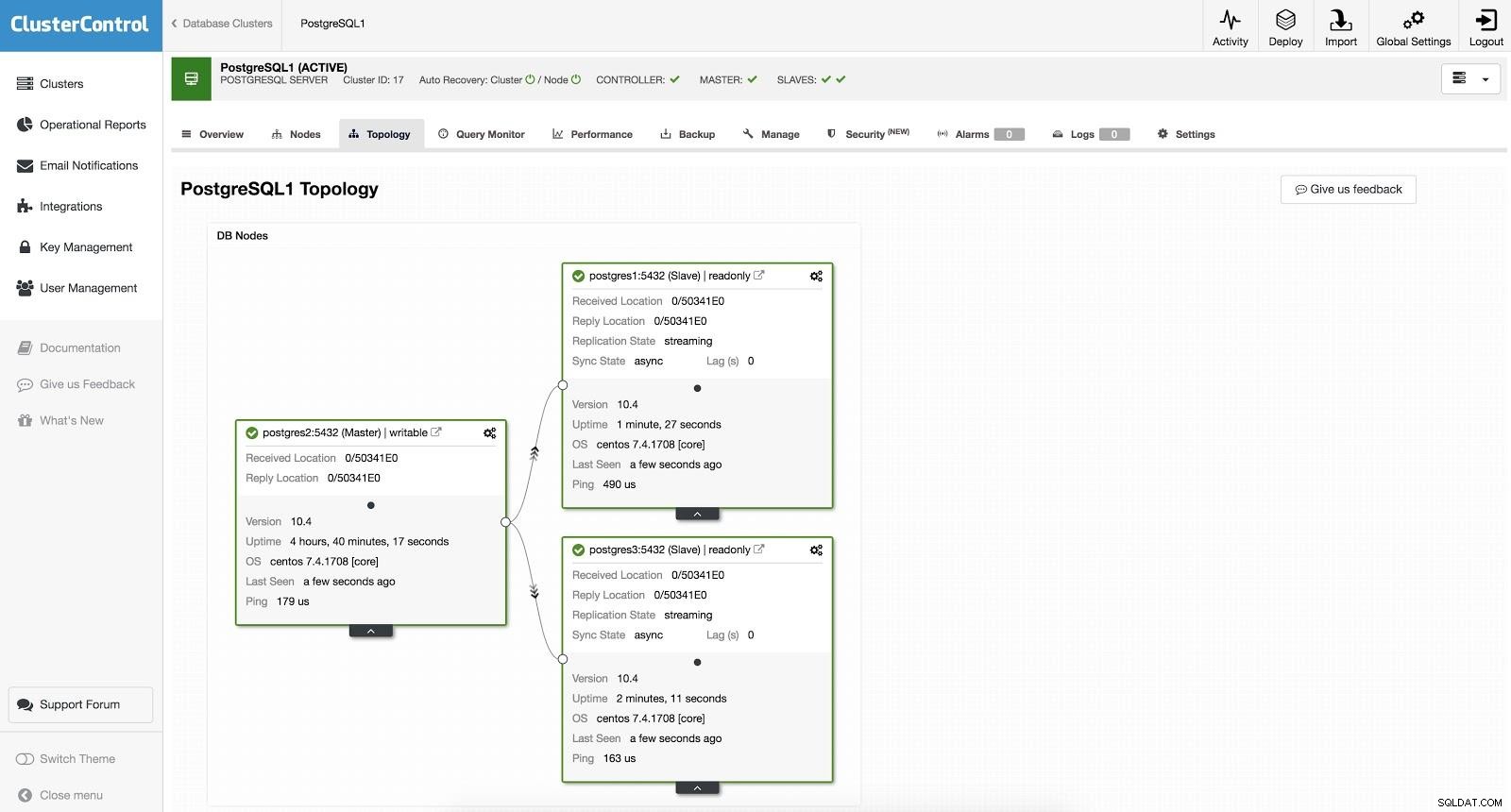 ClusterControl-Failover 2
ClusterControl-Failover 2 Das Obige ist nützlich für die Aufgaben der Migration, Wartung und Upgrades, die wir zuvor gesehen haben.
Automatisches Failover
Beim automatischen Failover erkennt ClusterControl Ausfälle im Master und befördert einen Slave mit den aktuellsten Daten zum neuen Master. Es funktioniert auch bei den restlichen Slaves, um sie vom neuen Master zu replizieren.
