Indizes sind Geschwindigkeits-Booster in SQL-Datenbanken. Sie können gruppiert oder nicht gruppiert sein. Aber was bedeutet es und wo sollten Sie es jeweils anwenden?
Ich kenne dieses Gefühl. Ich war dort. Anfänger sind oft verwirrt darüber, welcher Index für welche Spalten verwendet werden soll. Aber auch Experten müssen diese Frage durchdenken, bevor sie eine Entscheidung treffen, und unterschiedliche Situationen erfordern unterschiedliche Entscheidungen. Wie Sie später sehen werden, gibt es Abfragen, bei denen ein geclusterter Index im Vergleich zu einem nicht geclusterten Index glänzt und umgekehrt.
Aber zuerst müssen wir jeden von ihnen kennen. Wenn Sie nach denselben Informationen suchen, ist heute Ihr Glückstag.
In diesem Artikel erfahren Sie, was diese Indizes sind und wann Sie sie verwenden. Natürlich gibt es Codebeispiele, die Sie in der Praxis ausprobieren können. Schnappen Sie sich also Ihre Pommes oder Pizza und etwas Limonade oder Kaffee und machen Sie sich bereit, in diese aufschlussreiche Reise einzutauchen.
Bereit?
Was ist Clustered Index
Ein Clustered-Index ist ein Index, der die physische Sortierreihenfolge von Zeilen in einer Tabelle oder Ansicht definiert.
Um dies in der tatsächlichen Form zu sehen, nehmen wir den Mitarbeiter Tabelle in AdventureWorks2017 Datenbank.
Der Primärschlüssel ist ebenfalls ein gruppierter Index und der Schlüssel basiert auf der BusinessEntityID Säule. Wenn Sie ein SELECT für diese Tabelle ohne ORDER BY ausführen, werden Sie sehen, dass sie nach dem Primärschlüssel sortiert ist.
Probieren Sie es selbst mit dem folgenden Code aus:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Sehen Sie sich nun das Ergebnis in Abbildung 1 an:
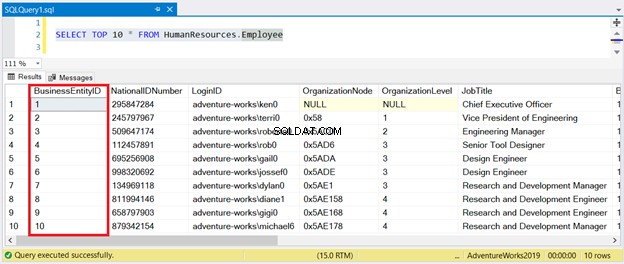
Wie Sie sehen, müssen Sie die Ergebnismenge nicht nach BusinessEntityID sortieren . Dafür sorgt der Clustered Index.
Im Gegensatz zu nicht gruppierten Indizes können Sie nur einen gruppierten Index pro Tabelle haben. Was, wenn wir das am Mitarbeiter versuchen Tabelle?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Wir haben unten einen ähnlichen Fehler:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Wann sollte ein gruppierter Index verwendet werden?
Eine Spalte ist der beste Kandidat für einen gruppierten Index, wenn eine der folgenden Aussagen zutrifft:
- Es wird in einer großen Anzahl von Abfragen in der WHERE-Klausel und in Joins verwendet.
- Er wird als Fremdschlüssel für eine andere Tabelle und letztendlich für Joins verwendet.
- Eindeutige Spaltenwerte.
- Der Wert wird sich weniger wahrscheinlich ändern.
- Diese Spalte wird verwendet, um einen Wertebereich abzufragen. Operatoren wie>, <,>=, <=oder BETWEEN werden mit der Spalte in der WHERE-Klausel verwendet.
Aber gruppierte Indizes sind nicht gut, wenn die Spalte oder Spalten
- ändern sich häufig
- sind breite Schlüssel oder eine Kombination von Spalten mit einer großen Schlüssellänge.
Beispiele
Clustered-Indizes können mit T-SQL-Code oder einem beliebigen SQL Server-GUI-Tool erstellt werden. Sie können dies in T-SQL bei der Tabellenerstellung wie folgt tun:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Oder Sie können dies mit ALTER TABLE nach tun Erstellen der Tabelle ohne Clustered-Index:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Eine andere Möglichkeit ist die Verwendung von CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Eine weitere Alternative ist die Verwendung eines SQL Server-Tools wie SQL Server Management Studio oder dbForge Studio for SQL Server.
