Mit zunehmender Größe von Datenbanktabellen und Indexen werden die Daten fragmentierter und die Antwort auf Abfragen verlangsamt sich. Um die Effizienz des Datenbankbetriebs zu verbessern, ist eine reguläre Tabellenreorganisation erforderlich. Sehen Sie sich diesen Artikel an, in dem erklärt wird, warum Reorgs wichtig sind, und das Material unten, in dem die Verwendung des Assistenten detailliert beschrieben wird.
Was es ist
IRI Workbench – eine Eclipse-IDE und -GUI für alle IRI-Softwareprodukte – bietet eine klassische (Offline-) Reorganisationslösung durch einen speziell entwickelten Assistenten. Der Offline-Reorg-Assistent erleichtert die Spezifikation und Ausführung mehrerer umfangreicher Reorgs, die große Tabellen in der Abfragereihenfolge (z. B. Verknüpfung) halten, ohne die Datenbank selbst zu belasten.
Funktionsweise
Der Offline-Reorganisationsassistent erstellt einen schrittweisen „Unload-Order-Reload“-Prozess für eine oder mehrere Tabellen gleichzeitig unter Verwendung von Bestandteilprodukten der IRI Data Manager-Suite. Für umfangreiche Reorgs gibt es die Konfiguration von:
an- IRI FACT für Massenentladungen von Tabellen
- IRI CoSort für ihre Nachbestellung
- das Ladedienstprogramm der Zieldatenbank für vorsortierte Massenladungen
ODBC-Auswahl- und -Einfügeoptionen sind auch für kleinere oder feiner abgestimmte Vorgänge verfügbar.
Am Ende des Assistenten werden die Jobskripts erstellt, die zum Reorganisieren der ausgewählten Tabellen erforderlich sind. Die Jobs können überall dort ausgeführt werden, wo die ausgewählten Tools lizenziert sind, und über die GUI, die Befehlszeile oder das Batch-Skript (das der Assistent ebenfalls erstellt) aufgerufen werden. Datenbankbenutzer sind von der Offline-Reorg-Methode nicht betroffen, obwohl Neuladen oder ODBC-Updates verwendete Tabellen ändern können.
So funktioniert es
Um den Offline-Reorg-Assistenten in IRI Workbench zu starten, navigieren Sie zur Dropdown-Liste im FACT-Menü und wählen Sie „Neuer Offline-Reorg-Job…“ aus.

Wählen Sie im ersten Dialogfeld den Projektordner aus und benennen Sie einen Unterordner für die Reorganisationsmetadaten und sortierten Ergebnisse. Geben Sie dann die Methode zum Abrufen (Entladen) und Neuauffüllen (Laden) der Tabelle an.

Als nächstes folgt die Phase der Datenextraktion (Entladen). Die verfügbaren Datenbankprofile können davon abhängen, was Sie auf der vorherigen Seite im Feld "Extraktion" ausgewählt haben. Wählen Sie die Datenbank aus der Verbindungsdatei und die Tabellen, die Sie reorganisieren möchten, aus den verfügbaren im Auswahlfenster aus:

Als Nächstes folgt die Datenladephase, in der Sie die Details der Zieltabelle angeben. Wählen Sie das Verbindungsprofil, Schemanamen und anwendbare Optionen für die Neuauffüllung (in diesem Fall über Oracle SQL*Loader). Klicken Sie auf „Fertig stellen“, um automatisch alle Skripts zu erstellen, die Sie zum Ausführen der Reorganisation(en) benötigen.

Dieser Prozess erzeugte die Dateien, die erforderlich sind, um nur die Tabelle JOB_TYPES automatisch offline zu reorganisieren. Die Skripts zum Entladen (FACT .ini), Sortieren (CoSort .scl) und Neuladen (Oracle .ctl) sowie Hilfsdateien werden zusammen mit dem Batch-Skript erstellt, das zum Ausführen des Ganzen erforderlich ist. Die .sql-Dateien behalten die Einschränkungen bei und die .flow-Datei unterstützt eine visuelle Darstellung des Workflows in einer separaten Ansicht.

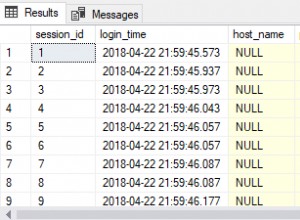
Wenn das Batch-Skript (FlowBatch.bat) ausgeführt wird, wird eine Tabelle mit den neu sortierten Daten zum Laden erstellt. Nachfolgend sehen Sie die Tabelle vor und nach der Reorganisation:

Die Anzahl der Elemente ist dieselbe, aber der Reorganisationsassistent hat die Tabelle standardmäßig nach ihrem Primärschlüssel sortiert. Sie können die Sortierschlüssel im .scl-Job (von Hand oder über die GUI) ändern, wenn Sie die Tabelle in einer anderen (Nachschlage-)Spalte neu ordnen möchten.
Wenden Sie sich an info@iri.com, wenn Sie Fragen zur Funktionsweise dieses Assistenten haben oder wenn Sie Zugriff auf eine Demo oder diese Komponenten des IRI Data Manager benötigen Suite.