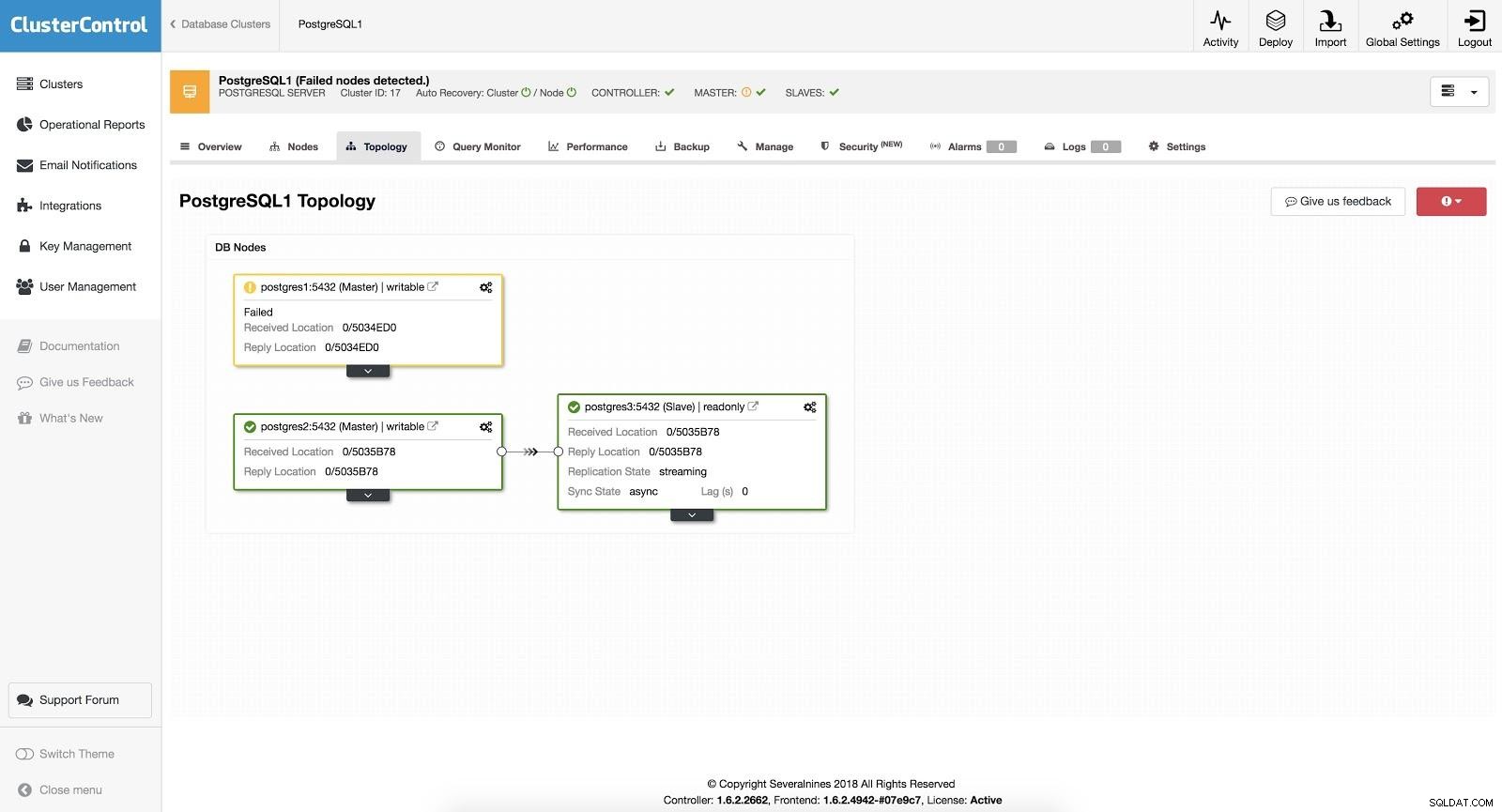 ClusterControl-Failover 3
ClusterControl-Failover 3 Wenn die Option „Autorecovery“ aktiviert ist, führt unser ClusterControl ein automatisches Failover durch und benachrichtigt uns über das Problem. Auf diese Weise können unsere Systeme innerhalb von Sekunden und ohne unser Eingreifen wiederhergestellt werden.