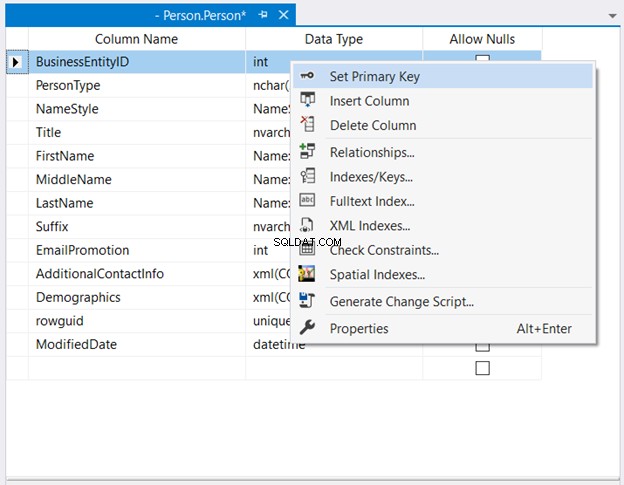
Im Objekt-Explorer , erweitern Sie die Datenbank- und Tabellenknoten. Klicken Sie dann mit der rechten Maustaste auf die gewünschte Tabelle und wählen Sie Design . Klicken Sie abschließend mit der rechten Maustaste auf die Spalte, die der Primärschlüssel sein soll> Primärschlüssel festlegen > Speichern Sie die Änderungen in der Tabelle.
Abbildung 2 unten zeigt, wo BusinessEntityID als Primärschlüssel gesetzt.
Neben der Erstellung eines einspaltigen Clustered-Index können Sie mehrere Spalten verwenden. Siehe ein Beispiel in T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Nach dem Erstellen dieses gruppierten Index wird die Person Tabelle wird physisch nach Nachname sortiert , Vorname und MiddleName .
Einer der Vorteile dieses Ansatzes ist die verbesserte Abfrageleistung basierend auf dem Namen. Außerdem sortiert es die Ergebnisse nach Namen, ohne ORDER BY anzugeben. Beachten Sie jedoch, dass bei einer Namensänderung die Tabelle neu angeordnet werden muss. Obwohl dies nicht jeden Tag vorkommt, kann die Wirkung enorm sein, wenn die Tabelle sehr groß ist.
Was ist ein nicht gruppierter Index
Ein nicht gruppierter Index ist ein Index mit einem Schlüssel und einem Zeiger auf die Zeilen oder die gruppierten Indexschlüssel. Dieser Index kann sowohl für Tabellen als auch für Ansichten gelten.
Im Gegensatz zu Clustered-Indizes ist hier die Struktur von der Tabelle getrennt. Da es separat ist, benötigt es einen Zeiger auf die Tabellenzeilen, der auch als Zeilenlokator bezeichnet wird. Somit enthält jeder Eintrag in einem nicht gruppierten Index einen Lokator und einen Schlüsselwert.
Non-Clustered-Indizes sortieren die Tabelle nicht physisch basierend auf dem Schlüssel.
Indexschlüssel für nicht gruppierte Indizes haben eine maximale Größe von 1700 Byte. Sie können dieses Limit umgehen, indem Sie eingeschlossene Spalten hinzufügen. Diese Methode ist gut, wenn Ihre Abfrage mehr Spalten abdecken muss, ohne die Schlüsselgröße zu erhöhen.
Sie können auch gefilterte nicht gruppierte Indizes erstellen. Dadurch werden die Wartungskosten und der Speicherplatz für den Index reduziert und gleichzeitig die Abfrageleistung verbessert.
Wann sollte ein nicht geclusterter Index verwendet werden?
Eine oder mehrere Spalten sind gute Kandidaten für nicht gruppierte Indizes, wenn Folgendes zutrifft:
- Die Spalte oder Spalten werden in einer WHERE-Klausel oder einem Join verwendet.
- Die Abfrage gibt keine große Ergebnismenge zurück.
- Die genaue Übereinstimmung in der WHERE-Klausel mit dem Gleichheitsoperator ist erforderlich.