Cluster Control bietet uns die Möglichkeit, eine Whitelist/Blacklist zu konfigurieren, um zu definieren, wie unsere Server bei der Entscheidung für einen Master-Kandidaten berücksichtigt (oder nicht) berücksichtigt werden sollen.
Aus den gemäß der obigen Konfiguration verfügbaren Slaves wählt ClusterControl den am weitesten fortgeschrittenen Slave aus und verwendet zu diesem Zweck je nach Version unserer Datenbank pg_current_xlog_location (PostgreSQL 9+) oder pg_current_wal_lsn (PostgreSQL 10+).
ClusterControl führt auch mehrere Überprüfungen des Failover-Prozesses durch, um einige häufige Fehler zu vermeiden. Ein Beispiel ist, dass, wenn es uns gelingt, unseren alten ausgefallenen Master wiederherzustellen, dieser NICHT automatisch wieder in den Cluster eingeführt wird, weder als Master noch als Slave. Wir müssen es manuell tun. Dadurch wird die Möglichkeit eines Datenverlusts oder einer Inkonsistenz vermieden, falls unser Slave (den wir befördert haben) zum Zeitpunkt des Ausfalls verzögert war. Möglicherweise möchten wir das Problem auch im Detail analysieren, aber wenn wir es zu unserem Cluster hinzufügen, würden wir möglicherweise Diagnoseinformationen verlieren.
Wenn das Failover fehlschlägt, werden keine weiteren Versuche unternommen, es ist ein manueller Eingriff erforderlich, um das Problem zu analysieren und die entsprechenden Maßnahmen durchzuführen. Dadurch soll vermieden werden, dass ClusterControl als Hochverfügbarkeitsmanager versucht, den nächsten Slave und den nächsten zu promoten. Möglicherweise liegt ein Problem vor, und wir möchten die Situation nicht verschlimmern, indem wir mehrere Failover versuchen.
Load-Balancer
Wie bereits erwähnt, ist der Load Balancer ein wichtiges Tool, das für unser Failover in Betracht gezogen werden sollte, insbesondere wenn wir in unserer Datenbanktopologie ein automatisches Failover verwenden möchten.
Damit das Failover sowohl für den Benutzer als auch für die Anwendung transparent ist, benötigen wir eine Komponente dazwischen, da es nicht ausreicht, einen Master zu einem Slave zu machen. Dafür können wir HAProxy + Keepalived verwenden.
Was ist HAProxy?
HAProxy ist ein Load Balancer, der den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen verteilt und für diese Aufgabe spezifische Regeln und/oder Protokolle definieren kann. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an die restlichen verfügbaren Ziele gesendet. Dies verhindert, dass Datenverkehr an ein unzugängliches Ziel gesendet wird, und verhindert den Verlust dieses Datenverkehrs, indem er an ein gültiges Ziel geleitet wird.
Was ist Keepalived?
Mit Keepalived können Sie eine virtuelle IP innerhalb einer Aktiv/Passiv-Gruppe von Servern konfigurieren. Diese virtuelle IP wird einem aktiven „primären“ Server zugewiesen. Wenn dieser Server ausfällt, wird die IP automatisch auf den „sekundären“ Server migriert, der als passiv befunden wurde, sodass dieser auf für unsere Systeme transparente Weise mit derselben IP weiterarbeiten kann.
Um diese Lösung mit ClusterControl zu implementieren, haben wir so begonnen, als würden wir einen Slave hinzufügen. Gehen Sie zu Cluster Actions und wählen Sie Load Balancer hinzufügen (siehe Bild ClusterControl Add Slave 1).