Beispiele
Dieser Befehl erstellt einen eindeutigen, nicht geclusterten Index im Employee Tabelle:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Abgesehen von einer Tabelle können Sie einen nicht geclusterten Index für eine Ansicht erstellen:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Andere häufig gestellte Fragen und befriedigende Antworten
Was sind die Unterschiede zwischen geclustertem und nicht geclustertem Index?
Aus dem, was Sie zuvor gesehen haben, können Sie sich bereits eine Vorstellung davon machen, wie unterschiedlich Clustered- und Non-Clustered-Indizes sind. Aber lassen Sie es uns zum einfachen Nachschlagen auf einem Tisch haben.
| Info | Clustered-Index | Nicht gruppierter Index |
| Gilt für | Tabellen und Ansichten | Tabellen und Ansichten |
| Erlaubt pro Tisch | 1 | 999 |
| Schlüsselgröße | 900 Byte | 1700 Byte |
| Spalten pro Indexschlüssel | 32 | 32 |
| Gut für | Bereichsabfragen (>,<,>=, <=, BETWEEN) | Genaue Übereinstimmungen (=) |
| Nicht im Schlüssel enthaltene Spalten | Nicht erlaubt | Erlaubt |
| Filtern mit Bedingung | Nicht erlaubt | Erlaubt |
Sollten Primärschlüssel geclusterte oder nicht geclusterte Indizes sein?
Ein Primärschlüssel ist eine Einschränkung. Sobald Sie eine Spalte zu einem Primärschlüssel machen, wird daraus automatisch ein Clustered-Index erstellt, sofern nicht bereits ein Clustered-Index vorhanden ist.
Verwechseln Sie einen Primärschlüssel nicht mit einem Clustered-Index! Ein Primärschlüssel kann auch der Clustered-Index-Schlüssel sein. Ein Clustered-Index-Schlüssel kann jedoch eine andere Spalte als der Primärschlüssel sein.
Nehmen wir ein anderes Beispiel. In der Person Tabelle von AdventureWorks201 7 haben wir die BusinessEntityID Primärschlüssel. Es ist auch der gruppierte Indexschlüssel. Sie können diesen gruppierten Index löschen. Erstellen Sie dann einen gruppierten Index basierend auf Nachname , Vorname , und Mittelname . Der Primärschlüssel ist immer noch die BusinessEntityID Spalte.
Aber sollten Ihre Primärschlüssel immer geclustert werden?
Es hängt davon ab, ob. Sehen Sie sich noch einmal die Frage an, wann ein gruppierter Index verwendet werden sollte.
Wenn eine oder mehrere Spalten in Ihrer WHERE-Klausel in vielen Abfragen auftauchen, ist dies ein Kandidat für einen gruppierten Index. Aber eine weitere Überlegung ist, wie breit der gruppierte Indexschlüssel ist. Zu breit – und die Größe jedes nicht geclusterten Index wird zunehmen, falls vorhanden. Denken Sie daran, dass Non-Cluster-Indizes auch den Clustered-Index-Schlüssel als Zeiger verwenden. Halten Sie also Ihren gruppierten Indexschlüssel so schmal wie möglich.
Wenn eine große Anzahl von Abfragen den Primärschlüssel in der WHERE-Klausel verwendet, belassen Sie ihn auch als Clustered-Index-Schlüssel. Wenn nicht, erstellen Sie Ihren Primärschlüssel als nicht geclusterten Index.
Aber was ist, wenn Sie sich noch unsicher sind? Anschließend können Sie den Leistungsvorteil einer Spalte bewerten, wenn sie geclustert oder nicht geclustert ist. Schalten Sie also den nächsten Abschnitt darüber ein.
Was ist schneller:Clustered oder Non-Clustered Index?
Gute Frage. Es gibt keine allgemeine Regel. Sie müssen die logischen Lesevorgänge und den Ausführungsplan Ihrer Abfragen überprüfen.
Unser kurzes Experiment enthält Kopien der folgenden Tabellen aus AdventureWorks2017 Datenbank:
- Person
- BusinessEntityAddress
- Adresse
- Adresstyp
Hier ist das Skript:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Anhand der obigen Struktur vergleichen wir Abfragegeschwindigkeiten für geclusterte und nicht geclusterte Indizes.