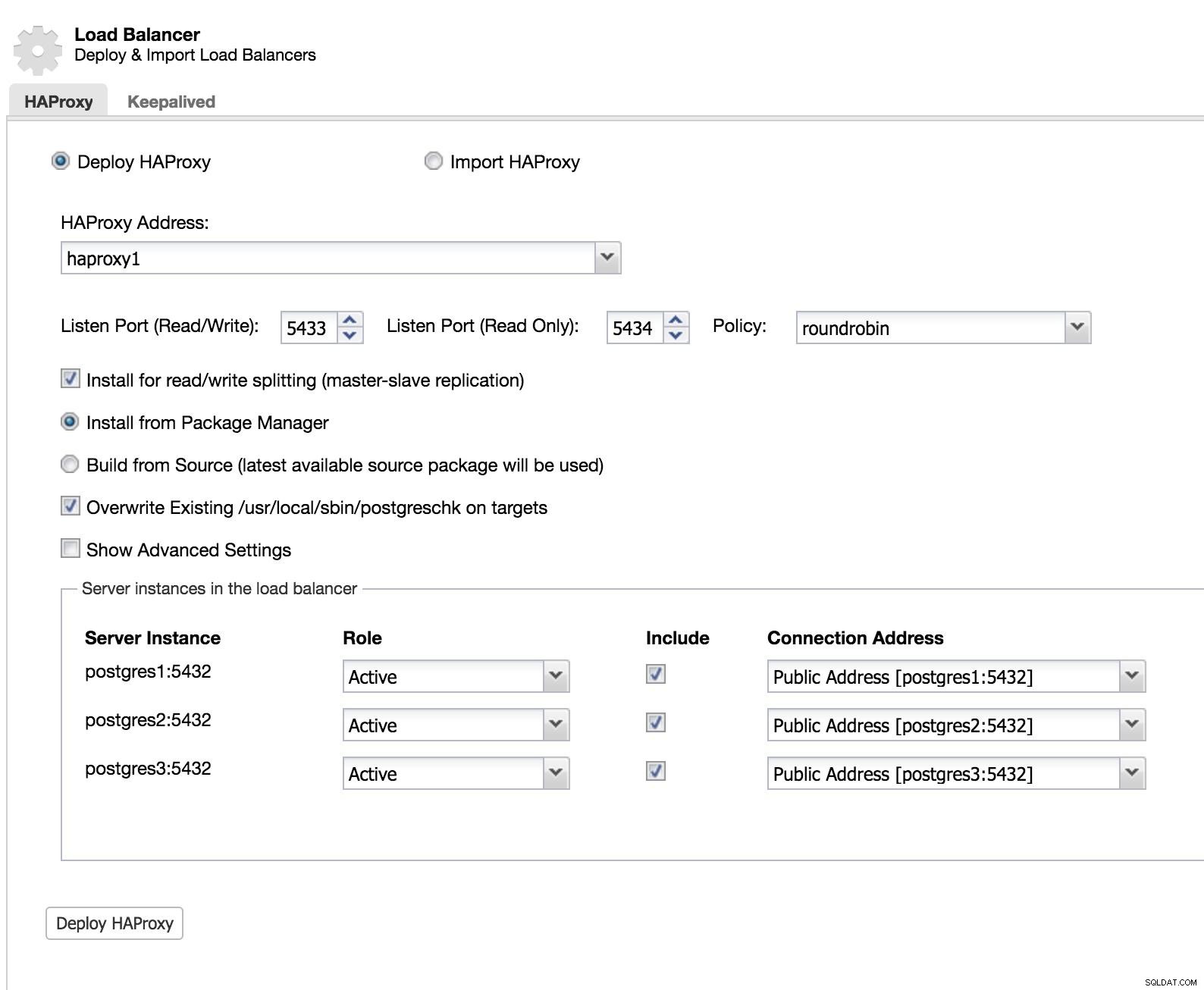 ClusterControl-Load-Balancer 1
ClusterControl-Load-Balancer 1 Wir fügen die Informationen unseres neuen Load Balancers hinzu und wie er sich verhalten soll (Richtlinie).
Falls wir Failover für unseren Load Balancer implementieren möchten, müssen wir mindestens zwei Instanzen konfigurieren.
Dann können wir Keepalived konfigurieren (Select Cluster -> Manage -> Load Balancer -> Keepalived).
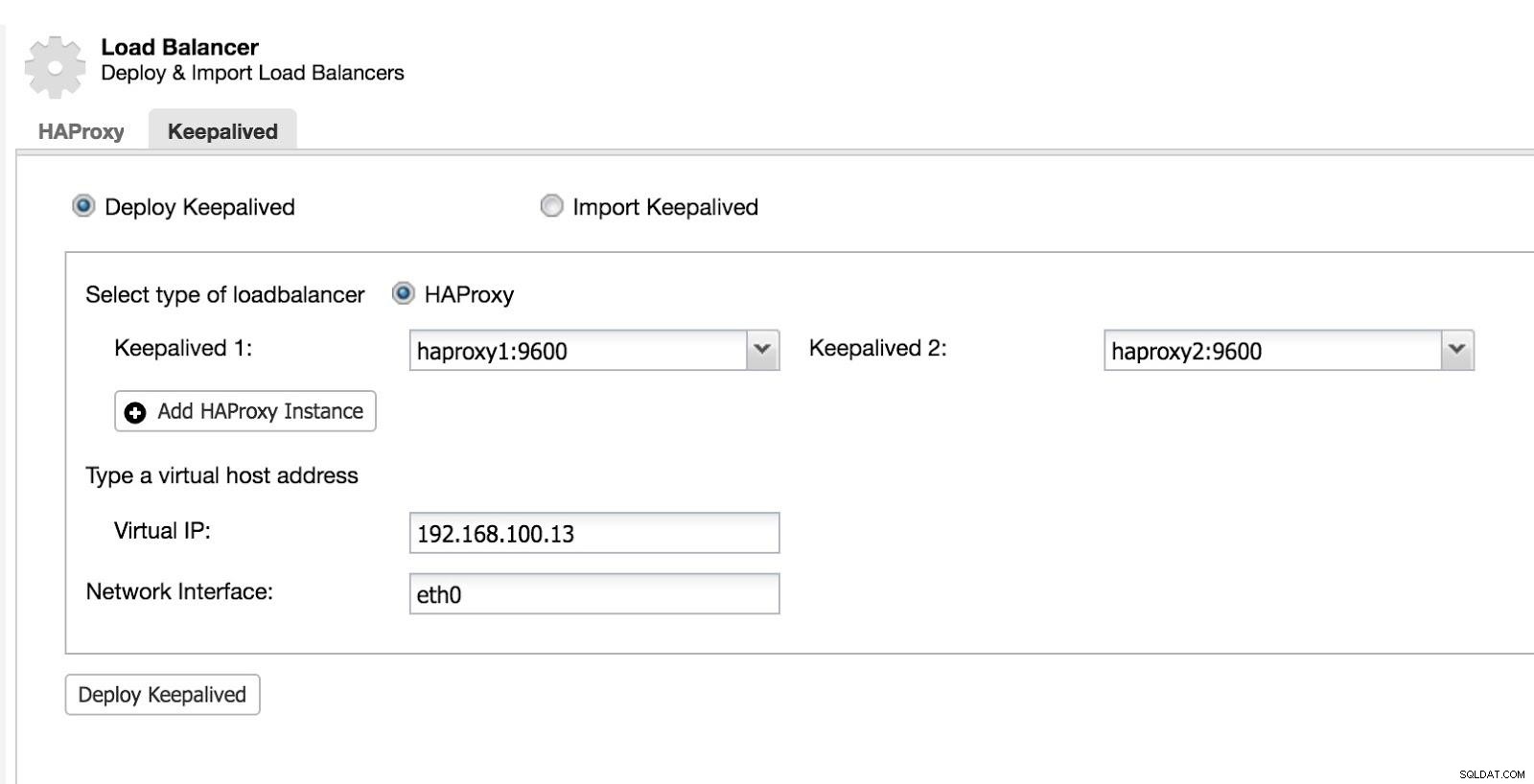 ClusterControl-Load-Balancer 2
ClusterControl-Load-Balancer 2 Danach haben wir die folgende Topologie:
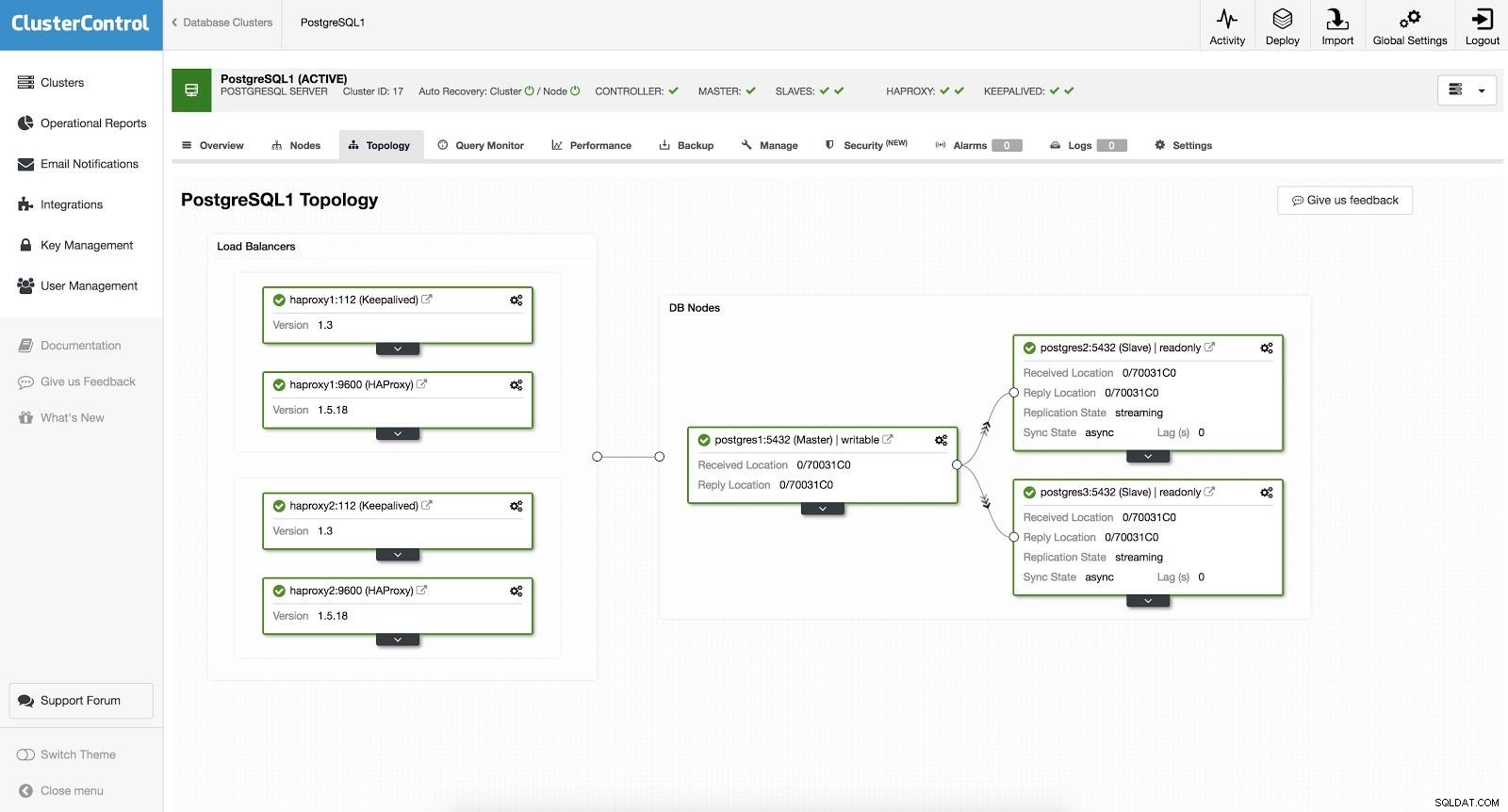 ClusterControl-Load-Balancer 3
ClusterControl-Load-Balancer 3 HAProxy ist mit zwei verschiedenen Ports konfiguriert, einem Read-Write und einem Read-Only.
In unserem Lese-Schreib-Port haben wir unseren Master-Server als online und den Rest unserer Knoten als offline. Im Nur-Lese-Port haben wir sowohl den Master als auch die Slaves online. Auf diese Weise können wir den Leseverkehr zwischen unseren Knoten ausgleichen. Beim Schreiben wird der Read-Write-Port verwendet, der auf den Master zeigt.