Wir haben 2 Kopien der Person Tisch. Die erste verwendet BusinessEntityID als primärer und gruppierter Indexschlüssel. Die zweite verwendet immer noch BusinessEntityID als Primärschlüssel. Der gruppierte Index basiert auf Nachname , Vorname , Zwischenname , und Suffix .
Fangen wir an.
EXAKTE ÜBEREINSTIMMUNGEN BASIEREND AUF DEM NACHNAMEN ABFRAGEN
Lassen Sie uns zunächst eine einfache Abfrage durchführen. Außerdem müssen Sie STATISTICS IO aktivieren. Dann fügen wir die Ergebnisse für eine tabellarische Darstellung in statisticsparser.com ein.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Die Erwartung ist, dass das erste SELECT langsamer sein wird, da die WHERE-Klausel nicht mit dem Clustered-Index-Schlüssel übereinstimmt. Aber lassen Sie uns die logischen Lesevorgänge überprüfen.
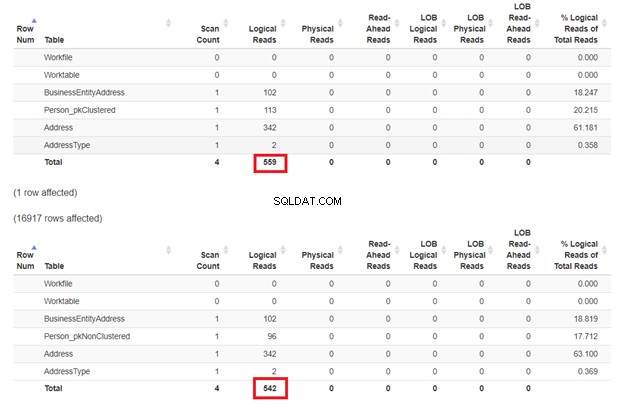
Wie in Abbildung 3 erwartet, Person_pkClustered hatte mehr logische Lesevorgänge. Daher benötigt die Abfrage mehr E/A. Der Grund? Die Tabelle ist nach BusinessEntityID sortiert . Die zweite Tabelle hat jedoch den gruppierten Index basierend auf dem Namen. Da die Abfrage ein Ergebnis basierend auf dem Namen Person_pkNonClustered möchte Gewinnt. Je weniger logische Lesevorgänge, desto schneller die Abfrage.
Was ist sonst noch los? Sehen Sie sich Abbildung 4 an.
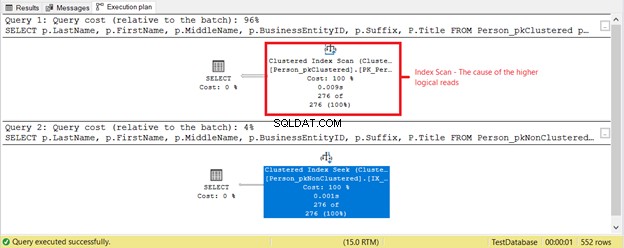
Basierend auf dem Ausführungsplan in Abbildung 4 ist etwas anderes passiert. Warum ist ein Clustered Index Scan im ersten SELECT anstelle eines Index Seek? Schuld daran ist der Titel Spalte in der SELECT. Es wird von keinem der bestehenden Indizes abgedeckt. Der SQL Server-Optimierer hielt es für schneller, den gruppierten Index basierend auf BusinessEntityID. zu verwenden Dann durchsuchte SQL Server es nach den richtigen Nachnamen und erhielt den Vornamen, den zweiten Vornamen und den Titel.
Entfernen Sie den Titel -Spalte, und der verwendete Operator ist Index Seek . Wieso den? Weil der Rest der Felder durch den nicht geclusterten Index basierend auf Nachname abgedeckt wird , Vorname , Zwischenname , und Suffix . Es enthält auch BusinessEntityID als Clustered-Index-Key-Locator.
BEREICHSABFRAGE BASIEREND AUF DER ID DER GESCHÄFTSEINHEIT
Clustered-Indizes können gut für Bereichsabfragen sein. Ist das immer so? Finden wir es heraus, indem wir den folgenden Code verwenden.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Die Auflistung benötigt Zeilen, die auf einer Reihe von BusinessEntityIDs basieren von 285 bis 290. Auch hier sind die gruppierten und nicht gruppierten Indizes der 2 Tabellen intakt. Sehen wir uns nun die logischen Lesevorgänge in Abbildung 5 an. Der erwartete Gewinner ist Person_pkClustered da der Primärschlüssel auch der Clustered-Index-Schlüssel ist.

Sehen Sie weniger logische Lesevorgänge auf Person_pkClustered ? Clustered-Indizes haben sich in diesem Szenario bei Bereichsabfragen bewährt. Sehen wir uns an, was der Ausführungsplan in Abbildung 6 noch enthüllt.
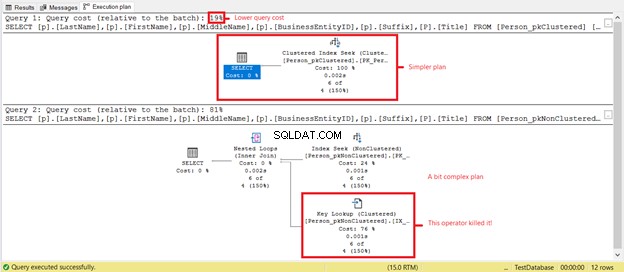
Das erste SELECT hat einen einfacheren Plan und niedrigere Abfragekosten, basierend auf Abbildung 7. Dies unterstützt auch weniger logische Lesevorgänge. In der Zwischenzeit hat das zweite SELECT einen Key-Lookup-Operator, der die Abfrage verlangsamt. Der Täter? Auch hier ist es der Titel Säule. Entfernen Sie die Spalte in der Abfrage oder fügen Sie sie als eingeschlossene Spalte im nicht gruppierten Index hinzu. Dann haben Sie einen besseren Plan und weniger logische Lesevorgänge.
EXAKTE ÜBEREINSTIMMUNGEN MIT EINEM JOIN ABFRAGEN
Viele SELECT-Anweisungen enthalten Joins. Lass uns ein paar Tests machen. Hier beginnen wir mit exakten Übereinstimmungen:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Wir erwarten, dass das zweite SELECT von Person_pkNonClustered mit einem gruppierten Index für den Namen haben weniger logische Lesevorgänge. Aber ist es? Siehe Abbildung 7.
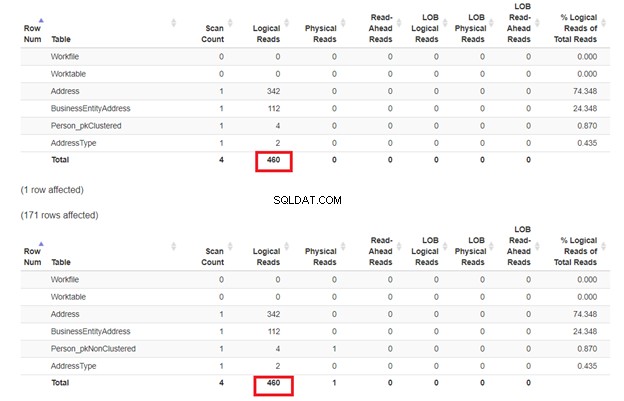
Sieht so aus, als ob der nicht gruppierte Index für den Namen gut funktioniert hat. Die logischen Lesevorgänge sind die gleichen. Wenn Sie den Ausführungsplan überprüfen, ist der Unterschied in den Operatoren der Clustered Index Seek auf Person_pkNonClustered , und die Indexsuche auf Person_pkClustered .
Daher müssen wir die logischen Lesevorgänge und den Ausführungsplan überprüfen, um sicherzugehen.
BEREICHSABFRAGE MIT JOINS
Da unsere Erwartungen von der Realität abweichen können, versuchen wir es mit Bereichsabfragen. Clustered-Indizes sind im Allgemeinen gut damit. Aber was ist, wenn Sie einen Join einfügen?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Untersuchen Sie nun die logischen Lesevorgänge dieser beiden Abfragen in Abbildung 8:
Was passiert ist? In Abbildung 9 beißt die Realität bei Person_pkClustered . Im Vergleich zu Person_pkNonClustered wurden darin höhere E/A-Kosten beobachtet . Das ist anders, als wir erwarten. Aber basierend auf dieser Forumsantwort kann eine nicht geclusterte Indexsuche schneller sein als eine geclusterte Indexsuche, wenn alle Spalten in der Abfrage zu 100 % im Index abgedeckt sind. In unserem Fall die Abfrage für Person_pkNonClustered die Spalten mit dem nicht geclusterten Index (BusinessEntityID) abgedeckt - Schlüssel; Nachname , Vorname , Zwischenname , Suffix – Zeiger auf Clustered-Index-Schlüssel).