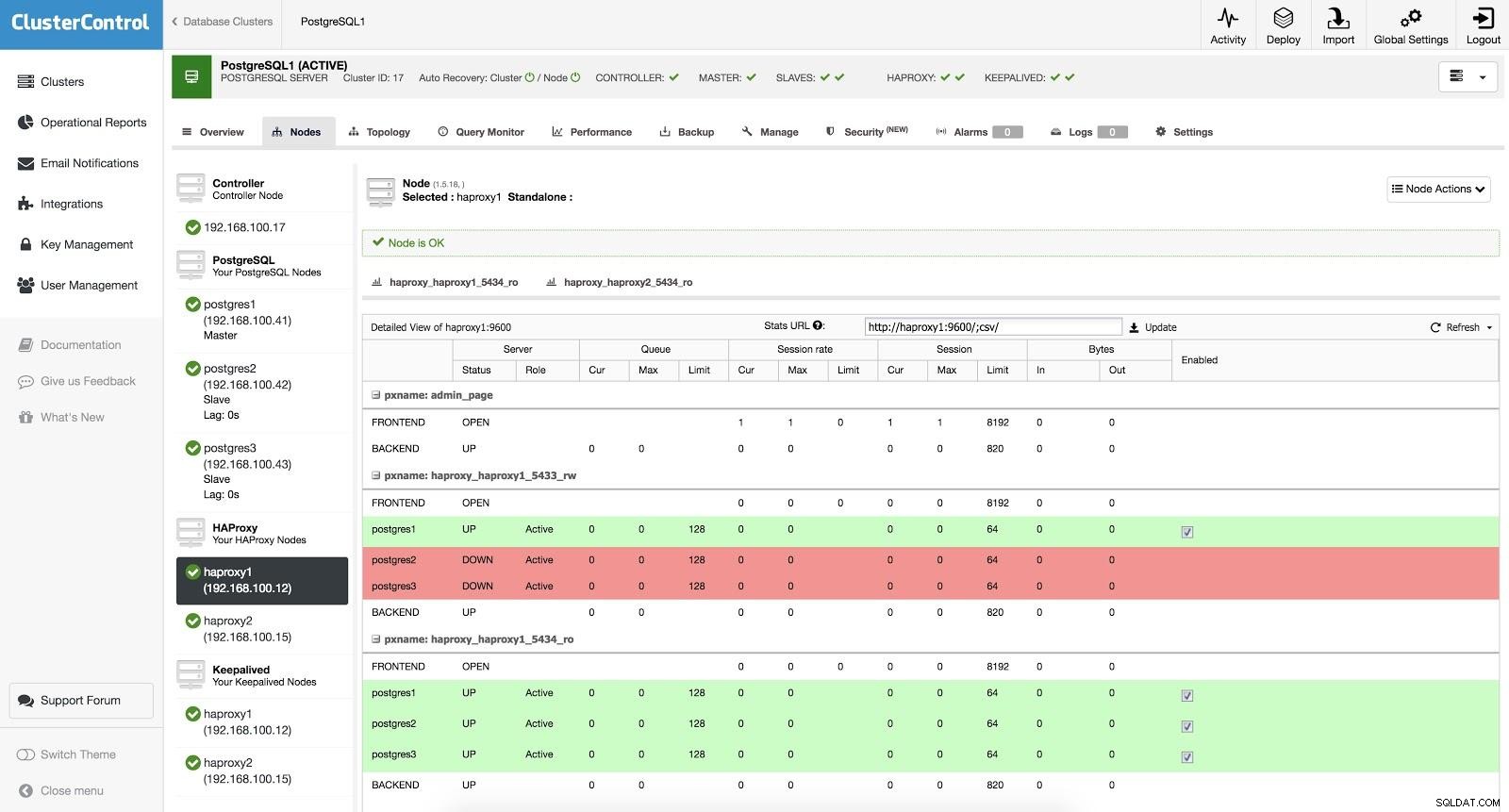 ClusterControl-Load-Balancer 3
ClusterControl-Load-Balancer 3 Wenn HAProxy erkennt, dass einer unserer Knoten, entweder Master oder Slave, nicht erreichbar ist, markiert es ihn automatisch als offline. HAProxy sendet keinen Datenverkehr an ihn. Diese Prüfung erfolgt durch Zustandsprüfungsskripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden. Diese prüfen, ob die Instanzen aktiv sind, ob sie gerade wiederhergestellt werden oder schreibgeschützt sind.
Wenn ClusterControl einen Slave zum Master befördert, markiert unser HAProxy den alten Master als offline (für beide Ports) und stellt den beförderten Knoten online (im Lese-Schreib-Port). Auf diese Weise funktionieren unsere Systeme weiterhin normal.
Wenn unser aktiver HAProxy (dem eine virtuelle IP-Adresse zugewiesen ist, mit der sich unsere Systeme verbinden) ausfällt, migriert Keepalived diese IP automatisch auf unseren passiven HAProxy. Das bedeutet, dass unsere Systeme dann normal weiter funktionieren können.
Schlussfolgerung
Wie wir sehen konnten, ist Failover ein grundlegender Bestandteil jeder Produktionsdatenbank. Es kann nützlich sein, wenn allgemeine Wartungsaufgaben oder Migrationen durchgeführt werden. Wir hoffen, dass dieser Blog als Einführung in das Thema hilfreich war, damit Sie weiter recherchieren und Ihre eigenen Failover-Strategien entwickeln können.