LEISTUNG EINFÜGEN
Versuchen Sie dann, die INSERT-Leistung über dieselben Tabellen zu testen.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Abbildung 9 zeigt die logischen INSERT-Lesevorgänge:

Beide generierten die gleiche E/A. Somit haben beide die gleiche Leistung erbracht.
LEISTUNG LÖSCHEN
Unser letzter Test beinhaltet DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Abbildung 10 zeigt die logischen Lesevorgänge. Beachten Sie den Unterschied.

Warum haben wir höhere logische Lesezugriffe auf Person_pkClustered ? Die Sache ist die, dass die Bedingung der DELETE-Anweisung auf einer exakten Namensübereinstimmung basiert. Der Optimierer muss zuerst auf den nicht gruppierten Index zurückgreifen. Das bedeutet mehr E/A. Lassen Sie uns anhand des Ausführungsplans in Abbildung 11 bestätigen.
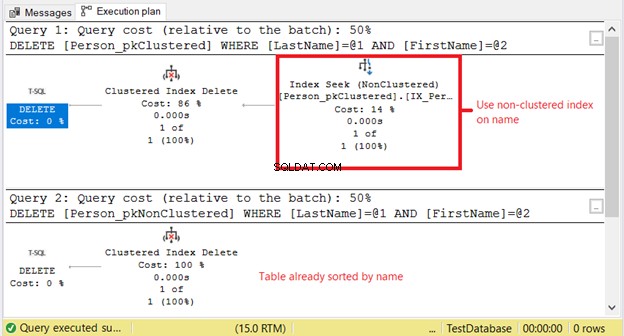
Das erste SELECT benötigt eine Indexsuche für den nicht gruppierten Index. Der Grund ist die WHERE-Klausel auf Nachname und Vorname . Inzwischen Person_pkNonClustered ist aufgrund des Clustered Index bereits physikalisch nach Namen sortiert.
Imbiss
Das Erstellen leistungsstarker Abfragen hat nichts mit Glück zu tun. Sie können nicht einfach einen geclusterten und einen nicht geclusterten Index setzen und dann haben Ihre Abfragen plötzlich die Geschwindigkeitskraft. Sie müssen die Tools weiterhin als Objektiv verwenden, um sich auf die kleinen Details außer dem Ergebnissatz zu konzentrieren.
Aber manchmal hat man einfach keine Zeit, all dies zu tun. Ich denke, das ist normal. Aber solange du nicht so viel vermasselst, hast du am nächsten Tag deinen Job und kannst es schaffen. Das wird anfangs nicht einfach. Es wird tatsächlich verwirrend sein. Sie werden auch viele Fragen haben. Aber mit ständiger Übung können Sie es erreichen. Also, Kopf hoch.
Denken Sie daran, dass sowohl geclusterte als auch nicht geclusterte Indizes dazu dienen, Abfragen zu verstärken. Die Kenntnis der Hauptunterschiede, der Verwendungsszenarien und der Tools wird Ihnen bei Ihrer Suche nach der Codierung von Hochleistungsabfragen helfen.
Ich hoffe, dass dieser Beitrag Ihre dringendsten Fragen zu geclusterten und nicht geclusterten Indizes beantwortet. Haben Sie unseren Lesern noch etwas hinzuzufügen? Der Kommentarbereich ist geöffnet.
Und wenn Sie diesen Beitrag aufschlussreich finden, teilen Sie ihn bitte auf Ihren bevorzugten Social-Media-Plattformen.
Weitere Informationen zu Indizes und Abfrageleistung finden Sie in den folgenden Artikeln:
- 22 raffinierte SQL-Indexbeispiele, um Ihre Abfragen zu beschleunigen
- SQL-Abfrageoptimierung:5 Kernfakten zur Steigerung Ihrer Abfragen